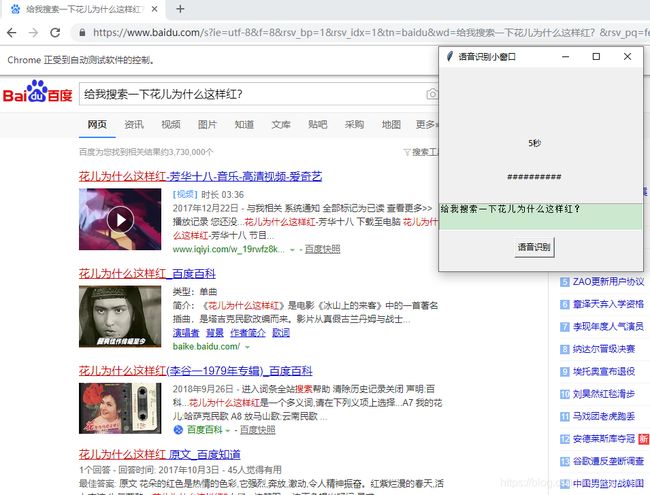
如何使用百度语音识别api将自己的电脑设置成听话的小助手(python)
工程链接:https://download.csdn.net/download/lidashent/11711069
电脑上自带的语音助手功能惨不忍睹,简直不能忍,于是自己写了一个语音助手
这里将使用python,调用百度语音识别api,为自己的电脑打造一个语音识别助手.
可以执行语音控制搜索,语音控制打开软件以及语音输入文字的操作,
一起来看看吧
所有的代码都经过模块化函数编写,可以单独调试,方便读者借鉴
acannda + pycharm 软件
首先,第一步,我们导入python需要的包文件,这些都是封装好的功能模块,我们直接使用就可以,具体包怎么安装的,建议去百度一下看看,因为工程比较大,这里不再讲安装方式
from aip import AipSpeech
import datetime
import wave
import pyaudio
import numpy
import threading
import win32api
import keyboard
import pygame
from tkinter import Label, Tk, Entry, Scrollbar, RIGHT, Text, LEFT, END, INSERT, Button, Toplevel, mainloop, Y, \
Radiobutton, IntVar
import pygame
from selenium import webdriver
import os
import time第二步,我们为这个软件创造一个界面,方便我们去控制它
这里使用的包是tkinter模块,我们已经引入了
root=Tk()
frame1=(root)
frame1.geometry('300x300')
frame1.title("语音识别小窗口")
seconds__text_my1 = Text(frame1)
seconds__text_my1.place(x=0, y=220, anchor='w', height=40, width=300)第三步,我们已经有了界面了,那么我们看看如何创建语音识别的,
我们的目的是得到我们语音的识别文字,那么可以这样想,
我们分成两步走:
第一小步,得到我们的录音文件
第二小步,将录音文件导入百度语音识别api接口中,得到我们想要的识别文字
那么我们先看看如何得到录音文件:
def record_voice(time_long):
voice_button.configure(state='disable')
DATA_CHUNK=1024
FORMAT_VOICE=pyaudio.paInt16
CHANNELS_SINGLE=1
DATA_RATE=16000
MY_SECONDES=time_long
MY_FILENAME="D:/temp_record_voice.wav"
my_pyaudio=pyaudio.PyAudio()
stream=my_pyaudio.open(format=FORMAT_VOICE,channels=CHANNELS_SINGLE,rate=DATA_RATE,input=True,frames_per_buffer=DATA_CHUNK)
print("录音开始了")
voice_data_chunk=[]
display_second = 0
now_time = datetime.datetime.now()
for i in range(0, int(DATA_RATE / DATA_CHUNK * MY_SECONDES)):
next_time = datetime.datetime.now()
temp_time = next_time - now_time
if (temp_time.total_seconds() - 1 > 0):
now_time = datetime.datetime.now()
display_second = display_second + 1
seconds_lable=Label(frame1, text=str(display_second) + "秒") # 按下按钮
seconds_lable.place(x=140, y=100, anchor='n')
haha='#'*2*display_second
wave_lable = Label(frame1, text=haha) # 按下按钮
wave_lable.place(x=140, y=150, anchor='n')
print(str(display_second) + "秒")
data = stream.read(DATA_CHUNK)
voice_data_chunk.append(data)
print("录音结束")
stream.stop_stream()
stream.close()
my_pyaudio.terminate()
voice_file=wave.open(MY_FILENAME,"wb")
voice_file.setnchannels(CHANNELS_SINGLE)
voice_file.setsampwidth(my_pyaudio.get_sample_size(FORMAT_VOICE))
voice_file.setframerate(DATA_RATE)
voice_file.writeframes(b''.join(voice_data_chunk))
voice_file.close()承接上一次的代码,我们来通过录音文件,获得语音识别后的文字:
def use_api_get_text():
APP_ID = '*****'#去百度开发者中心申请语音识别接口
API_KEY = '******'
SECRET_KEY = '******'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
get_voice_file=open("D:/temp_record_voice.wav","rb")
voice_text=get_voice_file.read()
result = client.asr(voice_text, 'wav', 16000, {'dev_pid': '1936', })
