不时的ora-16146的小惊心
操作系统:阿里云ecs
数据库:Oracle 11.2.0.1 ADG
前提:每天早上6点要进行数据库的rman备份
早上巡检发现今天(04-18)早上6点到7点的Elapsed Time是285
17415 2017-04-18 06:00:02 2017-04-18 07:00:43 2.2273E+13 2.2256E+13 285.677088而平时的Elapsed Time很少
17391 2017-04-17 06:00:49 2017-04-17 07:00:53 2.2045E+13 2.2045E+13 1.03215108怎么突然就变化这么大,然后就查看了对应的alert日志:
主库的alert报了ora-16146的错:
LNS: Standby redo logfile selected for thread 1 sequence 13431 for destination LOG_ARCHIVE_DEST_2
Archived Log entry 26856 added for thread 1 sequence 13430 ID 0xb3561577 dest 1:
Tue Apr 18 06:37:58 2017
Errors in file **/home/dbserver/oracle/diag/rdbms/ptopdb/ptopdb/trace/ptopdb_arc2_20166.trc:
ORA-16146: control file enqueue unavailable**
Tue Apr 18 06:45:26 2017
ALTER SYSTEM ARCHIVE LOG
Tue Apr 18 06:45:26 2017
Thread 1 advanced to log sequence 13432 (LGWR switch)
Current log# 1 seq# 13432 mem# 0: /dbdata/ptopdb/ptopdb_u01/ptopdb/redo01.log
Archived Log entry 26858 added for thread 1 sequence 13431 ID 0xb3561577 dest 1:
Tue Apr 18 06:45:27 2017
LNS: Standby redo logfile selected for thread 1 sequence 13432 for destination LOG_ARCHIVE_DEST_2从库没有明显的异常:
Tue Apr 18 06:03:58 2017
RFS[2]: Selected log 5 for thread 1 sequence 13431 dbid -1286252169 branch 877806585
Tue Apr 18 06:03:58 2017
Media Recovery Waiting for thread 1 sequence 13431 (in transit)
Recovery of Online Redo Log: Thread 1 Group 5 Seq 13431 Reading mem 0
Mem# 0: /dbdata/ptopdb/ptopdb_u01/ptopdb/stby05.log
Tue Apr 18 06:03:58 2017
Archived Log entry 7346 added for thread 1 sequence 13430 ID 0xb3561577 dest 1:
Tue Apr 18 06:45:27 2017
RFS[2]: Selected log 4 for thread 1 sequence 13432 dbid -1286252169 branch 877806585
Tue Apr 18 06:45:27 2017
Archived Log entry 7347 added for thread 1 sequence 13431 ID 0xb3561577 dest 1:
Tue Apr 18 06:45:27 2017
Media Recovery Waiting for thread 1 sequence 13432 (in transit)
