Intel漏洞回顾(一)
Intel漏洞回顾(一)
作者:maccoray
目录
漏洞背景
幽灵原理
漏洞背景
在今年(2018)的一月初,google的安全团队Project Zero在网路上发布了两则公告
Reading privilegedmemory with a side-channel
Today's CPUvulnerability: what you need to know
这两则公告基本可以用撼动世界来说明它的威力,因为它所叙述的漏洞,基本上涵盖了所有当下流行的CPU类型,以及波及正在流行的云计算虚拟化方案。漏洞分为“幽灵”和“熔断”,因为文中对于两者的区分比较含糊,一笔带过,因此业界对于两者的区别也争论不休。在我粗俗的见解里面,幽灵和熔断都使用了一种基础技术,“预测旁路”。而“熔断”是“幽灵”应用版升级而已,“幽灵”解决了预测分支的准确执行,从而可以读出“越界地址”的数据内容,基本上没有办法实现跨进程“盗窃”。而“熔断”使用了“幽灵”的特色,加对于“操作系统”原理的认知,逆向,从而实现了“盗窃”的跨进程作案,也就是说漏洞升级为“熔断”后,它有了真正的应用场景。
当然以上也是我个人的解读,有不妥之处,还望和大家讨论。
幽灵原理
随着google把Paul Kocher等人的文章Spectre Attacks: Exploiting Speculative Execution纰漏,幽灵的POC代码也一同发布给了公众,大家可以到文章结尾的附件中下载原文PDF。通过幽灵可以实现单一进程内的“越界访问”,利用了intel等芯片厂商底层最最引以为荣的“分支预测”功能。
而为了解释清楚这个在芯片厂商手册里面一笔带过的“分支预测”功能,不管是google的Project Zero(初号工程团队),还是Paul本人都做了大量“晦涩”,“深奥”的猜测。当然这些猜测都被实验证实“正确”,当然是否“准确”还有待芯片厂商的“微代码级别开源”,虽然这个可能性不高。
通读完两个文章的相关章节后,我试图用一种简明的方法来讲述幽灵的原理,希望没有漏掉太多的细节。推荐大家的阅读方法是,迅速的看完我的文章后,转而用批判,研读的态度,去阅读附件中的两篇原版英文,最后转回来抨击我文章中的不正确观点,欢迎指正和讨论。因为这两篇文章在“CPU微码没有开源”的前题下,还有很多讨论空间,真理越辩越清晰嘛。也采用一种正常“逻辑”来展示这个原理,因为老外的两篇文章混杂了“应用场景”,“猜想”和“原理”,在我看有点杂。
BTB
branch target buffer,这是第一个Paul Kocher关于CPU微码分支预测的猜想,是Google工程师对于Paul Kocher文章的解读。Paul做了一个实验,他去跟踪CPU做“分支预测”时,加载的到缓冲区中数据的地址,他发现有个特质:CPU执行“缓冲区加载”的地址并非一个绝对地址,而是一个通过XOR的相对地址。也就是说,当CPU去执行到要加载某个Source Address的时候,它会去做两件事情
1.把这个Source Address中的数据加入缓冲区
2.把这个Source Address传给一个叫做BTB的缓冲管理器
第一件事情很好理解,这里就不说了。第二件事情就关乎“分支预测”的特质,为什么要做第二步呢?我猜源自于两个外文中都没有提及的一个原因“CPU设计者不希望CPU缓冲空着”,所以CPU做了第二步,把Source Address给到BTB,试图叫BTB给它一个“即将用到”数据的地址“Destination Address”,方便CPU把它加载到缓冲里面,以便后来之需(这会加速CPU的运行效率)。整个过程还算合理,但是CPU的设计者应该是为了兼容“后续一个设计”,他做了大胆的裁剪,也就是前面提到的,BTB中存储一个“阉割”后的地址以及一些XOR的参数,通过某种高深的算法,既可以大概率恢复“一对一的DestinationAddress”,又可以为将来的设计铺路。
这个“阉割”地址的怎么来理解呢,如下图这样,CPU设计者认为Source Address的高位地址变化不大,而低位地址至关重要,因此会把高12位地址忽略,直接透传给Destination Address地址。而低位地址和Destination Address的对应关系,通过某几次的运行,得出了一种XOR的算法模型,数次XOR就可以得到个尾数,并且将拼接上刚才透传过来的Source Address的高位地址,就得到了本次要丢给CPU的“预测后”Destination Address。所以在这个设想下的假想下的推理是,如果有两个地址,它们的低位地址是一样的比如“0x4141.(0004.1000)和0x4242.( 0004.1000)”,那么它们就会走相同的BTB逻辑,造成0x4242.( 0004.1000)虽然是首次通过CPU的运算,一样也会叫CPU做0x4242.(0000.5123)地址的“预测”数据加载。

实验做到这一步Paul当时应该非常兴奋,因为只要构造一系列“高位地址不同,低位地址相同”的Source Address,就可以读“任意地址的数据”到缓冲里啦。在加一个巧妙时间差计算(被缓冲的地址加载会快于未被缓冲的地址)的技巧,就可以推导出“任意地址的数据”内容了。但是这个POC成功率只有1%。这个冷水泼的有点大,造成Paul的文章一度被冷冻了半年之久(因为以上的这些推断,早在2017年Paul就把它公之于众了,但是到2018年初,google才开始歌颂这个漏洞)。
BHB
branch history buffer这是第二个Paul Kocher关于CPU微码分支预测的猜想,是Google工程师对于Paul Kocher文章的解读。BHB应该就是上面一个小结所说的,CPU设计者的“后续一个设计”。CPU设计者在发明了BTB之后敏捷的发现,在CPU上运行的代码,多数采用“间接寻址”进行数据加载,也就是类似“mov ecx,[ebx]”(我自己加入,方便理解,英文原版喜欢用jump,后文将述说这里的原因,至于语法是否正确或者是否得体,读者可以讨论)这样。那么Source Address被放在一个寄存器里,不好读出来,怎么办?于是BHB就出现了,它用BTB里面的内容做首次输入,然后在用历史执行加载,做fingerprint来给到BHB推断出一个state来决定是否加载。估摸着这就是Paul Kocher之前做BTB后,POC成功率只有1%的原因。

