【推荐系统】协同过滤之基于用户的最近邻推荐
1.算法简介
协同过滤(collaborative filtering)的核心思想:利用其他用户的行为来预测当前用户。协同过滤算法是推荐系统中最基本的,同时在业界广为使用。根据使用的方法不同,可以分为基于用户(user-based)、基于物品(item-based)的最近邻推荐。
基于用户的最近邻推荐的主要思想与kNN有点相似:对于一个给定的评分集,找出与当前用户u口味相近的k个用户;然后,对于用户u没有见过的物品p,利用k个近邻对p进行预测评分。由此引出了两个问题,一是如何度量用户与用户间的相似性(涉及到相似性度量),二是如何进行预测。
相似性度量
常见的用于推荐的相似性度量:Pearson相关系数、余弦相似度、改进的余弦相似度。pearson相关系数用来描诉两组向量一同变化的趋势,取值从+1(强正相关)到-1(强负相关)。用户a和用户b的相似度
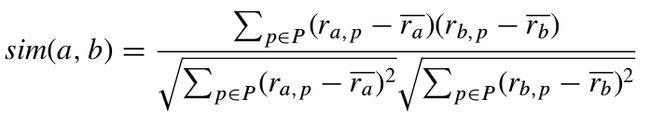
其中, 表示用户a对物品p的评分,
表示用户a对物品p的评分, 表示用户a的平均评分。Pearson相关系数越接近于1,则说明用户a、b越相似。但Pearson相关系数存在着下列缺陷:
表示用户a的平均评分。Pearson相关系数越接近于1,则说明用户a、b越相似。但Pearson相关系数存在着下列缺陷:
- 未考虑重叠物品项的数量对相似度的影响
比如:①用户a与用户b有2个重叠项;②用户a与用户c有10个重叠项,且Pearson相关系数小于①。但这并不能说明用户b比用户c更相似于用户b,因为用户的口味(或者说是偏好)是通过一定数量的物品评分反映出来的。过少的重叠项不能用于计算相似度。
- 如果只有一个重叠项,或重叠项的评分相等,则无法计算Pearson相关系数
在此种情况下,方差为0;由于Pearson相关系数的分母为方差相乘,即为0,0除0无法计算。
余弦相似度定义为向量之间夹角的余弦
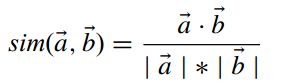
基本的余弦方法没有考虑用户的平均评分。针对这个问题,改进余弦相似度
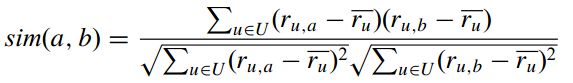
取值在-1到+1之间,与Pearson相关系数一样。
预测评分
先选取k个用户的近邻,利用这k个近邻的评分数据来做预测。对物品p,具体做法是对近邻中给物品p的评分做加权平均;预测用户a对物品p的评分:

其中,N为近邻的集合。
2. 实战
本文采用GoupLens研究组的电影评分MovieLens数据集,MovieLens数据集共有3种,本文选的是ml-100k。
为了便于统计哪些用户对同一部电影进行了评分,我们建立电影-用户的倒排表:输入电影id,输出给过评分的用户。扫描倒排表,即可得到用户间的交互行为。
读取文件,建立词典
import scipy.spatial.distance as ssd
from texttable import Texttable
def getMovieList(item_file):
"""读取u.item文件,获取电影列表: movies[mid]=mtitle
"""
movies = dict()
f = open(item_file)
for raw_item in f.readlines():
item = raw_item.split('|')
movies[item[0]] = item[1]
return movies
def getRatingsInfo(data_file):
"""读取u.data文件,获取三个词典
用户-电影的评价信息: ratings[uid][mid]=(rating)
用户的平均评分: avgrating[mid]=average_rating
电影-用户的倒排表: movieTouser[mid]=(uid)
"""
ratings = dict()
avgratings = dict()
movieTouser = dict()
f=open(data_file)
for raw_data in f.readlines():
data = raw_data.split('\t')
#用户-电影词典
if data[0] not in ratings:
ratings[data[0]] = {}
ratings[data[0]][data[1]] = int (data[2])
#电影-用户的倒排表
if data[1] not in movieTouser:
movieTouser[data[1]] = []
movieTouser[data[1]].append(data[0])
#用户的平均评分
for u, movies in ratings.items():
avgratings[u] = 0
for mid, rating in movies.items():
avgratings[u] += rating
avgratings[u] /= float (len(ratings[u]))
return ratings, movieTouser, avgratings计算用户间的相似度,因为Pearson相关系数容易出现分母为0的情况,这里采用cosine作为相似度度量。考虑到重叠项数量的影响,如果重叠项少于5个,则相似度取接近于0
def calcSimilarity(ratings, u1, u2, args = 5):
"""计算用户u1 u2的相似度"""
ratings_u1=[]; ratings_u2=[]
for mid1, rating1 in ratings[u1].items():
