MySQL中的查询优化
MySQL中的查询优化
在上一篇博客中,我们讲过了explain语句的用法以及单表查询的优化策略,这篇将会讨论关联查询,子查询还有order by和group by查询的优化策略。
一、关联查询优化
我们首先建立一个类表和一个书目表,代码如下。
CREATE TABLE IF NOT EXISTS `class` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
当我们在没有建立索引的情况下将这两张表关联在一起时,我们通过explain语句分析其执行效率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NfsOLkJg-1598091095248)(C:\Users\jiangzhe\AppData\Roaming\Typora\typora-user-images\image-20200822121824639.png)]](http://img.e-com-net.com/image/info8/c3e7fdbe4f164689a0e0f77e9a061f17.jpg)
我们会发现,执行查询的行数为20*20行,extra字段我们可以看到using join buffer说明两个表的联结字段并没有建立索引。下面我们给book表建立索引,再次执行上面的语句。
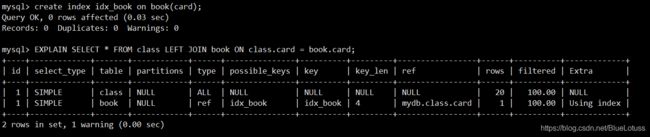
通过执行结果我们可以看到因为book表建立了索引,所以查询type为ref,查询的行数变成了20*1,提高了查询的效率。我们试着再给class表建立索引,看看会不会使最终的查询只需要1行。
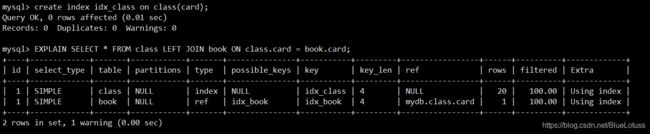
给class表的card字段也建立索引后,我们发现查询的行数并没有减少,这是为什么呢?这是因为两个表在进行left join时,左边的表会成为驱动表,右边的表会成为被驱动表,避免不了驱动表的全表扫描,所以给驱动表建立索引也没用,但是要给被驱动表建立索引。
那当我们使用inner join时结果又会怎么样呢?我们接着上面的代码首先清除掉book表上的索引,然后执行inner join操作。
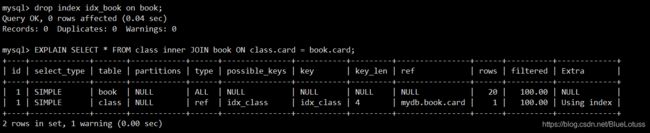
我们发现此时,book表变成了驱动表而class表变成了被驱动表,这是因为mysql在执行inner join的操作的过程中,自己决定哪个是驱动表哪个是被驱动表。由于在calss表上我们建立了索引,如果作为被驱动表可以减少查询的行数,所以mysql将class表放在了被驱动表的位置上。
下面给出关联查询的建议:
- 保证被驱动表的join字段已经被索引
- left join 时,选择小表作为驱动表,大表作为被驱动表。
- inner join 时,mysql会自己帮你把小结果集的表选为驱动表。
- 子查询尽量不要放在被驱动表,有可能使用不到索引。
二、子查询优化
create table t_dept(
id int(11) not null auto_increment,
deptName varchar(30) default null,
address VARCHAR(40) default null,
PRIMARY KEY (id)
)ENGINE=INNODB auto_increment=1 DEFAULT CHARSET=utf8;
CREATE TABLE t_emp(
id int(11) not null auto_increment,
name varchar(20) default null,
age int(3) DEFAULT null,
deptId int(11) DEFAULT NULL,
empno int not null,
PRIMARY KEY (id),
key idx_dept_id (deptId)
#CONSTRAINT fk_dept_id FOREIGN KEY (deptId) REFERENCES t_dept(Id)
)ENGINE=INNODB auto_increment=1 DEFAULT CHARSET=utf8;
INSERT into t_dept(deptName, address) values('华山', '华山');
INSERT into t_dept(deptName, address) values('丐帮', '洛阳');
INSERT into t_dept(deptName, address) values('峨眉', '峨眉山');
INSERT into t_dept(deptName, address) values('武当山', '武当山');
INSERT into t_dept(deptName, address) values('明教', '光明顶');
INSERT into t_dept(deptName, address) values('少林', '少林寺');
insert into t_emp(name, age, deptId, empno) VALUES('风清扬', 90, 1, 100001);
insert into t_emp(name, age, deptId, empno) VALUES('岳不群', 50, 1, 100002);
insert into t_emp(name, age, deptId, empno) VALUES('令狐冲', 24, 1, 100003);
