暗光增强论文:“EEMEFN: Low-Light Image Enhancement via Edge-Enhanced Multi-Exposure”
暗光增强论文:“EEMEFN: Low-Light Image Enhancement via Edge-Enhanced Multi-Exposure Fusion Network”
摘要
暗光增强的目的:提高图片的亮度,找到暗区所隐藏的图片的信息。
现存的方法有如下三个问题:
(1)低光照的图片一般有较高的对比度。(颜色差异较大)因此现有方法很难复原暗区或者亮区的细节。
(2)和暗光增强大多数问题一样,暗光会导致颜色失真不可复原。
(3)由于物体的边界比较模糊,pixel-wise loss会对不同的物体进行相同的处理,并导致一个模糊的结果。
本论文提出了二阶段的边缘增强的多曝光融合网络(Edge-Enhanced Multi-Exposure Fusion Network)用于极暗图像的增强。
在第一阶段,使用多曝光融合模块来解决高对比度问题和颜色的偏差。本文作者通过原始图像设置不同的曝光时间来合成多张不同的图像,并通过融合多曝光图像中曝光良好的区域重建了一张正常曝光的图像。
在第二阶段,通过边缘增强模块(edge enhancement module),通过提取到的边缘信息来精化原始的图片。
因此,作者认为本文可以重建获得sharp edge的高质量的图像,并在See-In-the-Dark的数据集上取得了不错的效果。
(很奇怪问什么不在LOL Dataset上做?)
Introduction
过去的方法有什么问题?
传统的方法:通过对像素的增强来获得一个更加自然的分布。
深度学习方法:设计较深的网络来恢复高质量的图像。存在以下三个问题:
(1)由于low-light的图像的对比度较高,难以获得一个一对一的映射来恢复极暗和极亮的区域。生成的图像有可能存在噪声或者存在模糊。
(2)由于缺乏well-exposed的图像的信息,可能会受到颜色畸变的干扰。
(3)像素级的loss对图片的空间分布处理是平等的,会导致 l 1 l_1 l1 loss和 l 2 l_2 l2 loss被相邻的像素平均化。生成的图像边界容易模糊,细节也不是很好。
Contributions
(1)提出了一个多曝光融合的网络(multi-exposure fusion, MEF),用于解决高对比度问题和色彩偏差问题。
(2)通过边缘增强网络精化细节。
(3)效果不错。
相关工作
低光照增强
传统算法:直方图均衡化和Retinex增强
直方图均衡化问题:仅考虑逐像素的映射,未考虑像素会受到周边像素的影响。
Retinex-based增强:先预测一个illumination map,并通过这个照明图进行重建。缺点是在有很多噪声的极暗条件下很难预测一个照明图。
深度学习算法
LLNet:对比度增强模块+去噪模块
LLCNN:多尺度的特征图来进行图像增强
Retinex-Net:Decom-Net用于图像分解,Enhance-Net用于光照图的调整。
CAN:模拟若干种的processing operator
边缘检测
(1)通过设置不同的filter来人工获得边缘图:Canny算子等等
(2)通过提取到的边缘信息来设计data-driven模型,比如随机决策森林。
(3)深度学习方法来学习复杂的特征表示。
由于人眼对图片的边缘信息更加敏感,本文希望通过边缘细节的增强来提高复原的效果。
Methodology

Stage-I 多曝光融合
图片生成
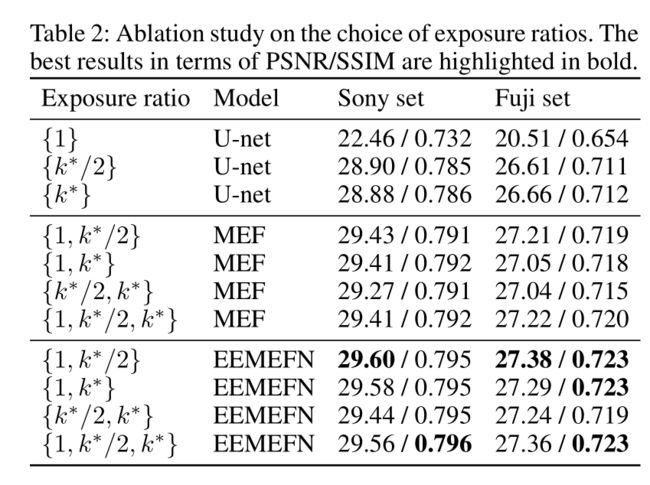
