大数据平台核心技术-实验记录
大数据平台核心技术-实验记录
- 一、前言
- 二、实验内容
-
- 实验一 :Hadoop集群搭建
- 实验二 :使用MapReduce实现倒排索引
- 三、实验过程记录
-
- 2.1安装准备
- 2.2 Hadoop集群搭建
-
- 1、安装文件上传工具
- 2、JDK安装
- 3、Hadoop安装:
- 4、Hadoop集群配置
- 2.3Hadoop集群测试
-
- 1、格式化文件系统
- 2、启动和关闭Hadoop集群
- 3、通过UI查看Hadoop运行状态
- 2.4Hadoop集群初体验
-
- Hadoop经典案例——单词统计
- 3.3 使用Shell命令操作HDFS
- 3.4 HDFS的Java API操作
- 3.5 使用MapReduce实现倒排索引
- 四、遇到的问题
-
- 实验一:
- 实验二:
一、前言
学校:许昌学院
学院:信息工程学院
实验环境:
操作系统:Linux (CentOS 6.7) JDK版本:1.8 (8u161) Hadoop版本:2.7.4
虚拟机:VMware Workstation Pro 15.5
参考资料:
Hadoop大数据技术原理与应用
linux命令大全(手册)
大数据平台核心技术 樊志伟
二、实验内容
实验一 :Hadoop集群搭建
1. 实验目的
熟悉常用Linux操作,学会搭建Hadoop集群,为后续上机实验做准备。
2. 实验环境(推荐)
操作系统:Linux (CentOS 6.7) JDK版本:1.8 (8u161) Hadoop版本:2.7.4
3. 实验内容和要求
| (一)熟悉常用Linux操作 | ||
|---|---|---|
| 实验内容 | 使用到的命令 | |
| (1) 切换到目录 /usr/local (2) 去到目前的上层目录 (3) 回到自己的主文件夹 |
cd: 切换目录 | |
| (4) 查看目录/usr下所有的文件 | ls: 查看文件与目录 | |
| (5) 进入/tmp目录,创建名为a的目录 (6) 创建目录a1/a2/a3/a4 |
mkdir: 新建新目录 | |
| (7) 将主文件夹下的.bashrc复制到/tmp下,命名为bashrc1 (8) 在/tmp下新建目录test,再复制这个目录到/usr |
cp: 复制文件或目录 | |
| (9) 将第7例文件bashrc1移动到目录/usr/test (10) 将第9例test目录重命名为test2 |
mv: 移动文件与目录,或更名 | |
| (11) 将以上例子中的bashrc1文件删除 (12) 将第10例的test2目录删除 |
rm: 移除文件或目录 | |
| (13) 查看主文件夹下的.bashrc文件内容 | cat: 查看文件内容 | |
| (14) 在/目录下新建目录test,然后打包成test.tar.gz (15) 将第14例文件解压缩到/tmp目录 |
tar: 压缩、解压缩命令 | |
| (二)搭建Hadoop集群的前期准备 | ||
| 实验内容 | 使用到的命令 | |
| (16) 配置三台虚拟机的网络 | vi. ifconfig, reboot, ping, service | |
| (17) 配置SSH免密码登陆 | rpm, grep, ssh-keygen, ssh-copy-id, ssh, exit | |
| (三)搭建Hadoop集群 | ||
| 实验内容 | 使用到的命令 | |
| (18) 安装并配置指定版本的JDK | rz, cd, tar, mv, vi, source | |
| (19) 安装并配置Hadoop集群主节点 | rz, tar, vi | |
| (20) 分发Hadoop至子节点并配置 | scp, source | |
| (21) 格式化HDFS,启动Hadoop集群 | hdfs namenode -format, start-dfs.sh | |
实验二 :使用MapReduce实现倒排索引
1. 实验目的
-
掌握HDFS操作常用的Shell命令;
-
熟悉HDFS操作常用的Java API;
-
掌握倒排索引及其MapReduce实现。
2. 实验环境(推荐)
-
Java开发环境:JDK 1.8 (8u161)
-
分布式开发环境:Hadoop 2.7.4
-
集成开发环境:Eclipse或IntelliJ IDEA
-
项目构建工具:Maven 3.5.4
3. 实验内容和要求
| (一)使用Shell命令操作HDFS | |
|---|---|
| 实验要求 | 其他说明 |
| (1) 在HDFS根目录下创建目录:“/学号后两位/test/” (2) 将本地系统中的文本文件复制到第(1)步创建的目录中 (3) 将第(2)步上传的文本文件复制到本地系统 |
需要使用到集群 文本文件统一命名为:hdfs_sh.txt,内容随意 |
| (二)使用Java API操作HDFS | |
| 实验要求 | 其他说明 |
| (4) 搭建Hadoop HDFS开发环境 (5) 初始化HDFS客户端对象 (6) 在本地创建文本文件并上传到HDFS (7) 从HDFS将第(6)步上传的文件下载到本地 |
需要使用到集群 使用Maven 文本文件统一命名为:hdfs_java.txt,内容随意 |
| (三)使用MapReduce实现倒排索引 | |
| 实验要求 | 其他说明 |
| (8) 收集数据,根据来源将数据存储在多个文本文件中 (9) 编写Map阶段程序代码 (10) 编写Combine阶段程序代码(可选) (11) 编写Reduce阶段程序代码 (12) 实现Driver主驱动程序并测试运行 |
无需使用集群 使用Maven 多个数据文件放在同一个文件夹中,文件夹命名为:mrdata |
三、实验过程记录
2.1安装准备
1、安装虚拟机
注意:每台虚拟机的内存需要量力而行,因为一共三台虚拟机加一台主机呢!如:本机共8g内存,那么平均分给4台电脑,每台可设2g内存!