Recovery of Online Redo Log: Thread 1 Group 4 Seq 13432 Reading mem 0并且数据库也没有发生gap或者延迟的情况:
SQL> select name,value,datum_time from v$dataguard_Stats;
NAME VALUE DATUM_TIME
-------------------------------- ---------------------------------------------------------------- ------------------------------
transport lag +00 00:00:00 04/18/2017 09:11:31
apply lag +00 00:00:00 04/18/2017 09:11:31
apply finish time +00 00:00:00.000
estimated startup time 15然后就打算收集一下4-18早上6-7点和4-17早上6-7点的对比awr报告查看一下原因:

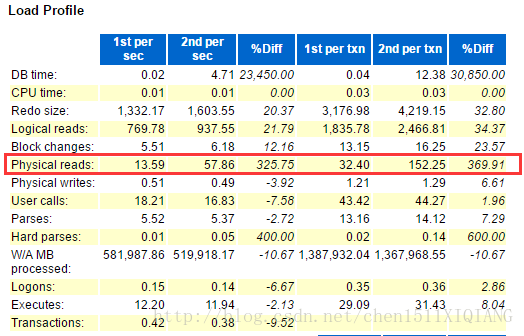

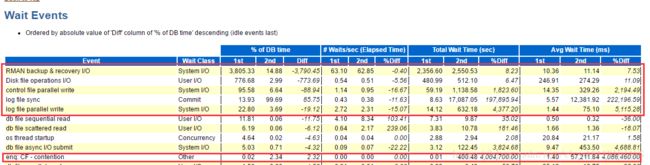
从对比awr报告分析看到出现问题的报告中物理读很高,等待事件是log file sync并非是正常的是RMAN backup,enq:CF-contention,controlfile parallel write,log file parallel write和正常时间段的等待时间差别很大。
然后我们再看对应时间段的ash看看有没有 什么表现:

对应的时间段内出现了大量的log file sync等待事件,出现enq:CF-contention,controlfile parallel write,log file parallel write等,阻塞的会话是1和697,再来看看1和697会话是在干什么
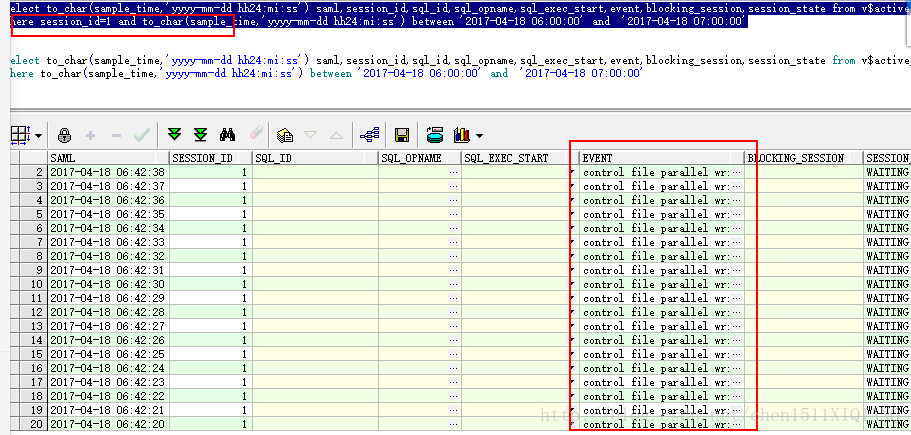
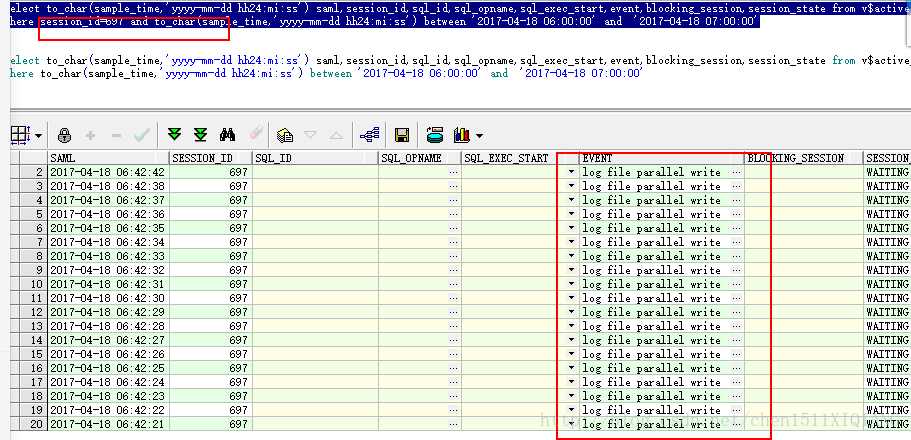
可以看到1和697会话正是在等待controlfile parallel write,log file parallel write,也就是说正在进行控制文件和redo的大量写操作。
也就是说很有可能是由于redo写操作和控制文件写操作的缓慢导致会话持有控制文件的队列锁超时报错。
然后查看了mos:Ora-16146: Standby Destination Control File Enqueue Unavailable (文档 ID 1181717.1)
随便报错少了 Standby Destination,但是现象和mos描述也相对吻合。
**Ora-16146: Standby Destination Control File Enqueue Unavailable (文档 ID 1181717.1)**
In this Document
Symptoms
Cause
Solution
References
APPLIES TO:
Oracle Database - Enterprise Edition - Version 10.1.0.5 to 12.1.0.2 [Release 10.1 to 12.1]
Information in this document applies to any platform.
This affects a primary database with physical or logical standby database.
***Checked for relevance on 13-Jul-2015***
SYMPTOMS
There is a Primary Database with a Physical Standby Database.
The ORA-16146 error happened on the Primary Database.
Tue Aug 17 11:14:20 2010
Thread 1 advanced to log sequence 52410 (LGWR switch)
Current log# 6 seq# 52410 mem# 0: /orap/04/oradata/gfprod/redo06a.log
Current log# 6 seq# 52410 mem# 1: /orap/05/oradata/gfprod/redo06b.log
Tue Aug 17 11:15:02 2010
ARC8: Standby redo logfile selected for thread 1 sequence 52409 for destination LOG_ARCHIVE_DEST_2
Tue Aug 17 11:17:16 2010
Thread 1 advanced to log sequence 52411 (LGWR switch)
Current log# 5 seq# 52411 mem# 0: /orap/04/oradata/gfprod/redo05a.log
Current log# 5 seq# 52411 mem# 1: /orap/05/oradata/gfprod/redo05b.log
Tue Aug 17 11:20:26 2010
Errors in file /orap/01/app/oracle/admin/gfprod/bdump/gfprod_arc4_1036.trc:
ORA-16146: standby destination control file enqueue unavailable
Tue Aug 17 11:20:35 2010
Thread 1 advanced to log sequence 52412 (LGWR switch)
Current log# 1 seq# 52412 mem# 0: /orap/04/oradata/gfprod/redo01a.log
Current log# 1 seq# 52412 mem# 1: /orap/05/oradata/gfprod/redo01b.log
Tue Aug 17 11:20:36 2010
ARC1: Standby redo logfile selected for thread 1 sequence 52410 for destination LOG_ARCHIVE_DEST_2
Tue Aug 17 11:23:35 2010
Errors in file /orap/01/app/oracle/admin/gfprod/bdump/gfprod_arc4_1036.trc:
ORA-16146: standby destination control file enqueue unavailable
CAUSE
The message of ORA-16146 is misleading. It is not necessary to be standby CF enqueue contention and It is actually primary CF enqueue contention.
The issue was some process held CF enqueue for more than 900 seconds and other process(es) who requested CF enqueue couldn't get it within
900 seconds and that resulted ORA-16146.
The long archive log history in the controlfile could cause the issue as it would take long time to retrieve the archive log infomation from the controlfile
so that CF enqueue was held longer than normal and resuted ORA-16146.
The large value of CONTROL_FILE_RECORD_KEEP_TIME could cause the long history of archive log in the controlfile. CONTROL_FILE_RECORD_KEEP_TIME =30
specifies the minimum number of days before a reusable record in the control file can be reused.
Primary DB
SQL>select count(*) from v$archived_log;
COUNT(*)
----------
11020
SQL>select count(*) from v$log_history;
COUNT(*)
----------
3630
Standby DB
SQL> select count(*) from v$archived_log; COUNT(*) ---------- 11020 SQL> select count(*) from v$log_history; COUNT(*) ---------- 3630 CONTROL_FILE_RECORD_KEEP_TIME = 30 was set on both the primary and the standby databases. SOLUTION Set CONTROL_FILE_RECORD_KEEP_TIME to a lower value on both the primary and the standby databases. The default value of CONTROL_FILE_RECORD_KEEP_TIME is 7 (days) which is enough for most of cases. Please refer to the note below: Note.397269.1 Ext/Pub Relation between RMAN retention period and control_file_record_keep_time Note.1060139.6 Ext/Pub How to Clean-Up Entries in V$LOG_HISTORY, V$ARCHIVED_LOG Or recreate the primary controlfile and then create a new standby controlfile from the new primary controlfile. 解释一下就是:
ORA-16146错误说明有进程持有CF enqueue(控制文件锁) 超过900秒没有释放,导致其他进程无法获得CF enqueue,
其实这个错误信息有些不够准确,不单单是等待备库的CF enqueue,等待主库的CF enqueue时也会报这个错误。
导致ORA-16146错误的原因可能有:
1. IO性能慢,导致IO操作时间过长。
2. 某个持有CF enqueue(控制文件锁) 超过900秒没有释放。
3. 控制文件中的信息过多,导致查询控制文件时间过长。
4. 如果只是单纯出现ORA-16146,而没有其他问题,那么这个错误是可以忽略的
然后检查一下mos提供的语句:
主库:
SQL> select count(*) from v$archived_log;
COUNT(*)
----------
1120
SQL> select count(*) from v$log_history;
COUNT(*)
----------
584备库:
SQL> select count(*) from v$archived_log;
COUNT(*)
----------
1120
SQL> select count(*) from v$log_history;
COUNT(*)
----------
584分析解决
通过查询试图 v archivedlog和v log_history,发现大量历史日志信息,因此很有可能是由于控制文件中记录的日志数量是非常多的,
查询时会消耗比较多的时间。
由于之前默认数据库的CONTROL_FILE_RECORD_KEEP_TIME,
本打算修改参数如下:
alter system set CONTROL_FILE_RECORD_KEEP_TIME=3 scope=BOTH;
但是由于也不是经常出现如上的报错信息,也考虑到控制文件信息的重要性,没有进行按照mos的方式进行修改,不过也明白了出现如此报错的原因,并且有处理的方式,不过需要进行权衡才能进行修改!!!