Elasticsearch:创建 Ingest pipeline
在 Elasticsearch 针对数据进行分析之前,我们必须针对数据进行摄入。在摄入的过程中,我们需要对数据进行加工,这其中包括非结构化数据转换为结构化数据,数据的转换,丰富,删除,添加新的字段等等一系列的工作。针对目前 Elastic 公司所提供的工具来看,我们有两种方法来针对数据进行加工:Logstash 以及 Ingest pipeline。

这两种方法各有优缺点:
Logstash:
- 是一种开源的 Elastic Stack ETL (Extract, Transform, Load)引擎
- 非常强大,并且有很多的 inputs/filters/outputs 来供我们选择
- 可以很方便地和很多外部的服务进行整合并进行数据丰富
- 必须在 JVM 环境中运行
- 缺点是比较难以扩展,资源消耗比较大,通常需要专有的服务器来完成
Ingest pipeline:
- 由专门的 Elasticsearch ingest node 来完成
- 可以很方便地进行扩展
- 支持很多的 processors
在今天的文章中,我们将介绍如何创建一个 ingest pipeline。如果你对 pipeline 还不是很熟的话,请参阅我之前的文章:
-
如何在 Elasticsearch 中使用 pipeline API 来对事件进行处理
-
Elasticsearch:Elastic可观测性 - 数据结构化及处理
我将着重介绍如何使用 Kibana UI 来创建一个 ingest pipeline。在 Kibana 中,它提供了一个 UI 来对我们的 pipeline 进行管理,你可以:
- 查看已经存在的所有 pipeline
- 删除/编辑已经存在的 pipeline
- 创建新的 pipeline
- 用一些定制的文档来测试你的 pipeline
展示
我们首先打开 Kibana 界面:
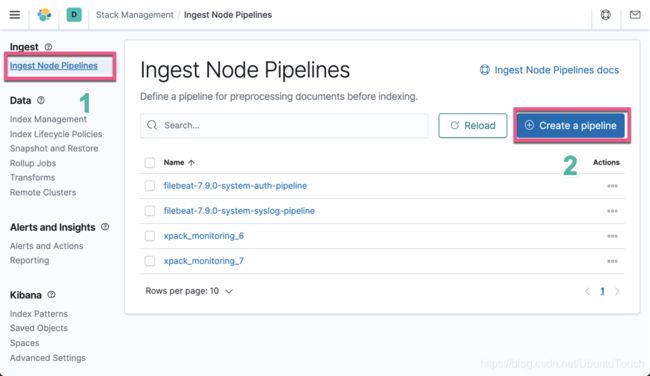
如上图所示,它展示了目前我们已经创建好的 pipeline。大家也许很好奇,你没有创建上面的 filebeat 为开头的 pipeline,但是为什么上面有显示呢?这些 filebeat 的 pipeline 是我们在使用 filebeat setup 命令时生成的。具体可以参照我之前的教程 “Beats 入门教程 (二)”。
点击上面的 “Create a pipeline” 按钮:
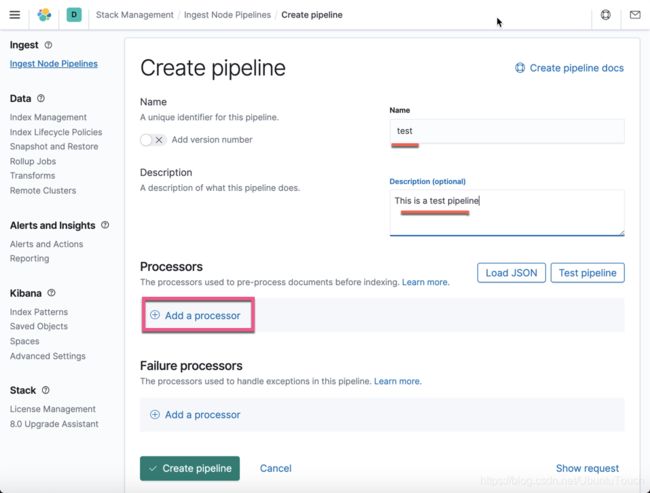
我们填入相应的信息,并点击 Add a processor:
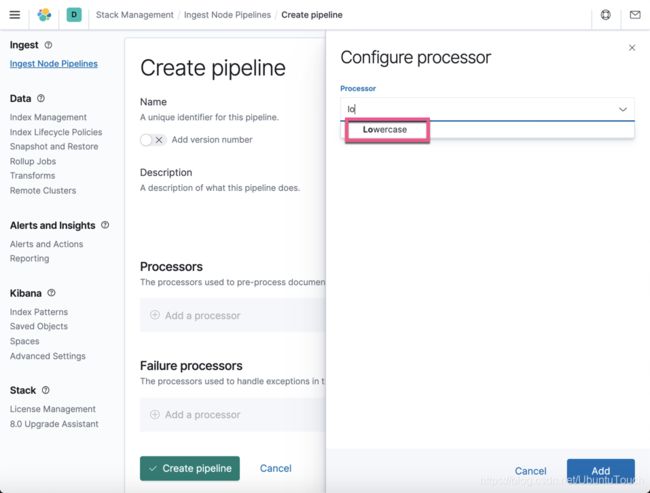
我们选择 Lowercase processor:
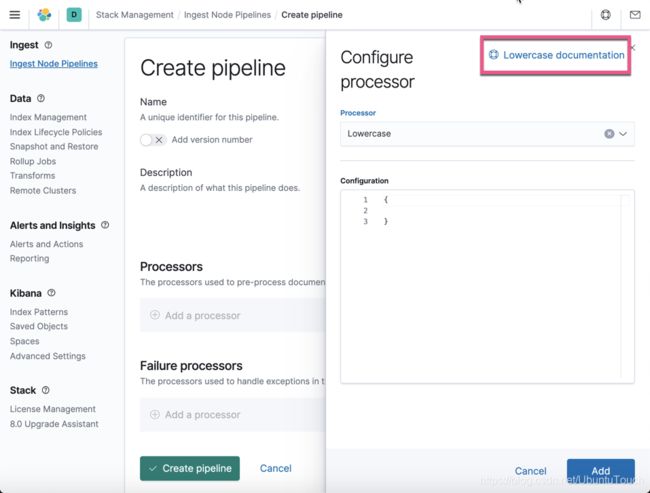
如果我们对 Lowercase processor 的用法不是很熟的话,我们可以点击右上角的链接去寻找更多的帮助信息:

针对我们的情况,我们对 Lowercase processor 进行如下的配置:
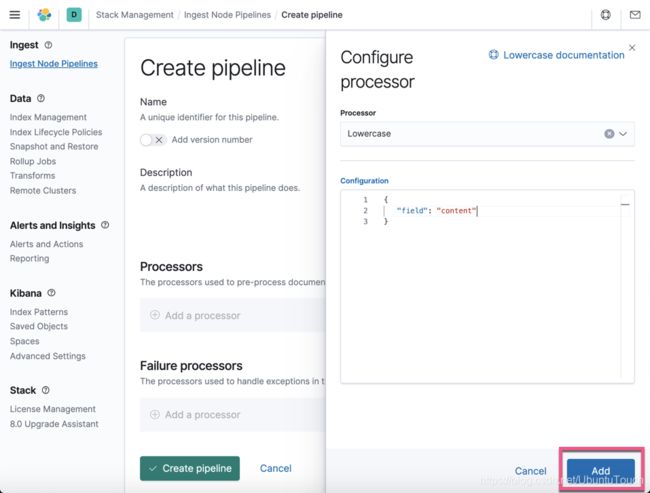
我们想针对文档中的 content 字段进行转换。点击上面的 Add:

从上面,我们可以看出来我们已经成功地创建了一个 Lowercase 的 processor。接下来,我们可以针对这个 processor 进行测试。点击 Test pipeline:
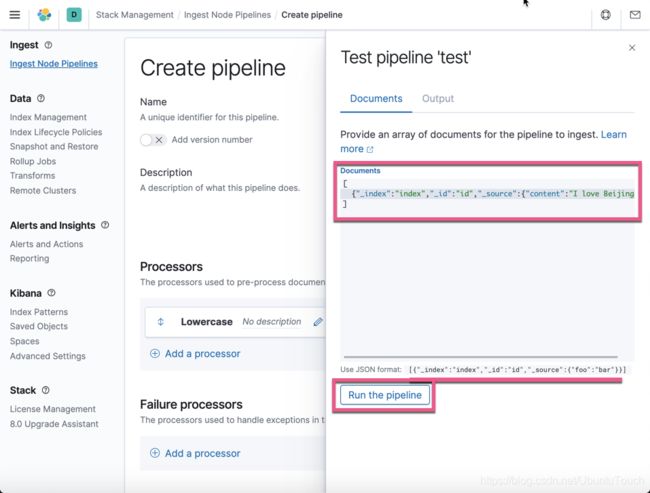
按照上面的提示,我们输入相应的文档格式,并点击上面的 Run the pipeline:

上面显示,content 字段的内容现在都变为小写的了。我们之前的文字是 "I love Beijing”。这证明了这个 Lowercase 的 processor 是工作正常的。