2、创建工作目录:
mkdir -p /export/data
mkdir -p /export/software
mkdir -p /export/servers
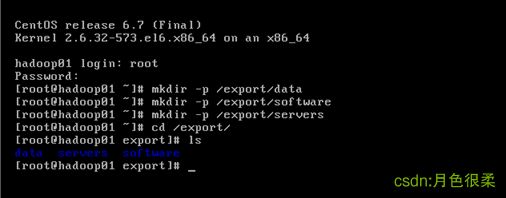
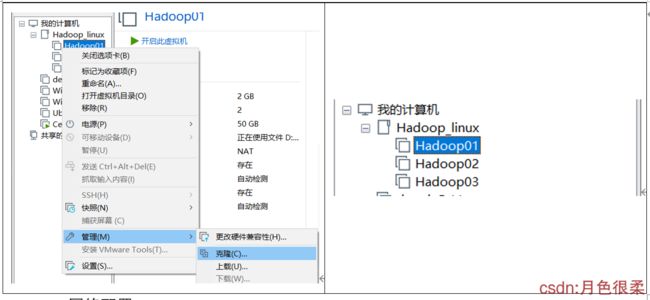
3、克隆虚拟机
4、Linux网络配置
a>配置VM ware
b>配置主机名 :vi /etc/sysconfig/network
c>配置IP地址映射: vi /etc/hosts


5、网络参数配置
a>配置MAC地址
b>配置静态IP
c>验证

6、SSH服务配置
a> 查看是否安装SSH: rpm -qa |grep ssh
b>安装SSH: yum install openssh-server
c>查看SSH服务是否启动: ps -e | grep sshd

7、虚拟机免密登录

-
为什么要免密登录
Hadoop节点众多,所以一般在主节点启动从节点这个时候就需要程序自动在主节点登录到从节点中,如果不能免密就每次都要输入密码,非常麻烦
-
免密SSH登录的原理
1.需要先在B节点配置A节点的公钥
2. A节点请求B节点要求登录
3. B节点使用A节点的公钥,加密- -段随机文本
4. A节点使用私钥解密,并发回给B节点
5. B节点验证文本是否正确 -
第一步:三台机器生成公钥与私钥
在三台机器执行以下命令,生成公钥与私钥
ssh -keygen -t rsa
执行该命令之后,按下三个回车即可

-
第二步:拷贝公钥到同一台机器
三台机器将拷贝公钥到第一台机器
三台机器执行命令: ssh-copy-id hadoop01

-
第三步:复制第一台机器的认证到其他机器
将第一台机器的公钥拷贝到其他机器上
在第一天机器上面指向以下命令
scp /root/.ssh/authorized_ keys hadoop02:/root/.sshscp /root/.ssh/authorized_ keys hadoop03:/root/.ssh