print(result)
if result['err_no'] == 0:
content_my=result['result'][0]
print(result['result'][0])
send = content_my
haha = content_my
seconds__text_my1.delete('1.0', 'end')
seconds__text_my1.insert(INSERT, content_my)
do_my_thought(content_my)
else:
content_my="err_no:" + str(result['err_no'])
print("err_no:" + str(result['err_no']))
seconds__text_my1.delete('1.0', 'end')
seconds__text_my1.insert(INSERT, '识别失败')
voice_button.configure(state='normal')第五步:上面的工作,我们创建了界面,有了录音,有了录音识别后的文字,
那么接下来我们拿到这些文字后进行特征分析,就会得到我们想要的结果
比如我想让电脑自动给我在浏览器上搜索东西,那么识别特征文字('搜索'),执行我们想要的功能就可以了,
举个栗子,我这里先写让浏览器自动搜索的代码:
这里以浏览器为例,里面的文件路径 是浏览器的驱动,网上,有很多链接下载的,
def open_chorme(content_get):
chromedriver = "C:\\Users\\Administrator\\Desktop\\The_file_of_home\\new_folder\chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
driver.get("https://www.baidu.com/")
print("access to %s " % ('百度'))
driver.find_element_by_id("kw").send_keys(content_get)
driver.find_element_by_id("su").click()
driver.maximize_window()上面写好了一个让浏览器自动搜索的方法,那么我们进行文本分析判断来调用他
看到那个win32api了吗?
通过那条命令,我们能用电脑默认的方式打开路径里面的东西,也就是说如果我说的话中有'手写'这个关键字,他就会打开我们需要的软件,搜索同理
def do_my_thought(content_my):
if content_my.find("手写") > 0:
win32api.ShellExecute(0, 'open', 'C:\\Users\\Administrator\\Downloads\\Baidu Net Disk Downloads\\桌面粉笔[1.5].exe', '', '', 0)
elif content_my.find("搜索") > 0:
open_chorme(content_my)
else :
play_sentence('你的主人制造你时,好像有偷工减料哎')
第七步,大体框架已经搭建好了,我们有了界面,有了语音,有了语音识别后的文字,有了根据特殊字执行的功能函数,
那么接下来我们做一个文字转声音的工具,也使用百度api,让整个软件看起来智能一点.
这个功能主要用于软件的说话应答,我们不希望他回应的沉默,
我们需要让软件说话
def play_sentence(myword):
if myword:
lan = myword
APP_ID = '*****' # 引号之间填写之前在百度api语音接口平台上申请的参数
API_KEY = '*********' # 如上
SECRET_KEY = '*******' # 如上
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis(lan, 'zh', 1, {'vol': 5, 'per': 4, 'spd': 5})
'''
固定值zh。语言选择,目前只有中英文混合模式,填写固定值zh
客户端类型选择,web端填写固定值1
spd语速,取值0-15,默认为5中语速(选填)
pit音调,取值0-15,默认为5中语调(选填)
vol音量,取值0-15,默认为5中音量(选填)
per发音人选择, 0为普通女声,1为普通男生,3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女声
'''
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('C:\\Users\\Administrator\\Desktop\\my_music\\reminder\\a.mp3', 'wb') as f:
f.write(result)
win32api.ShellExecute(0, 'open', 'C:\\Users\\Administrator\\Desktop\\my_music\\reminder\\a.mp3', '', '', 0)第八步,至此,一个比较好的软件框架已经搭建好了,那么我们来做一个善后工作,
当然是调用主函数啊,主函数调用他们,不然他们怎么执行.....
def do_that():
try:
record_voice(6)
use_api_get_text()
except:
print("终止了")
win32api.ShellExecute(0, 'open', 'C:\\Users\\Administrator\\Desktop\\my_music\\reminder\\b.mp3', '', '', 0
def new_thread_voice():
s = threading.Thread(target=do_that)
s.start(
voice_button= Button(frame1, text="语音识别", command=new_thread_voice) # 按下按钮
voice_button.place(x=140, y=250, anchor='n')
mainloop()
到这里已经写好了,放张图片养养眼