insert into t_emp(name, age, deptId, empno) VALUES('洪七公', 70, 2, 100004);
insert into t_emp(name, age, deptId, empno) VALUES('乔峰', 35, 2, 100005);
insert into t_emp(name, age, deptId, empno) VALUES('灭绝师太', 70, 3, 100006);
insert into t_emp(name, age, deptId, empno) VALUES('周芷若', 20, 3, 100007);
insert into t_emp(name, age, deptId, empno) VALUES('张三丰', 100, 4, 100008);
insert into t_emp(name, age, deptId, empno) VALUES('张无忌', 25, 5, 100009);
insert into t_emp(name, age, deptId, empno) VALUES('韦小宝', 18, null, 1000010);
#增加掌门字段
ALTER table t_dept add CEO int(11);
update t_dept set ceo = 2 where id = 1;
update t_dept set ceo = 4 where id = 2;
update t_dept set ceo = 6 where id = 3;
update t_dept set ceo = 8 where id = 4;
update t_dept set ceo = 9 where id = 5;
在查询至少有两位非掌门人成员的门派时,我们首先会找出非掌门的人,经常会这样写
select * from t_emp a where a.id not in
(select b.ceo from t_dept b where b.ceo is not null);
在这个语句中我们有了一个子查询,因此会增加查询的趟数,而且使用了is not null使得索引失效。
为了提高查询效率,我们可以采用下面这种写法:
select * from t_emp a left join t_dept b on a.id=b.CEO where b.ceo is null;
因此,在子查询中我们尽量不要使用not in或者not exists,可以用left join on xxx is null来代替
三、order by查询优化
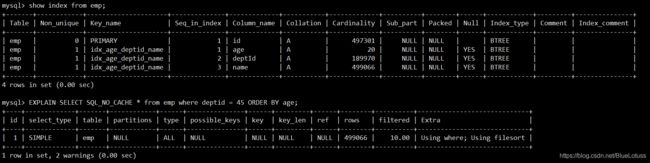
说明:这里使用的是上篇博客中所创建的emp和dept表,具体可以参考这里
1.无过滤,不索引
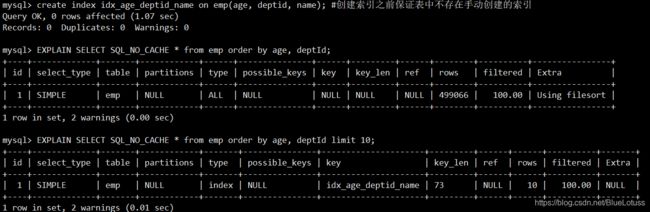
create index idx_age_deptid_name on emp(age, deptid, name); #创建索引之前保证表中不存在手动创建的索引
EXPLAIN SELECT SQL_NO_CACHE * from emp order by age, deptId;#用不上索引,extra字段显示有filesort说明有系统排序
EXPLAIN SELECT SQL_NO_CACHE * from emp order by age, deptId limit 10;#用上索引
#总结:无过滤,不索引。指没有where条件过滤或者limit,order by是用不上索引的
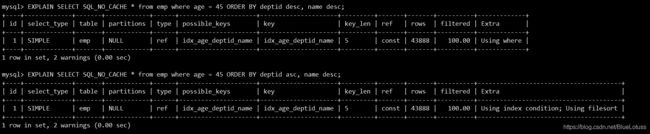
2、顺序错,必排序
EXPLAIN SELECT SQL_NO_CACHE * from emp where age = 45 ORDER BY deptid;#用上索引
EXPLAIN SELECT SQL_NO_CACHE * from emp where age = 45 ORDER BY deptid, name;#用上索引
EXPLAIN SELECT SQL_NO_CACHE * from emp where age = 45 ORDER BY deptid, empno;#用上索引,但是有using filesort,因为order by后面的empno没有包含在索引当中
EXPLAIN SELECT SQL_NO_CACHE * from emp where deptid = 45 ORDER BY age;#顺序错了,必排序
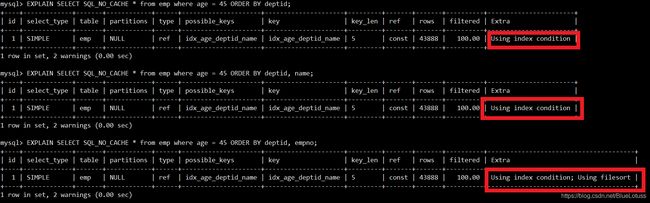
3、方向反,必排序
EXPLAIN SELECT SQL_NO_CACHE * from emp where age = 45 ORDER BY deptid desc, name desc;#能用上索引,无using filesort
#总结:无论是升序、降序都能用索引,只要保证多个索引的排序均为升序或者均为降序。
EXPLAIN SELECT SQL_NO_CACHE * from emp where age = 45 ORDER BY deptid asc, name desc;#能用上索引,有using filesort
#总结:方向反,必有using filesort排序
四、group by查询优化
group by实质是先排序后进行分组,遵照索引建的最佳左前缀
group by的排序规则与order by相似,只有一点区别。group by无过滤条件,也能用上索引。