2.2 Hadoop集群搭建
1、安装文件上传工具
安装命令:yum install lrzsz -y 使用命令:rz
2、JDK安装
- 下载JDK
https://www.oracle.com/technetwork/java/javase/downloads/index.html
- 查看当前系统自带jdk并卸载:
注:参考:here
rpm -qa | grep java

然后通过 rpm -e --nodeps 后面跟系统自带的jdk名 这个命令来删除系统自带的jdk,
例如:
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64

删完之后可以再通过 rpm -qa | grep Java 命令来查询出是否删除掉
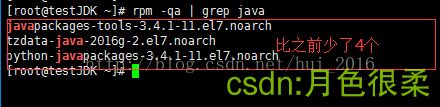
- 安装JDK
#上传jdk到/export/software路径下去,井解压
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
mv jdk1.8.0_161 jdk
- 配置JDK环境变量
vi /etc/profile
添加以下内容:
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
修改完成之后记得source /etc/profle生效
source /etc/profile
- JDK环境验证
java -version
3、Hadoop安装:
- 下载Hadoop安装包
http://archive.apache.org/dist/hadoop/common/
- 解压安装Hadoop
#将hadoop-2.7.4. tar.gz包上传到/export/software日录
cd /export/softwares
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/
- 配置
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
修改完成之后记得source /etc/profle生效
source /etc/profile
- 验证Hadoop环境
hadoop version
4、Hadoop集群配置
#进入目录
cd /export/servers/hadoop-2.7.4/etc/hadoop
4.1 配置Hadoop集群主节点
该部分可参考:官方文档
-
修改hadoop-env.sh
export JAVA_HOME=/export/servers/jdk
-
修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/export/servers/hadoop-2.7.4/tmp</value> </property> </configuration> -
修改hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop02:50090</value> </property> </configuration> -
修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<!-- Put site-specific property overrides in this file. --> <configuration> <!--指定MapReduce运行时框架, 这里指定在Yarn上,默认是local --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
修改yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 2020.5.2更新:设置内存 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1600</value> </property> <!-- 设置cpu 核数 --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property> </configuration> -
修改slaves文件。打开该配置文件,先删除里面的内容(默认localhost) ,然后配置如下内容。
hadoop01 hadoop02 hadoop03
4.2 将集群主节点的配置文件分发到其他子节点
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
在hadoop02和hadoop03上执行:source /etc/profile
2.3Hadoop集群测试
1、格式化文件系统
初次启动HDFS集群时,必须对主节点进行格式化处理。
格式化文件系统指令如下:
$ hdfs namenode -format $ hadoop namenode -format
2、启动和关闭Hadoop集群
-
单节点逐个启动和关闭
-
在主节点上执行指令启动/关闭HDFS NameNode进程;
hadoop-daemon.sh start namenode -
在每个从节点上执行指令启动/关闭HDFS DataNode进程;
hadoop-daemon.sh start datanode #使用jps查看java进程验证 jps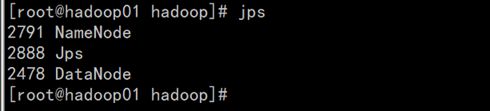
-
在主节点上执行指令启动/关闭YARN ResourceManiger进程;
yarn-daemon.sh start resourcemanager -
在每个从节点上执行指令启动/关闭YARN nodemanager进程;
yarn-daemon.sh start nodemanager #使用jps查看java进程验证 jps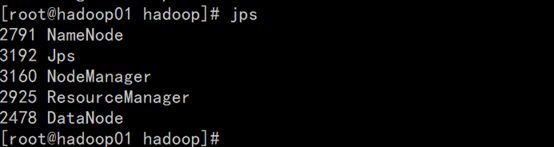
-
在节点hadoop02执行指令启动/关闭SecondaryNameNode进程。
hadoop-daemon.sh start secondarynamenode -
关闭只需将start 换成stop