简单的说现在流行的CPU都会把BTB的内容,当作首要参考,且常常被“间接调用所曲解”,且CPU设计者因为觉得直接调用“少之又少所以I don't care.”,而决定性的加载动作还是由BHB来做。所以现在就出来了两个幽灵最基础的算法要求:
1.构造地址,欺骗BTB
2.构造间接,欺骗BHB
结果Paul把两个条件都实现了,这样幽灵就诞生了,准确率非常高,99%。
POC代码分析
有了前面的原理介绍,这里就简单的过一下代码,这样更加清晰,源代码也放在文章的附件中,这里只是摘录某些重要细节:

这段被害者代码victim_function,在正常情况下它只会读取array1[0-15],因为array1_size也就是array1的长度是16。

而在分支预测错误的时候,就可以去越界访问到比如array1[16+]的地址,且只用array1[x]*512也对array2和temp构成了间接访问。
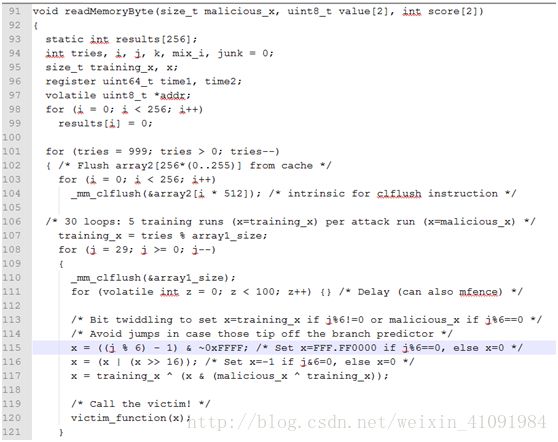
而真正的误导分支预测代码readmemory byte,它做了三件关键的事儿:
1.从CPU缓存中,清除当前程序马上要用到的变量,和影响后续判断的变量,array1_size,array2[i * 512],这会叫CPU面对后续的程序,出现一种无变量缓冲状态,使它计算效率下滑,且急于使用预测分支方式填充缓冲(个人理解,可以讨论)。
2.采用一段巧妙代码(就是代码中对for 100的空循环)来耗费CPU时钟。造成CPU对于这段代码需要缓冲变得更加急切,因为这中消耗命中了,一种原文中一笔带过的“预测时间窗口”speculation window,它大概是100个始终周期(然文中没有直白的介绍它,而是介绍了它的反向理解mis-speculation window。读者可以试着结合我的说法,重新阅读一下它看看是不是正确)。我的理解,如果CPU在做了一件耗费了100个始终周期且的事情后,准确的加载某个地址(前面提到的Destination Address)的数据到缓冲,经过多次折腾,那么CPU就开启了预测模式,它要预测加载数据到缓冲。
3. 第2件事儿中描述的“多次折腾”,就是接下来做的,在第30次执行的时候必定叫victim_function越界,而前面的29次,就Paul的测试结果来看,可以99%的欺骗BTB和BHB,造成在第30次的时候,CPU不管三七二十一,也要把越了界的array1[16+]读入缓冲。
当然我这里简单的说了“不管三七二十一”,但老外还是做了非常精细的逻辑推倒的,这里大家可以去看下原文,是29次怎么洗涤BHB状态的。怎么叫BHBforget之前的状态,且恰巧在第30次出现BHB判断无效的状态。读完我写的这段,在返回去看google的假设BHB更新代码,可能会更加清晰,如下贴图。

幽灵在服务器上运行
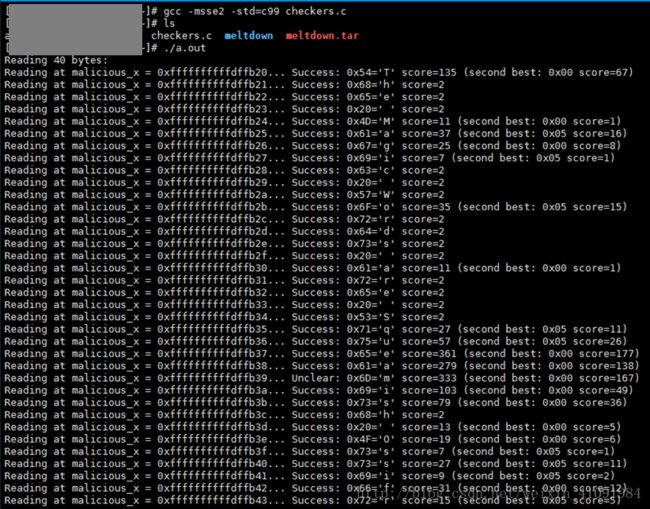
注:前文也提到过我用mov的汇编指令来帮助理解,而没有采用英文中多处使用的jump(放在正文中,没有用指令展示);在我看来这里有误导之意,可能想给CPU设计者暗示,分支可能具有控制jump的能力,想得到CPU设计者的正面反驳或者赞同,以便于做出0Day攻击脚本(因为不管是幽灵还是熔断都只是“只读”类型漏洞)。
下集预告
Intel漏洞回顾(二)
目录
熔断发布
服务器里测试
对策