黑马程序员_Java API
Java的API文档是SDK说明文件的一部分,是具体告诉你上述内容的使用方法的文档,是Java程序开发的最好帮手。我主要学习了其中的一小部分文档,如:String,Stringbuff而,Stringbuiller,集合框架,IO包,net包 等。
java api中常见的包介绍:
SDK给出了一套标准的类库,这些类为执行大部分的编程任务提供了方法和接口。类库被组织成许多包,每个包又包含一些子包和多个类。形成树型结构的类层次,其中包括核心包jaˉva、扩展包javax和org等。如图1ˉ3所示。下面简单介绍一些重要的包及其类:
1)java.lang———这个包包含了一些形成语言核心的类,提供了类似Character、Integer和Double这样的封装类。它还提供了系统标准类,如String和StringBuffer。Java编辑器总是自动装载这个包。因而一般不必显示导入java.lang中的任何类。这个包中的许多类在本书的许多其他章节还将叙述。
2)java.applet———这个包提供了创建Java applet的途径,Java applet运行在Web浏览器下,通常通过Internet下载。
3)java.awt———是由许多组成Java的抽象视窗工具(awt)的类所组成的包,它提供了基于类的图形用户界面,可以为Java applet和应用程序编程提供视窗、按钮、对话框及其他控件。
4)java.net———这个包提供了网络、套接字处理器和Internet实用工具类。
5)java.io———这个包中的类提供了输入输出服务,用于读出和写入文件数据,访问键盘输入和打印输出。
6)java.util———这个包包含为任务设置的实用程序类和集合框架类,每一个Java应用程序和Java applet可能至少会用到这个包中的一个类。另外它还提供了Collection接口和它的实现容器类,如List和Set。
7)java.rmi———远程方法启用包,在这个包中的类提供了通过远程接口控制的分布式代码的支持。通过该包中的类,可以创建Java应用程序,使它的不同部分在不同的系统中一起运行。
8)java.sql———这个包提供了结构化查询语言数据库字段类型和方法的实现。根据系统的不同,这个包的类可能会通过一个特定的数据库系统实现,或者缺省时通过ODBC(开放数据库连接)标准的直接映射实现。
在jdk安装文件夹中有API文档里面所有函数的原码,所以我们可以直接使用API中的函数,在使用API时应该导包。比如导入一个util包:
import util.xxx或者 import util.*。 其中的.* 代表着这个目录下的所有文档。
其中有几个比较常用的内容,如:String。在String中存在着许多方法比如getname,toString等,这些方法都可以通过查阅文档获得。
在java中也存在着不少的容器,在这一部分主要学习的容器有两个:StringBuffer,StringBuilder与集合等。StringBuffer和StringBuilder因为都是容器,他们都具备增,删,改,查这四种功能,同时他们的长度都是可变的。StringBuffer在永兴的时候是同步的,而StringBuilder不是同步的,所以StringBuilder的效率比StringBuffer要高,在以后的开发中一般要使用StringBuilder。
同时也明确了升级的三个原因:
1.提高效率。
2.简化书写。
3.提高安全性。
Collection:
list:元素是有序的,元素可以重复,因为该集合体系有索引。
ArryList:底层的数据结构使用的是数组结构,特点:查询速度很快,但是增删 稍慢。
LinkedList:底层数据结构使用的是链表数据结构。特点:增删速度很快,查询稍慢。
vector:底层是数组数据结构。线程同步,被ArryList替代了。
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
HashSet:底层数据结构是哈希表。线程是非同步的。(保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true)。
TreeSet:可以对Set中的元素进行排序。
Map:
Hashtable:底层是哈希表数据结构,不可以存入null键和null值,该集合是同步线程,效率低下。
HashMap:底层是哈希表数据结构,允许使用null键和null值,该集合是不同步的,效率高。
TreeMap:底层是二叉树数据结构。线程不同步,可以用于给map集合中的键进行排序。
在list中有一种特殊的取出元素方法,叫做迭代器。举例如下:
Class Dome
{
public static void main(String[] arges)
{
method_get();
}
public static void method_get()
{
Arraylist a1 = new ArrayList();
a1.add("java01");
a1.add("java02");
a1.add("java03");
a1.add("java04");
Iterator it = a1.iterator();
while(it.hasNext())
{
System.out.println(it.next);
}
}
这就是迭代器取出集合中的元素,同时为了方便书写还引入了高级for循环。其格式为:for(数据类型 变量名:被遍历的集合或数组)。
在集合框架中为了解决安全问题在JDK1.5版本以后出现了一种新特性叫做泛型。其表现形式如:
好处:
1.将运行时期出现问题的classcastException,转移到了编译时期,方便与程序猿解决问题,让运行时期问题减少,是程序变的安全。
java api中常见的包介绍:
SDK给出了一套标准的类库,这些类为执行大部分的编程任务提供了方法和接口。类库被组织成许多包,每个包又包含一些子包和多个类。形成树型结构的类层次,其中包括核心包jaˉva、扩展包javax和org等。如图1ˉ3所示。下面简单介绍一些重要的包及其类:
1)java.lang———这个包包含了一些形成语言核心的类,提供了类似Character、Integer和Double这样的封装类。它还提供了系统标准类,如String和StringBuffer。Java编辑器总是自动装载这个包。因而一般不必显示导入java.lang中的任何类。这个包中的许多类在本书的许多其他章节还将叙述。
2)java.applet———这个包提供了创建Java applet的途径,Java applet运行在Web浏览器下,通常通过Internet下载。
3)java.awt———是由许多组成Java的抽象视窗工具(awt)的类所组成的包,它提供了基于类的图形用户界面,可以为Java applet和应用程序编程提供视窗、按钮、对话框及其他控件。
4)java.net———这个包提供了网络、套接字处理器和Internet实用工具类。
5)java.io———这个包中的类提供了输入输出服务,用于读出和写入文件数据,访问键盘输入和打印输出。
6)java.util———这个包包含为任务设置的实用程序类和集合框架类,每一个Java应用程序和Java applet可能至少会用到这个包中的一个类。另外它还提供了Collection接口和它的实现容器类,如List和Set。
7)java.rmi———远程方法启用包,在这个包中的类提供了通过远程接口控制的分布式代码的支持。通过该包中的类,可以创建Java应用程序,使它的不同部分在不同的系统中一起运行。
8)java.sql———这个包提供了结构化查询语言数据库字段类型和方法的实现。根据系统的不同,这个包的类可能会通过一个特定的数据库系统实现,或者缺省时通过ODBC(开放数据库连接)标准的直接映射实现。
在jdk安装文件夹中有API文档里面所有函数的原码,所以我们可以直接使用API中的函数,在使用API时应该导包。比如导入一个util包:
import util.xxx或者 import util.*。 其中的.* 代表着这个目录下的所有文档。
其中有几个比较常用的内容,如:String。在String中存在着许多方法比如getname,toString等,这些方法都可以通过查阅文档获得。
在java中也存在着不少的容器,在这一部分主要学习的容器有两个:StringBuffer,StringBuilder与集合等。StringBuffer和StringBuilder因为都是容器,他们都具备增,删,改,查这四种功能,同时他们的长度都是可变的。StringBuffer在永兴的时候是同步的,而StringBuilder不是同步的,所以StringBuilder的效率比StringBuffer要高,在以后的开发中一般要使用StringBuilder。
同时也明确了升级的三个原因:
1.提高效率。
2.简化书写。
3.提高安全性。
在java中还存在着比较重要的一部分内容叫做集合类,集合类的出现是为了方便对多个对象进行操作和存储。和上述两种容器相同的是,集合容器的长度是也是可变的,同时集合也可以用来存储不同类型的对象。
java 集合框架关系图:
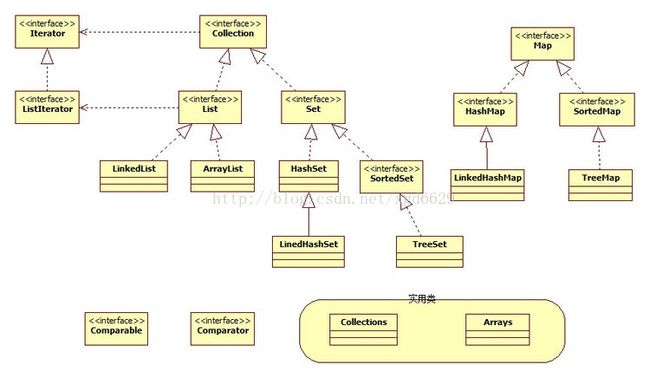
Collection:
list:元素是有序的,元素可以重复,因为该集合体系有索引。
ArryList:底层的数据结构使用的是数组结构,特点:查询速度很快,但是增删 稍慢。
LinkedList:底层数据结构使用的是链表数据结构。特点:增删速度很快,查询稍慢。
vector:底层是数组数据结构。线程同步,被ArryList替代了。
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
HashSet:底层数据结构是哈希表。线程是非同步的。(保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true)。
TreeSet:可以对Set中的元素进行排序。
Map:
Hashtable:底层是哈希表数据结构,不可以存入null键和null值,该集合是同步线程,效率低下。
HashMap:底层是哈希表数据结构,允许使用null键和null值,该集合是不同步的,效率高。
TreeMap:底层是二叉树数据结构。线程不同步,可以用于给map集合中的键进行排序。
在list中有一种特殊的取出元素方法,叫做迭代器。举例如下:
Class Dome
{
public static void main(String[] arges)
{
method_get();
}
public static void method_get()
{
Arraylist a1 = new ArrayList();
a1.add("java01");
a1.add("java02");
a1.add("java03");
a1.add("java04");
Iterator it = a1.iterator();
while(it.hasNext())
{
System.out.println(it.next);
}
}
这就是迭代器取出集合中的元素,同时为了方便书写还引入了高级for循环。其格式为:for(数据类型 变量名:被遍历的集合或数组)。
在集合框架中为了解决安全问题在JDK1.5版本以后出现了一种新特性叫做泛型。其表现形式如:
好处:
1.将运行时期出现问题的classcastException,转移到了编译时期,方便与程序猿解决问题,让运行时期问题减少,是程序变的安全。
2.避免了强制转换的麻烦。