-
-
脚本一键启动和关闭
- 在主节点hadoop01上执行指令“start-dfs.sh”或“stop-dfs.sh”启动/关闭所有HDFS服务进程;
- 在主节点hadoop01上执行指令“start-yarn.sh”或“stop-yarn.sh”启动/关闭所有YARN服务进程;
- 在主节点hadoop01上执行“start-all.sh”或“stop-all.sh”指令,直接启动/关闭整个Hadoop集群服务。
3、通过UI查看Hadoop运行状态
Hadoop集群正常启动后,它默认开放了两个端口50070和8088,分别用于监控HDFS集群和YARN集群。通过UI界面可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。
1) 配置IP映射:
打开:C:\Windows\System32\drivers\etc\hosts
添加以下内容:
192.168.121.134 hadoop01
192.168.121.135 hadoop02
192.168.121.136 hadoop03
2) 关闭防火墙:service iptables stop
3) 关闭防火墙开机启动:chkconfig iptables off

在Windows系统下,访问http://hadoop01:8088,查看Yarn集群状态,且从图中可以看出Yarn集群状态显示正常。
注:点击左侧Nodes,看到以下页面,一般配置就正确了


2.4Hadoop集群初体验
Hadoop经典案例——单词统计
-
打开HDFS的UI界面,查看HDFS中是否有数据文件,默认是没有数据文件。

-
准备文本文件,在Linux系统上编辑一个文本文件,然后上传至HDFS上。
创建数据存储目录:mkdir -p /export/data
编辑文件:vi word.txt
写入一些单词:
hello itcast
hello itheima
hello Hadoop
在hdfs上创建目录:hadoop fs -mkdir -p /wordcount/input

将文件上传至hdfs 的目录:hadoop fs -put /export/data/word.txt /wordcount/input

-
运行hadoop-mapreduce-examples-2.7.4.jar包,实现词频统计。
进入:cd /export/servers/hadoop-2.7.4/share/hadoop/mapreduce
执行:hadoop jar hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output
注:执行该步时出错,(一直为接受状态,没有运行;有大佬请解答!)如下图:(已解决!)

成功界面:

-
查看UI界面,Yarn集群UI界面出现程序运行成功的信息。HDFS集群UI界面出现了结果文件。

3.3 使用Shell命令操作HDFS
Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。
官方文档:here
hadoop fs <args>
hadoop dfs <args>
hdfs dfs <args>
上述命令中,“hadoop fs" 是使用面最广,可以操作任何文件系统,如本地系统、HDFS等,“hadoop dfs"则主要针对HDFS文件系统,已经被“Ihdfs dfs"代替。
文件系统(FS) Shell 包含了各种的类shell的命令,可以直接与Hadoop分布式文件系统以及其他文件系统进行交互,如与LocalFS、 HTTPFS、S3 FS 文件系统交互等。通过命令行的方式进行交互,具体操作常用命令,如表下表:
| 命令参数 | 功能描述 |
|---|---|
| -ls | 查看指定路径的目录结构 |
| -du | 统计目录下所有文件大小 |
| -mv | 移动文件 |
| -cp | 复制文件 |
| -rm | 删除文件/空白文件夹 |
| -cat | 查看文件内容 |
| -text | 源文件输出为文本格式 |
| -mkdir | 创建空白文件夹 |
| -put | 上传文件 |
| -help | 帮助 |
| -get | 下载文件 |
1、 ls命令


2、 mkdir命令

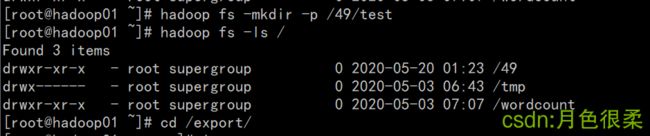
3、 put命令




4、 get命令


5、 其他命令:here
3.4 HDFS的Java API操作
由于Hadoop是使用Java语言编写的,因此可以使用Java API操作Hadoop文件系统。HDFS Shell本质上就是对Java API的应用,通过编程的形式操作HDFS,其核心是使用HDFS提供的Java API构造一个访问客户端对象,然后通过客户端对象对HDFS上的文件进行操作(增、删、改、查)。
参考:https://my.oschina.net/u/2371923/blog/2870791
(1) 搭建Hadoop HDFS开发环境
1、win10上搭建hadoop环境
1).官网下载hadoop-2.7.4.tar.gz版本,解压:D:\hadoop-2.7.4
2).配置环境变量
HADOOP_HOME=D:\hadoop-2.7.4
PATH=%HADOOP_HOME%\bin
3.将windows上编译的文件hadoop.dll、winutils.exe放至%HADOOP_HOME%\bin下
4.将hadoop.dll放到c:/windows/System32下
5.设置D:\hadoop-2.7.4\etc\hadoop\hadoop-env.cmd中的JAVA_HOME为真实java路径(路径中不能带空格,否者会报错).