输入一张raw图片 I l o w ∈ R H × W × 1 I_{low}\in\mathbb{R}^{H\times W\times 1} Ilow∈RH×W×1和一系列不同的曝光度值{ k 1 , k 2 , . . . , k N k_1,k_2,...,k_N k1,k2,...,kN}来通过公式 I i = C l i p ( I l o w × k i ) I_i=Clip(I_{low}\times k_i) Ii=Clip(Ilow×ki)从而生成多张曝光度的图片{ I 1 , I 2 , . . . , I N I_1,I_2,...,I_N I1,I2,...,IN}。在Learning-to-see-in-the-dark那篇论文里,作者用了一个特定的exposure ratio k ∗ k^{*} k∗。然而考虑到多曝光图片中的信息冗余,将多张不同的图像引入网络中不一定会提高性能,反而会增强计算的代价。
图像融合
从若干个生成的图片 I = { I 1 , I 2 , . . . , I N } I=\{I_1,I_2,...,I_N\} I={ I1,I2,...,IN}中获得初始图片 I n o r m a l I_{normal} Inormal, I n o r m a l = M E N ( I 0 , I 1 , . . . , I N ) I_{normal}={MEN}(I_0,I_1,...,I_N) Inormal=MEN(I0,I1,...,IN)
首先先将每张图片通过相同结构的U-Net的方式,在不同的尺度中重建细节。
其次,使用融合模块来以互补的方式利用特征中有效的信息。使用了permutation-invariant technique(引用自ECCV 2018的论文,链接http://people.csail.mit.edu/miika/eccv18_deblur,并加强了特征间的聚合。作者认为这些融合模块可以较大程度上复原暗区细节以及校准颜色畸变。输入为{ f 1 , f 2 , . . . , f N ∈ R c × h w f_1,f_2,...,f_N\in\mathbb{R}^{c\times hw} f1,f2,...,fN∈Rc×hw}个特征,其中 f m a x = m a x ( f 1 , f 2 , . . . , f N ) f_{max}=max(f_1,f_2,...,f_N) fmax=max(f1,f2,...,fN) f a v g = ( f 1 + f 2 + . . . + f N ) / N f_{avg}=(f_1+f_2+...+f_N)/N favg=(f1+f2+...+fN)/N
将特征 f m a x f_{max} fmax f a v g f_{avg} favg转换到输入的特征空间并将其送入对应的分支, f = W × [ f m a x , f a v g ] , f ∈ R c × h w , W ∈ R c × 2 c f = W\times[f_{max},f_{avg}],f\in\mathbb{R}^{c\times hw},W\in\mathbb{R}^{c\times 2c} f=W×[fmax,favg],f∈Rc×hw,W∈Rc×2c
最终将最后一层的特征结合在一起,将其送入1x1的卷积层,从而利用融合信息综合的去利用不同分支的信息。
损失函数使用 l 1 l_1 l1损失函数,loss=|| I n o r m a l − I g t I_{normal}-I_{gt} Inormal−Igt|| 1 _1 1

Stage-II 边缘增强网络
边缘检测网络也分为两个模块:检测模块 和 增强模块 。 由于原始的low-light图像的边缘过于不清晰,作者用生成的 I n o r m a l I_{normal} Inormal图像来获得边缘信息;在增强模块中,作者利用检测模块获得的边缘信息去生成更加平滑的色彩,并且减少多余的纹理和尖锐的边缘信息。
检测模块中,作者使用2017年的边缘检测论文来提取一个edge map E。(论文:Richer convolutional features for edge detection)