for mid2, rating2 in ratings[u2].items():
if mid1 == mid2:
ratings_u1.append(rating1)
ratings_u2.append(rating2)
if len(ratings_u1) < args: #如果重叠项少于5个,相似度取接近于0
return 0.001
return ssd.cosine(ratings_u1, ratings_u2)寻找用户u的k近邻。为了避免依次扫描每个用户,只把与用户u发生过交互行为的用户列为可能的近邻(所谓交互行为,即给过同一部电影评分);计算出与用户最相似的k个用户。
def kNearestNeighbor(ratings, movieTouser, user, k):
"""寻找用户user的k个近邻"""
neighbors = []
#如果用户neighbor与用户user都看过一部电影
#那么将用户neighbor看作可能的近邻
for mid, rating in ratings[user].items():
for neighbor in movieTouser[mid]:
if neighbor != user and neighbor not in neighbors:
neighbors.append(neighbor)
dis = dict()
for neighbor in neighbors:
dis[neighbor] = calcSimilarity(ratings, user, neighbor)
return sorted(dis.items(), key = lambda dic: dic[1], reverse = True)[:k]协同过滤。用户u对电影p是否感兴趣,需要有一个度量来衡量。本文做了简化处理:如果对电影p的评分高于用户u的平均评分,则说明用户u对电影p感兴趣。
def predictRating(user, mid, sorted_dis, ratings, avgratings):
"""预测用户user对电影mid的评分"""
pred = avgratings[user]
numerator = 0.0; denominator = 0.0
for neighbor, dis in sorted_dis:
if mid in ratings[neighbor]:
numerator += dis*(ratings[neighbor][mid] - avgratings[neighbor])
denominator += dis
pred += numerator/denominator
return pred
def userBasedCF(movies, ratings, avgratings, movieTouser, user, k = 20):
"""基于用户的协同过滤"""
recommendList = []; usedList = []
sorted_dis = kNearestNeighbor(ratings, movieTouser, user, k)
for neighbor, dis in sorted_dis:
for mid, rating in ratings[neighbor].items():
#剪枝:用户看过的电影,或已经推荐过的电影
if mid not in ratings[user].items() and mid not in usedList:
pred = predictRating(user, mid, sorted_dis, ratings, avgratings)
if pred > avgratings[user]:
recommendList.append((mid,round(pred,2)))
usedList.append(mid)
recommendList.sort(key = lambda x:x[1], reverse = True)
return recommendList
"""测试与结果可视化"""
if __name__ == "__main__":
#读取数据集,生成字典
movies = getMovieList("u.item")
ratings, movieTouser, avgratings = getRatingsInfo("u.data")
recomMovies = userBasedCF(movies, ratings, avgratings, movieTouser, '2')[:15]
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(['t', # text
't']) # float (decimal)
table.set_cols_align(["l", "l"])
rows=[]
rows.append([u"recommended movie",u"predicted rating"])
for mid, pred in recomMovies:
rows.append([movies[mid], pred])
table.add_rows(rows)
print table.draw()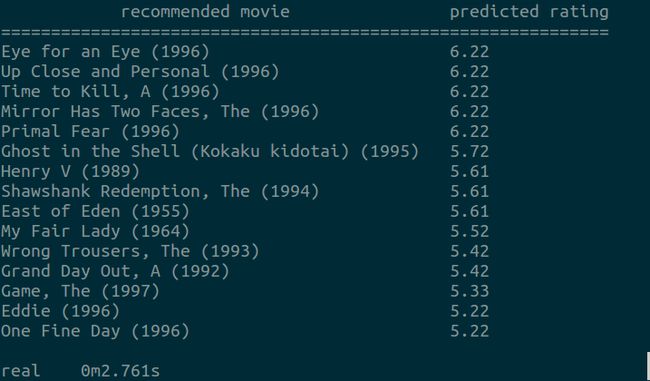
代码参考了[2],存在着问题:预测的评分大于5,在数据集中最高评分==5。
3.Referrence
[1] Dietmar Jannach, et al., Recommender systems : an introduction.
[2] ygrx,[推荐算法]基于用户的协同过滤算法.
[3] Pearson 相关系数--最佳理解及相关应用.