6.测试hadoop是否配置成功,命令行输入:hadoop version
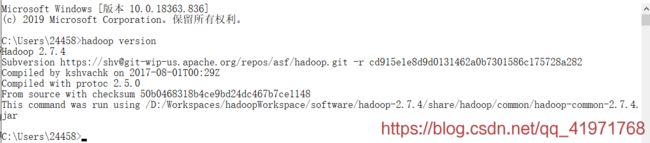
2、在idea中新建maven工程hadoop-demo
idea配置maven
打开Settings —>搜索maven—>进入就能看到自带maven

更改maven数据源:
1、在安装目录找到该文件
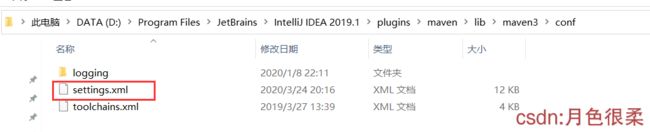
2、打开修改以下部分并保存。
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
mirrorId</id>
repositoryId</mirrorOf>
Human Readable Name for this Mirror.</name>
http://my.repository.com/repo/path</url>
</mirror>
-->
aliyun-public</id>
*</mirrorOf>
aliyun public</name>
https://maven.aliyun.com/repository/public</url>
</mirror>
aliyun-central</id>
*</mirrorOf>
aliyun central</name>
https://maven.aliyun.com/repository/central</url>
</mirror>
aliyun-spring</id>
*</mirrorOf>
aliyun spring</name>
https://maven.aliyun.com/repository/spring</url>
</mirror>
aliyun-spring-plugin</id>
*</mirrorOf>
aliyun spring-plugin</name>
https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
</mirrors>
3、将上述文件copy至以下目录进行覆盖
4、重启idea
(2) 初始化HDFS客户端对象
1、创建maven工程并添加依赖,import依赖
org.apache.hadoop</groupId>
hadoop-common</artifactId>
2.7.4</version>
</dependency>
org.apache.hadoop</groupId>
hadoop-hdfs</artifactId>
2.7.4</version>
</dependency>
org.apache.hadoop</groupId>
hadoop-client</artifactId>
2.7.4</version>
</dependency>
org.apache.hadoop</groupId>
hadoop-mapreduce-client-core</artifactId>
2.7.4</version>
</dependency>
junit</groupId>
junit</artifactId>
4.12</version>
</dependency>
org.apache.zookeeper</groupId>
zookeeper</artifactId>
3.4.10</version>
</dependency>
</dependencies>
2、创建java类,添加初始化HDFS客户端对象的方法
package com.itcast.hdfsdemo;
//import javax.security.auth.login.Configuration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
/**
* @project: hadoopDemo
* @description:
* @author: dell
* @date: 2020/5/20 - 1:21
* @version: 1.0
* @website:
*/
public class HDFS_CRUD {
FileSystem fs = null;
@Before
public void init() throws IOException {
// 构造一个配置参数对象,设置一个参数:我们要访问的hdfs的URI
Configuration conf = new Configuration();
// 这里指定使用的是HDFS文件系统
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 通过如下的方式进行客户端身份的设置
System.setProperty("HADOOP_USER_NAME", "root");
// 通过FileSystem的静态方法获取文件系统客户端对象
fs = FileSystem.get(conf);
}
@After
public void close() throws IOException {
// 关闭资源
fs.close();
}
}
(3) 在本地创建文本文件并上传到HDFS
1、在本地创建文件:

2、添加上传文件测试方法
@Test
public void testAddFileToHdfs() throws IOException {
// 要上传的文件所在本地路径
Path src = new Path("D:\\Workspaces\\hadoopWorkspace\\data\\test/put/hdfs_java.txt");
// 要上传到hdfs的目标路径
Path dst = new Path("/49/test/");
// 上传文件方法
fs.copyFromLocalFile(src, dst);
}
3、启动hadoop集群,运行测试方法进行测试

