redis压缩列表(节点插入-----代码学习)
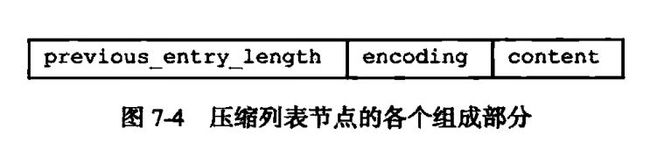
在压缩列表的数据结构设计中,
一个节点在previous_entry_length字段保存了前一节点的长度,
在encoding保存当前节点的长度,
在content保存数据内容。
函数学习static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen)
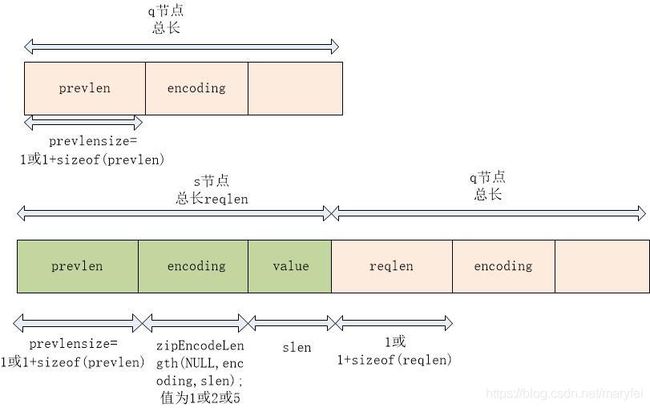
在p节点之前插入s,需要解析p的previous_entry_length,s的previous_entry_length,encoding,总长。
也就有了decode,encode过程。
一、DECODE:
将 p 节点的内容存入新节点 e 中。
依据指针p的内容,填写previous_entry_length字段,方法是通过p【0】大小,判断出prevrawlensize, prevrawlen的值,其中prevrawlensize是previous_entry的长度,prevrawlen是previous_entry的内容
static zlentry zipEntry(unsigned char *p) {
zlentry e;
ZIP_DECODE_PREVLEN(p, e.prevrawlensize, e.prevrawlen);
ZIP_DECODE_LENGTH(p + e.prevrawlensize, e.encoding, e.lensize, e.len);
e.headersize = e.prevrawlensize + e.lensize;
e.p = p;
return e;
}
typedef struct zlentry {
unsigned int prevrawlensize, prevrawlen;
unsigned int lensize,len;
unsigned int headersize;
unsigned char encoding;
unsigned char *p;
} zlentry;define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
(prevlen) = (ptr)[0]; \
} else if ((prevlensize) == 5) { \
assert(sizeof((prevlensize)) == 4); \
memcpy(&(prevlen), ((char*)(ptr)) + 1, 4); \
memrev32ifbe(&prevlen); \
} \
} while(0);#define ZIP_BIGLEN 254
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \
if ((ptr)[0] < ZIP_BIGLEN) { \
(prevlensize) = 1; \
} else { \
(prevlensize) = 5; \
} \
} while(0)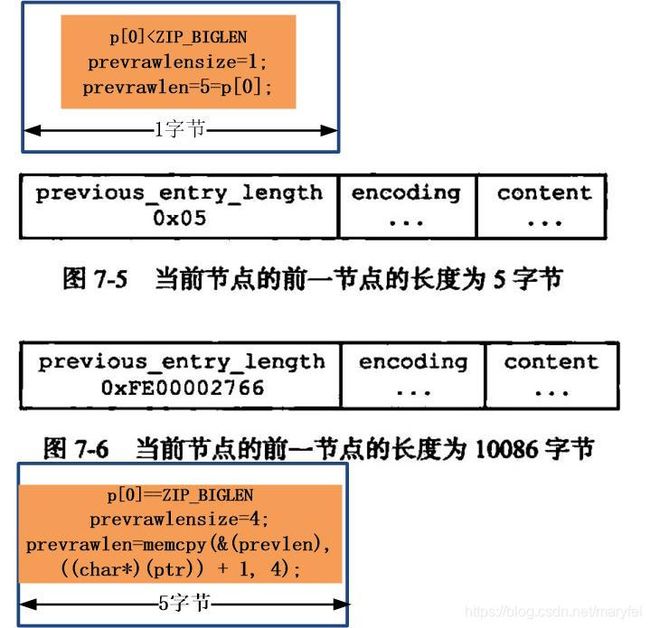
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do {
ZIP_ENTRY_ENCODING((ptr), (encoding));
if ((encoding) < ZIP_STR_MASK) {
if ((encoding) == ZIP_STR_06B) {
(lensize) = 1;
(len) = (ptr)[0] & 0x3f;
} else if ((encoding) == ZIP_STR_14B) {
(lensize) = 2; //2字节情况,6位+8位存储长度
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1];
} else if (encoding == ZIP_STR_32B) {
(lensize) = 5; //首字节不存长度,从ptr[1]开始高位
(len) = ((ptr)[1] << 24) | //到低位依次计算
((ptr)[2] << 16) |
((ptr)[3] << 8) |
((ptr)[4]);
} else {
assert(NULL);
}
} else {
(lensize) = 1;
(len) = zipIntSize(encoding);
}
} while(0);
#define ZIP_STR_06B (0 << 6) //0000 0000
#define ZIP_STR_14B (1 << 6) //0100 0000
#define ZIP_STR_32B (2 << 6) //1000 0000表中为字节数组编码。上面的程序实现了表中编码向长度的转换。1字节,2字节,5字节三种。

2、ENCODE:
reqlen是content的长度,即实际存入的内容的长度,为了计算新增节点的长度,需要通过content的长度,填写头部previous_entry_length, encoding两个字段。由于在p节点之前插入s节点,计算s节点的总长度时,用到下面两个函数。
1、zipPrevEncodeLength
由于在p节点之前插入s节点,因此这个previous_entry_length沿用p节点的prevlen,是现成的。计算出了previous_entry_length占位。是1字节,或者5字节。
unsigned int prevlensize, prevlen = 0;
sizeof(prevlen)==4;(由数据类型决定)
2、zipEncodeLength
通过s节点的数据长度,计算出encoding字段长。
unsigned int prevlensize, prevlen = 0;
reqlen += zipPrevEncodeLength(NULL,prevlen);
reqlen += zipEncodeLength(NULL,encoding,slen);static unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1;
} else {
if (len < ZIP_BIGLEN) {
p[0] = len;
return 1;
} else {
p[0] = ZIP_BIGLEN;
memcpy(p+1,&len,sizeof(len));
memrev32ifbe(p+1);
return 1+sizeof(len);
}
}static unsigned int zipEncodeLength(unsigned char *p, unsigned char encoding, unsigned int rawlen) {
unsigned char len = 1, buf[5];
if (ZIP_IS_STR(encoding)) {
/* Although encoding is given it may not be set for strings,
* so we determine it here using the raw length. */
if (rawlen <= 0x3f) {
if (!p) return len;
buf[0] = ZIP_STR_06B | rawlen;
} else if (rawlen <= 0x3fff) {
len += 1;
if (!p) return len;
buf[0] = ZIP_STR_14B | ((rawlen >> 8) & 0x3f);
buf[1] = rawlen & 0xff;
} else {
len += 4;
if (!p) return len;
buf[0] = ZIP_STR_32B;
buf[1] = (rawlen >> 24) & 0xff;
buf[2] = (rawlen >> 16) & 0xff;
buf[3] = (rawlen >> 8) & 0xff;
buf[4] = rawlen & 0xff;
}
} else {
/* Implies integer encoding, so length is always 1. */
if (!p) return len;
buf[0] = encoding;
}
/* Store this length at p */
memcpy(p,buf,len);
return len;
}s变成的p的前一节点,nextdiff是previous_entry_length的变化。
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
static int zipPrevLenByteDiff(unsigned char *p, unsigned int len) {
unsigned int prevlensize;
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
return zipPrevEncodeLength(NULL, len) - prevlensize;
}
zl扩展后,找回p指针。
/* Store offset because a realloc may change the address of zl. */
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;之后进行移位。(这里不明白,我觉得应该是 memmove(p+reqlen+nextdiff,p,curlen-offset-1+nextdiff);)
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);Ending
最后放一个看不懂的函数,以备以后理解。不明白这里overflow的判断条件。
if (v > (ULLONG_MAX / 10)) /* Overflow. */
return 0;
v *= 10;
if (v > (ULLONG_MAX - (p[0]-'0'))) /* Overflow. */
int string2ll(const char *s, size_t slen, long long *value) {
const char *p = s;
size_t plen = 0;
int negative = 0;
unsigned long long v;
if (plen == slen)
return 0;
/* Special case: first and only digit is 0. */
if (slen == 1 && p[0] == '0') {
if (value != NULL) *value = 0;
return 1;
}
if (p[0] == '-') {
negative = 1;
p++; plen++;
/* Abort on only a negative sign. */
if (plen == slen)
return 0;
}
/* First digit should be 1-9, otherwise the string should just be 0. */
if (p[0] >= '1' && p[0] <= '9') {
v = p[0]-'0';
p++; plen++;
} else if (p[0] == '0' && slen == 1) {
*value = 0;
return 1;
} else {
return 0;
}
while (plen < slen && p[0] >= '0' && p[0] <= '9') {
if (v > (ULLONG_MAX / 10)) /* Overflow. */
return 0;
v *= 10;
if (v > (ULLONG_MAX - (p[0]-'0'))) /* Overflow. */
return 0;
v += p[0]-'0';
p++; plen++;
}
/* Return if not all bytes were used. */
if (plen < slen)
return 0;
if (negative) {
if (v > ((unsigned long long)(-(LLONG_MIN+1))+1)) /* Overflow. */
return 0;
if (value != NULL) *value = -v;
} else {
if (v > LLONG_MAX) /* Overflow. */
return 0;
if (value != NULL) *value = v;
}
return 1;
}
/* Convert a string into a long. Returns 1 if the string could be parsed into a
* (non-overflowing) long, 0 otherwise. The value will be set to the parsed
* value when appropriate. */