接下来,我们添加另外一个叫做 split 的 processor,并把句子按照空格进行分开并形成 token。按照同样的方法:
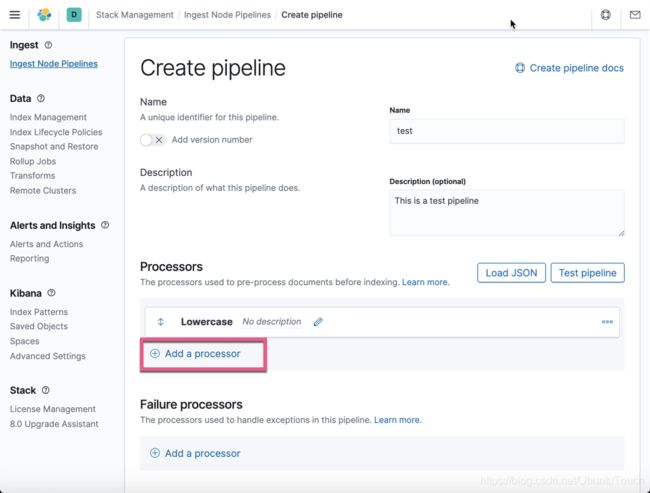
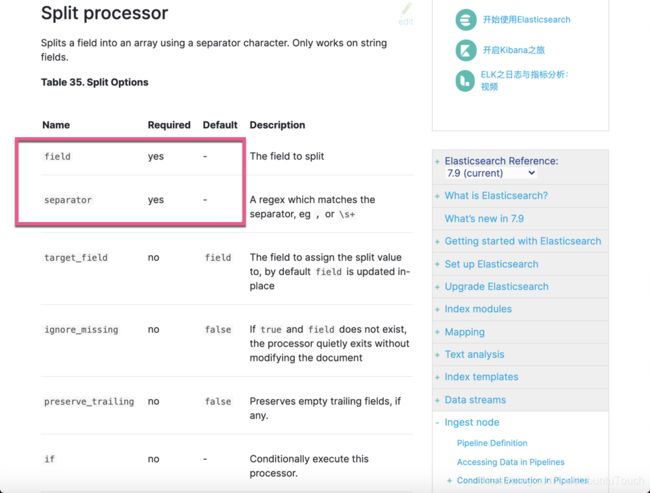
我们可以看到 field 以及 separator 是必选项:

我们填入上面的信息,并点击 Add 按钮:
从上面,我们可以看出来有一个新生成的 Split processor。我们点击上面的 Test pipeline 按钮:
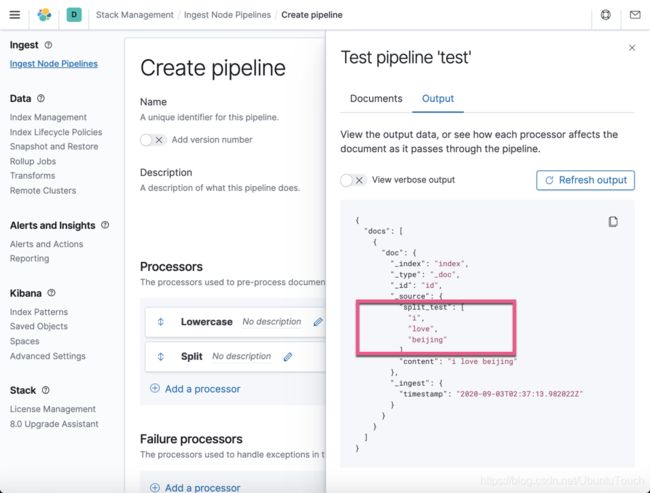
显然,我们可以看到被分解的 token: i, love, beijing。它们被置于target_field 所定义的 split_test 字段中。这说明了,我们的 Split processor 是正确的。我们可以使用一些其它的文档来进行测试:
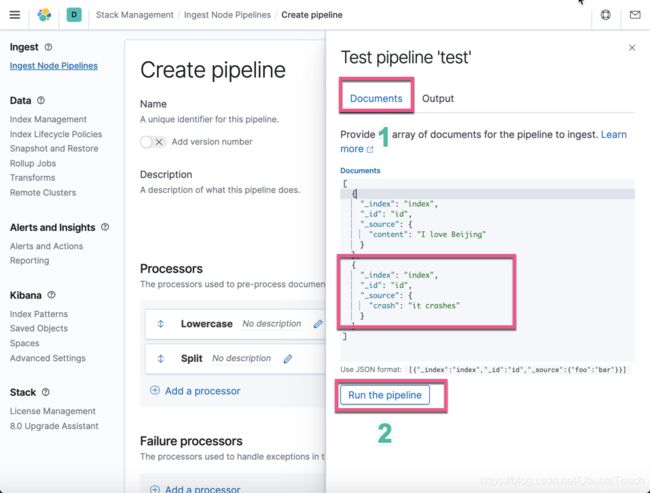
在上面我们添加了另外一个文档。这个文档没有所需要的 content 字段。我们点击 Run the pipeline:
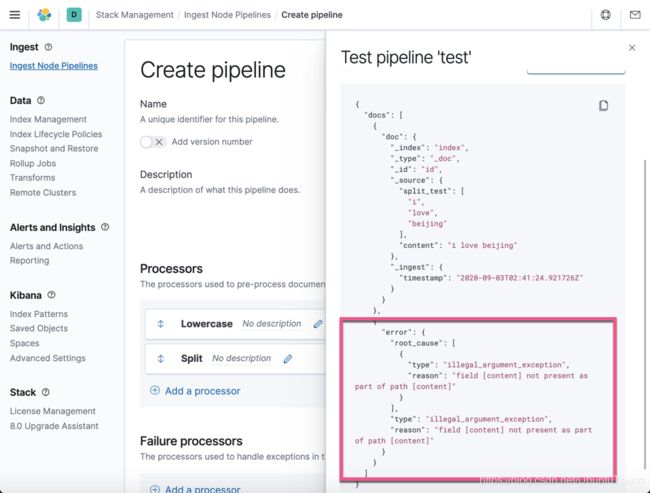