(4) 从HDFS将上传的文件下载到本地
1、添加下载文件的测试方法
// 从hdfs中复制文件到本地文件系统
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException, IOException {
// 下载文件
fs.copyToLocalFile(new Path("/49/test/hdfs_java.txt"), new Path("D:\\Workspaces\\hadoopWorkspace\\data\\test/get/"));
}
2、启动集群,运行方法测试

3.5 使用MapReduce实现倒排索引
在3.4中的工程里面新建包:cn.itcast.mr.invertedIndex
(1) 收集数据,根据来源将数据存储在多个文本文件中

(2) 编写Map阶段程序代码
package cn.itcast.mr.invertedIndex;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @project: hadoopDemo
* @description:
* @author: dell
* @date: 2020/5/20 - 12:07
* @version: 1.0
* @website:
*/
public class InvertedIndexMapper extends Mapper<LongWritable, Text,Text,Text> {
private static Text keyInfo = new Text();// 存储单词和 URL 组合
private static final Text valueInfo = new Text("1");// 存储词频,初始化为1
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
/**
* @description: 在该方法中将K1和V1转为K2和V2
* @param: [key:K1行偏移量, value:V1行文本数据, context:上下文对象]
* @date: 2020/5/20 - 12:11
* @return: void
*/
String line = value.toString();
String[] fields = StringUtils.split(line, " ");// 得到字段数组
FileSplit fileSplit = (FileSplit) context.getInputSplit();// 得到这行数据所在的文件切片
String fileName = fileSplit.getPath().getName();// 根据文件切片得到文件名
for (String field : fields) {
// key值由单词和URL组成,如“MapReduce:file1”
keyInfo.set(field + ":" + fileName);
context.write(keyInfo, valueInfo);
}
}
}
(3) 编写Combine阶段程序代码(可选)
package cn.itcast.mr.invertedIndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @project: hadoopDemo
* @description:
* @author: dell
* @date: 2020/5/20 - 12:16
* @version: 1.0
* @website:
*/
public class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {
private static Text info = new Text();
// 输入: (4) 编写Reduce阶段程序代码
package cn.itcast.mr.invertedIndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @project: hadoopDemo
* @description:
* @author: dell
* @date: 2020/5/20 - 19:04
* @version: 1.0
* @website:
*/
public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {
private static Text result = new Text();
// 输入:(5) 实现Driver主驱动程序并测试运行
package cn.itcast.mr.invertedIndex;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @project: hadoopDemo
* @description:
* @author: dell
* @date: 2020/5/20 - 19:17
* @version: 1.0
* @website:
*/
public class InvertedIndexDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
//保存Job任务对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置Job任务对象
job.setJarByClass(InvertedIndexDriver.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("D:\\Workspaces\\hadoopWorkspace\\workspace\\hadoopDemo\\src\\main\\resources\\mrdata"));
// 指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("D:\\Workspaces\\hadoopWorkspace\\workspace\\hadoopDemo\\src\\main\\resources\\output"));
//启动Job任务 :向 yarn 集群提交这个 job
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
(6)运行结果

四、遇到的问题
实验一:
1、jdk安装成功,却使用的系统自带jdk
参考本文:jdk安装 —>查看当前系统自带jdk并卸载:
注:参考:here
2、无法启动 NodeManager
本机配置不满足,修改yarn-siet.xml文件.添加下面内容:
<!-- 设置内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1600</value>
</property>
<!-- 设置cpu 核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
注:参考:here
3、执行词频统计一直处于接受,未运行
属于服务未全部启动,请确保下图服务启动:

实验二:
1、运行报错:无法连接到hadoop01:9000
java.net.ConnectException: Call From DESKTOP-AUK8T9H/192.168.121.5 to hadoop01:9000 failed on connection exception: java.net.ConnectException: Connection refused: no further
解决:Hadoop集群未开启导致,将集群开启即可。
2、配置完成却运行报错:
解决:查询原因是因为:jdk路径出现空格导致。重新安装jdk至无空格和中文的路径下即可。
3、Driver主驱动程序进行测试运行报错:
file:/D:/Workspaces/hadoopWorkspace/workspace/hadoopDemo/src/main/resources/output already exists
解决:通过删除已存在的输出目录进行解决
更新日期:2020.5.20