Re-ID:AlignedReID: Surpassing Human-Level Performance in Person Re-Identification 论文解析
刚读完这篇文章,贼6,用动态规划求最小路径进行特征对齐,很新奇,而且准确率很高。
下面是我对这篇论文的一个整理~
- 这篇文章作者提出了AlignedReID的方法,其亮点在于:在数据集Market1501与CUHK03上,该方法实现的rank-1 accuracy 首超人类,
- 作者认为:
- Traditional approaches have focused on low-level features such as colors, shapes, and local descriptors. With the renaissance of deep learning, the convolutional neural network (CNN) has dominated this field.
- 传统的方法大多采用CNN提取低级别的特征。
- Many CNN-based approaches learn a global feature, without considering the spatial structure of the person. This has a few major drawbacks:
- inaccurate person detection boxes might impact feature learning.
- the pose change or non-rigid body deformation makes the metric learning difficult.
- occluded parts of the human body might introduce irrelevant context into the learned feature.
- it is non-trivial to emphasis local differences in a global feature, especially when we have to distinguish two people with very similar apperances.
- 许多基于CNN的方法只学习了全局的特征,而没有考虑人体的空间结构,这会导致以下这些问题:
- 不准确的人物检测框可能会影响特征的学习;
- 姿势的改变和人体的变形可能会导致度量学习的困难;
- 人体的部分身体部位被遮挡可能会引入无关的上下文信息;
- 在全局特征上强调局部差异是非常重要的,尤其是在区分两个外貌非常相似的人的时候

- 为了解决以上问题,过去的研究将重心放在part-based, local feature learning。有些研究将整个身体分割为几个固定的部分,而不考虑这几个部分之间的对应关系。这样的话无法解决以上问题。还有研究使用pose estimation帮助人体几个部分的对齐,但这样需要额外的supervision and a pose estimation step。
- 所以,作者采用了AlignedReID的方法:
- In this paper, we propose a new approach, called AlignedReID, which still learns a global feature, but perform an automatic part alignment during the learning, without requring extra supervision or explicit pose estimation.
- 作者提出的方法中,仍然是学习全局的特征,但是能自动进行各部分的对齐,且这一操作不需要额外的supervision 和 explicit pose estimation.
- In the local branch, we align local parts by introducing a shortest path loss.
- 在局部特征的学习中,我们通过计算最短路径进行对齐操作。
- In the inference stage, we discard the local branch and only extract the global feature.
- 在预测阶段,只使用了全局特征而没有采用局部特征。
- In other words, the global feature itself, with the aid of local features learning, can greatly address the drawbacks we mentioned above, in our new joint learning framework.
- 换句话说,在基于局部特征学习得到的全局特征能够解决基于CNN方法遇到的那四个问题。
- In addition, the form of global feature keeps our approach attractive for the deployment of a large ReID system, without costly local features matching.
- 作者还说,全局特征的形式使得他们的方法在大型的人物重识别中仍然能够很好的工作,而不需采用消耗巨大的局部特征匹配。
- We also adopt a mutual learning approach in the metric learning setting, to allow two models to learn better representations from each other.
- 对于度量学习,作者采用的是mutual learning 的方法,并取得了很好的结果。

- 现有几个概念需要补充一下:
- Metric Learning:Deep metric learning methods transform raw images into embedding feature, then compute the feature distances as their similarities. Usually, two images of the same person are defined as a positive pair, whereas two images of different persons are a negative pair. Triplet loss is motivatived by the margin enforced between positive and negative pairs. Selecting suitable samples for the training model through hard mining has been shown to be effective. Combining softmax loss with metric learning loss to speed up the convergence is also a popular method.
- Feature Alignments: Consider the spatial local information when learning features.
- Mutual Learning: presents a deep mutual learning strategy where an ensemble of students learn collaboratively and teach each other throughout the training process.
- Re-Ranking: After obtaining the image features, most current works choose the L2 Euclidean distance to compute a similarity score for a ranking or retrieval task.
- 下面对AlignedReID的原理进行更深的一步介绍:
- In AlignedReID, we generate a single global feature as the final output of the input image, and use the L2 distance as the similarity metric. However, the global feature is learned jointly with local features in the learning stage.
- Re-ID一般分为两步:一是提取特征,二是进行度量学习。在AlignedReID中,每张输入图片的最终输出是单一的全局特征,而该全局特征是与局部特征联合训练得来的。
- A global feature(a C-d vector) is extracted by directly applying global pooling on the feature map.
- 对于全局特征的提取,便是用global pooling在feature map上滑动提取特征。
- For the local features, a horizontal pooling, which is a global pooling in the horizontal direction, is first applied to extract a local feature for each row, and a 1X1 convolution is then applied to reduce the channel number from C to c. In this way, each local feature(a c-d vector) represents a horizontal part of image for a person.
- 对于局部特征提取,便是用horizontal pooling对feature map进行逐行提取,然后再进行1x1的卷积操作。这样得到的特征代表人体的水平部分。
- As a result, a person image is represented by a global feature and H local features.
- 最后,一张图像就可以用一个全局特征和多个局部特征代替。
- The distance of two person images is the summation of their global and local distances.
- 两张图片的距离是全局特征距离与局部特征距离之和。
- The global distance is simply the L2 distance of the global features.
- 全局特征距离是指全局特征之间的L2距离。
- For the local distance, we dynamically match the local parts from top to bottom to find the alignment of local feature with the minimum total distance.
- 局部特征距离是指通过动态规划的方法求出的最短路径,并通过该最短距离找到对齐的局部特征。
- This is based on a simple assumption that, for two images of the same person, the local feature from one body part of the first image is more similar to the semantically corresponding body part of the other image.
- 当然这一度量学习是基于假设:对于同一个人的同一部位在不同的图片中具有较高的相似度。
- Given the local features of two image, F=f1,...,fH and G=g1,...,gH , we first normalize the distance to [0, 1) by an element-wise transformation:
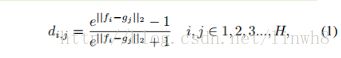
- where di,j is the distance between the i-th vertical part of
the first image and the j-th vertical part of the second image. A distance matrix D is formed based on these distances, where its (i, j)-element is di,j .
- We define the local distance between the two images as the total distance of the shortest path from (1, 1) to (H, H) in the matrix D.
- 以上公式是matrix D的每个元素的计算公式
- The distance can be calculated through dynamic programming as follows:
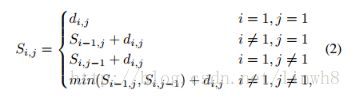
- where Si,j is the total distance of the shortest path when walking from (1, 1) to (i, j) in the distance matrix D, and SH,H is the total distance of the final shortest path between two image.
- 以上公式便是动态规划中求最短路径所采用的状态转移方程。

- Non-corresponding alignments are necessary to maintain the order of vertical alignment, as well as make the correspnding alignments possible.
- 在最短路径中,可能包含非对齐的特征,但这非但不会对结果造成影响,而且还会对维护垂直方向对齐的次序起着至关重要的作用。
- The reason for using the global distance to mine hard samples is due to two consideration:
- First, the calculation of the global distance is much faster than that of the local distance.
- Second, we observe that there is no significant difference in mining hard samples using both distances.
- Note that in the inference stage, we only use the global features to compute the similaritity of two person images. We make this choice mainly because we unexpectedly observed that the global feature itself is also almost as good as the combined features.
- This somehow counter-intuitive phenomenon might be caused by two factors:
- the feature map jointly learned is better than learning the global feature only, because we have exploited the structure prior of the person image in the learning stage;
- with the aid of local feature matching, the global feature can pay more attention to the body of the person, rather than over fitting the background.
- 以上解释了为什么只使用全局特征距离而不使用局部特征或者两者都使用。
- We apply mutual learning to train models for AlignedReID, which can further improve performance.
- 作者采用mutual learning去训练模型,因为这样可以提高性能。

- A distillation-based model usually transfers knowledge from a pre-trained large teacher network to a small student network.
- 一个好的模型通常都是采用迁移学习的方法:预训练一个模型然后在进行微调获得自己的模型。
- In this paper, we train a set of student models simultaneously, transferring knowledge between each other.
- 这篇论文同时训练多个模型,并让它们相互学习。
- We propose a new mutual learning loss for metric learning.
- The overall loss function include the metric loss, the metric mutual loss, the classification loss and classification mutual loss.
- The metric loss is decided by both the global distances and the local distances, while the metric mutual loss is decided only by the global distances.
- The classification mutual loss is the KL divergence for classification.
- The mutual learning loss is defined as:
- By applying the zero gradient function, the second-order gradients is:
- We found that it speeds up the convergence and improves the accuracy compared to a mutual loss without the zero gradient function.
- 这篇论文定义了新的mutual learning loss,且该loss中的zero gradient function加快了收敛速度,并提高了准确率。
- 最后作者讲述了他们的实验:
- 介绍了Market1501、CUHK03、MARS、CUHK-SYSU四个数据集
- 然后介绍了它们实现的细节:即实验的各个参数
- 接着通过与baseline的对比凸显AlignedReID的优势
- 再分析了Mutual Learning 发挥的作用
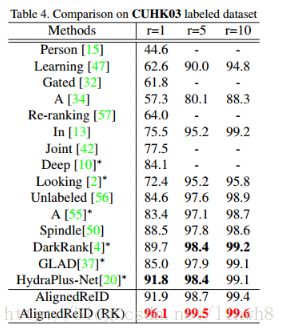
- 还有将该模型与state-of-the-art method进行对比
- 最后介绍了怎么测量Human Perfomance in Person Reid,并与AlignedReID的性能进行比较
- 作者还给出了导致人类准确率低于AlignedReID的猜测:
- First, the annotator usually summarizes some attributes, such as gender, age, and etc., to decide whether the imges contain the same person. Howeverm the summarized attributes might be incorrect.
- Second, color bias exists between cameras, and it could make the same person looks differently in the query and ground truth images such as in (c).
- Last, different camera angles and human poses might mislead the judgement of body shapes.
- 最后再补充句作者的感慨:the end-to-end learning with structure prior is more powerful than a “blind” end-to-end learning.

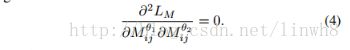


以上内容皆为本人观点,欢迎大家提出批评和指导,我们一起探讨!