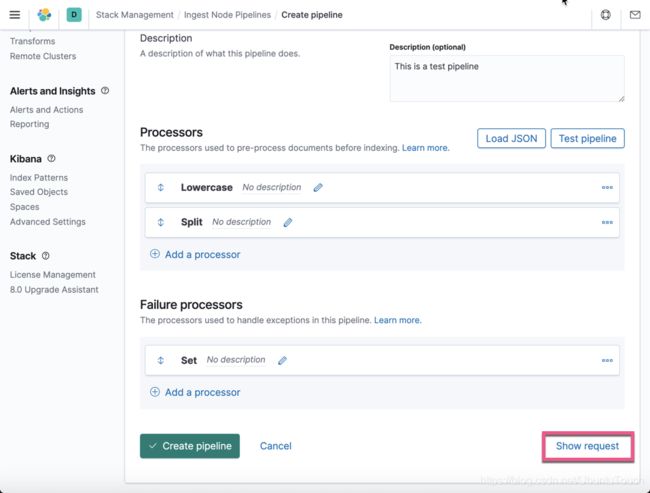
显然这次,我们看到了错误的信息。上面也显示了错误的信息。那么我们该如何来捕获这种错误呢?我们回到定义 processor 的界面,并在 Failure processors 里添加新的 processor:


在上面,我们选择 set processor,并配置相应的信息。点击 Add 按钮:
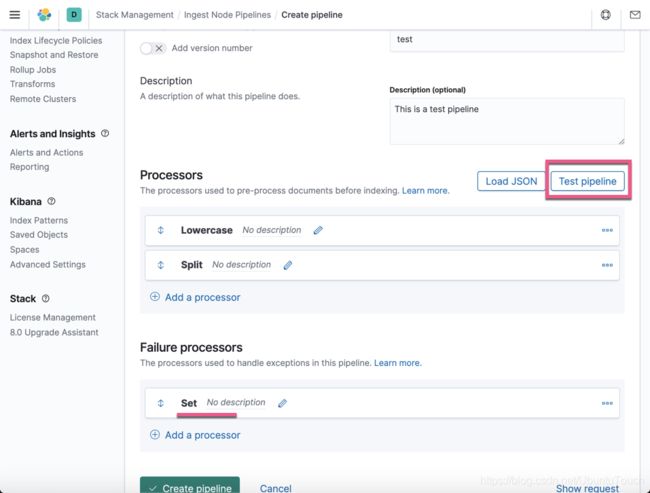
从上面,我们可以看出来有一个 set 的 processor 在 Failure processors 下面。点击测试按钮:
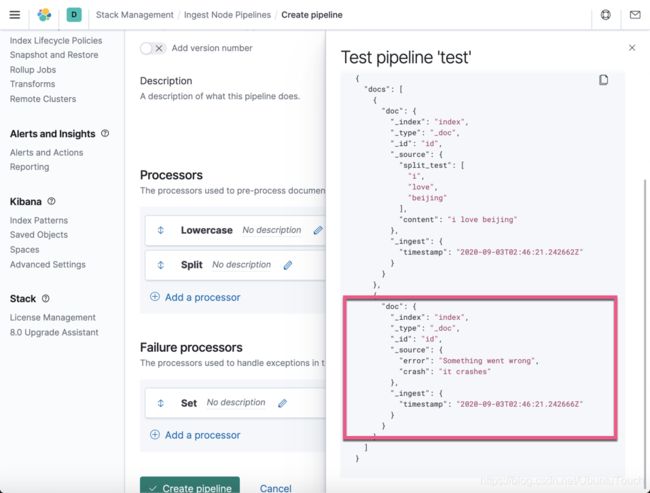
这个时候,我们可以看到已经被捕获的信息,并在 error 字段里显示出来了。
创建一个 ingest pipeline 的工作基本已经完成了。也许你想知道,我改如何来使用 API 来创建同样的 pipeline 呢?我们点击界面下的 show request 链接:
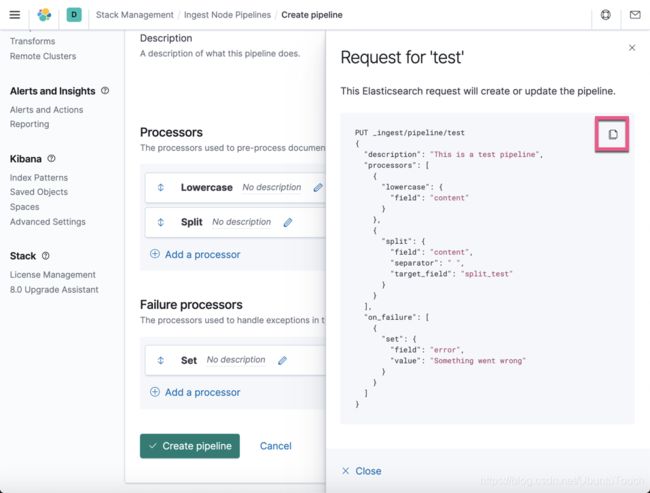
上面显示了整个创建这个 pipeline 的 API 命令。你可以点击那个拷贝的按钮进行拷贝操作,并在 Dev Tools 中进行测试。