pyquery 是python仿照jQuery的严格实现,语法与jQuery几乎完全相同,所以对于学过前端的朋友们可以立马上手,没学过的小朋友也别灰心,我们马上就能了解到pyquery的强大.
pip install pyquery
2 官方文档
http://pyquery.readthedocs.io/
3 学习代码html代码
html = ''''''
- first item
- second item
- third item
- fourth item
- fifth item
4 字符串初始化
html = '''''' from pyquery import PyQuery as pq # 格式化html文本,获取'$对象 doc=pq(html) # doc ---> '$' #获取html文本下所有的li标签 print(doc('li'))
- first item
- second item
- third item
- fourth item
- fifth item
结果

5 URL初始化
from pyquery import PyQuery as pq #直接获取网页源码 doc=pq(url='https://www.baidu.com') title=doc(':submit').attr.value print(title)
结果
![]()
6 文件初始化
from pyquery import PyQuery as pq #读取文件 doc = pq(filename='demo.html') print(doc('li'))
结果

7 基于css选择器
html = '''''' from pyquery import PyQuery as pq doc = pq(html) #找id=container标签下 所有class=list标签下的 所有的li标签 print(doc('#container .list li'))
- first item
- second item
- third item
- fourth item
- fifth item
结果

8 查找元素
子元素(不找孙子)
(链式寻找,doc($)找到的标签对象可以继续查找)
html = '''''' from pyquery import PyQuery as pq doc = pq(html) #先获取所有的class=list 标签 items = doc('.list') #再获取所有的li标签 lis=items('li') print(lis)
- first item
- second item
- third item
- fourth item
- fifth item
结果

#获取当前标签的所有子标签 lis=items.children() print(type(lis)) print(lis)
结果

父元素(不找爷爷)
html = '''''' from pyquery import PyQuery as pq doc = pq(html) items = doc('.list') #获取当前标签的父级别标签(不取爷爷标签) container = items.parent() print(type(container)) print(container)
- first item
- second item
- third item
- fourth item
- fifth item
结果

9 遍历
html = '''''' from pyquery import PyQuery as pq doc = pq(html) #寻找class=items-0并且class=active的标签 li = doc('.item-0.active') print(li)
- first item
- second item
- third item
- fourth item
- fifth item
结果
![]()
10 获取文本
html = '''''' from pyquery import PyQuery as pq doc = pq(html) #定位到 a标签 a = doc('.item-0.active a') print(a) #输出文本使用.text() print(a.text())
- first item
- second item
- 我们一起high high
- fourth item
- fifth item
结果
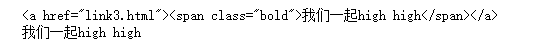
11 获取HTML
html = '''''' from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-0.active') print(li) #获取对应 标签下的 html数据 print(li.html())
- first item
- second item
- third item
- fourth item
- fifth item
结果

12 DOM操作
addClass、removeClass
html = '''''' from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-0.active') print(li) #给选定标签删除 class='active' li.removeClass('active') print(li) #给选定标签添加 class='active' li.addClass('active') print(li)
- first item
- second item
- third item
- fourth item
- fifth item
结果

attr、css
html = '''''' from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-0.active') print(li) #添加属性 name=link li.attr('name', 'link') print(li) #添加css font-size=14px li.css('font-size', '14px') print(li)
- first item
- second item
- third item
- fourth item
- fifth item
结果

remove
html = '''Hello, World''' from pyquery import PyQuery as pq doc = pq(html) wrap = doc('.wrap') print(wrap.text()) #find 找到指定标签,remove 移除 wrap.find('p').remove() print(wrap.text())This is a paragraph.
结果
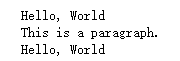
其他DOM方法
http://pyquery.readthedocs.io/en/latest/api.html
13 伪类选择器
html = '''''' from pyquery import PyQuery as pq doc = pq(html) # 获取第一个li 标签 li = doc('li:first-child') print(li) #获取最后一个li 标签 li = doc('li:last-child') print(li) #获取第2个li 标签 li = doc('li:nth-child(2)') print(li) #获取索引>2 的li 标签 li = doc('li:gt(2)') print(li) #获取偶数 的li标签 li = doc('li:nth-child(2n)') print(li) #获取文本包含second的 li标签 li = doc('li:contains(second)') print(li)
- first item
- second item
- third item
- fourth item
- fifth item
结果

更多CSS选择器可以查看 http://www.w3school.com.cn/css/index.asp