【Python】网络爬虫(一):pyquery一瞥
1.pyquery简介
python中的pyquery模块语法与jquery相近,可用来解析HTML文件。官方文档地址:https://pythonhosted.org/pyquery/ 。通过HTML中的标签、id、给定的索引等来获取元素,使得解析HTML文件极为方便。
2.实例
2.1 爬取豆瓣电影页面中主演

为找出主演,需要把带有rel="v:starring"的所有a标签找出来
# -*- coding: utf-8 -*-
from pyquery import PyQuery as pq
#读取Batman Begins页面
doc = pq(url="http://movie.douban.com/subject/1309069/")
#遍历starring节点
starring = doc("a[rel='v:starring']").map(lambda i,e:pq(e).text())
#打印
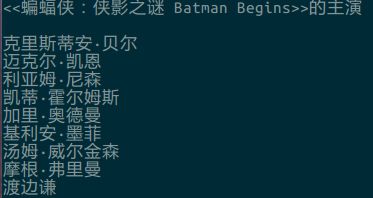
print "<<"+doc("span[property='v:itemreviewed']").text()+u">>的主演\n"
for i in starring:
print i.encode('utf-8')得到结果
2.2 百度贴吧爬虫
爬虫功能:将楼主的所发内容保存在本地txt文件中。
分析页面地址:只看楼主页面是贴子地址后加“?see_lz=1”,到第二页时,页面再加上“&pn=2”。
分析页面元素:楼主所发内容正则表达式为id="post_content.*?>(.*?)
![]()
纯python版的百度贴吧爬虫(参看这里)
# -*- coding: utf-8 -*-
#--------------------------------
# program: 百度贴吧爬虫
# date: 2014.4.29
#--------------------------------
from pyquery import PyQuery as pq
import urllib2
import re
class tiebaSpider:
def __init__(self,link):
#只看楼主页面
self.url = link+'?see_lz=1'
#读取页面
self.raw_html = urllib2.urlopen(self.url).read().decode('gbk')
#获得贴子标题
self.title = re.findall('(.*?)',self.raw_html)[0]
#总共页数
self.total_pages = int(re.findall(r'class="red">(\d+?)<',self.raw_html)[0])
self.contents = []
def get_contents(self):
"""获取所有页面的内容"""
page = self.url+'&pn='
for i in range(1,self.total_pages+1):
#爬取每个页面
print u'正在爬取第%d页内容...' %i
raw_page = urllib2.urlopen(page+str(i)).read().decode('gbk')
raw_contents = re.findall('id="post_content.*?>(.*?)