考虑到边缘信息和非边缘信息的分布是不均衡的,本文设置了两个不同的平衡系数 α \alpha α和 β \beta β,边缘损失函数 E i E_i Ei和Ground Truth E g t = ( e j , j = 1 , 2 , . . , ∣ E g t ∣ ) E_{gt}=(e_j,j=1,2,..,|E_{gt}|) Egt=(ej,j=1,2,..,∣Egt∣),从而定义为一种带权重的交叉熵损失函数
l e d g e ( E i , E g t ) = − α ∑ j ∈ E g t + l o g P r ( e j = 1 ∣ i ) − β ∑ j ∈ E g t − l o g ( 1 − P r ( e j = 1 ∣ i ) ) l_{edge}(E_i,E_{gt})=-\alpha\sum_{j\in E_{gt}^+}log\pmb {Pr}(e_j=1|i)-\beta\sum_{j\in E_{gt}^-}log(1-\pmb {Pr}(e_j=1|i)) ledge(Ei,Egt)=−αj∈Egt+∑logPrPrPr(ej=1∣i)−βj∈Egt−∑log(1−PrPrPr(ej=1∣i))
其中 α = ∣ E g t − ∣ ∣ E g t + ∣ + ∣ E g t − ∣ \alpha=\frac{|E_{gt}^-|}{|E_{gt}^+|+|E_{gt}^-|} α=∣Egt+∣+∣Egt−∣∣Egt−∣, β = ∣ E g t + ∣ ∣ E g t + ∣ + ∣ E g t − ∣ \beta=\frac{|E_{gt}^+|}{|E_{gt}^+|+|E_{gt}^-|} β=∣Egt+∣+∣Egt−∣∣Egt+∣, ∣ E g t + ∣ |E_{gt}^+| ∣Egt+∣和 ∣ E g t − ∣ |E_{gt}^-| ∣Egt−∣代表着边缘信息和非边缘信息的GT label sets,最后将全部的loss function汇总:
l o s s D e t e c t i o n = ∑ i = 1 5 l e d g e ( E i , E g t ) + l e d g e ( E , E g t ) loss_{Detection}=\sum_{i=1}^5l_{edge}(E_i,E_{gt})+l_{edge}(E,E_{gt}) lossDetection=∑i=15ledge(Ei,Egt)+ledge(E,Egt)
增强模块:同样使用U-Net的结构,将多曝光图片 I = { I 1 , I 2 , . . . , I N } I=\{I_1,I_2,...,I_N\} I={ I1,I2,...,IN},合成的initial图片 I i n i t i a l I_{initial} Iinitial 和边缘图E作为输入生成新的增强后的图片 I n o r m a l + I_{normal}^+ Inormal+
I i n i t i a l + = E n h a n c e m e n t ( I , I i n i t i a l , E ) I_{initial}^+=Enhancement(I,I_{initial},E) Iinitial+=Enhancement(I,Iinitial,E)
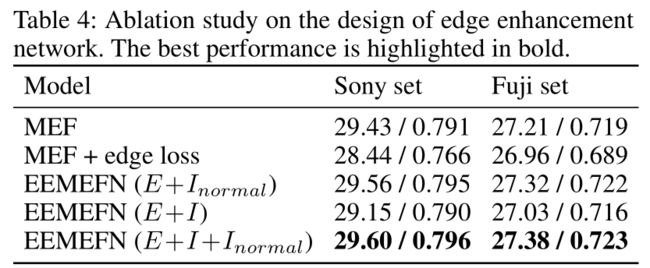
同样使用 l 1 l_1 l1损失函数,本文还试过edge-preserving loss和perceptual loss,然而edge-preserving loss会极大的降低性能,perceptual loss也无法提高效果。
性能比较

消融实验
不同的exposure ratio对应的消融实验结果。
使用不同的融合策略进行融合

不同的损失函数: