mysql的索引innodb和myisam, 以及B+Tree和B-Tree详解
一. mysql的索引
mysql常用的索引有以下几种:
-
hash索引
hash索引通过hash值来匹配对应的数据,类似键值对的形式,查找的时候可以精准一次定位,但是对于范围查询,排序效率不高,并且hash索引不能避免全表扫描,因为hash值并不能完全保证一个hash值匹配一个数据(hash冲突),还是需要比对实际数据
-
btree索引
MySQL里默认和最常用的索引类型,利用二分查找的思想构建的数据结构
-
全文索引
myisam引擎支持全文索引,innodb在mysql5.6以后也支持全文索引,不过基于mysql很少存储text大文本数据,全文检索也被es替代
二. 二叉树到B-Tree和B+Tree
2.1 二叉树到平衡二叉树
二叉树是一种基础的树结构,它通常由一个根节点和衍生的分支组成.它的特点是:
- 每个节点都最多只有两个子节点(分支)
二叉树只是一个树结构,在实际应用中还有一种特殊的二叉树,叫二叉查找树.
它在二叉树的基础上,多了一个特点,左边的节点都比右边的节点小
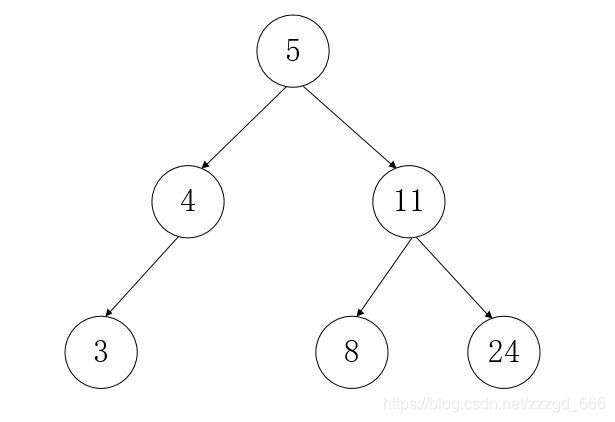
但是可能会出现特殊情况,就会从树状结构变成链表结构,查询效率大打折扣.结构如下
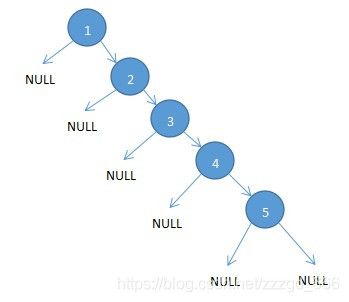
为了解决这个问题,又出现了平衡二叉树.
平衡二叉树的特点就是,左右两个分支的高度相差不会超过1.
如果在一个分支加一个节点,导致两边高度超过1了,平衡二叉树会做一个旋转操作进行平衡.
左旋如动图:

右旋如动图:

2.2 从平衡二叉树到B-Tree
B-Tree是基于平衡二叉树优化而来,且Btree是一种是为磁盘等外存储设备设计的一种平衡查找树.所以先了解一下磁盘的存储结构
2.2.1 硬盘的存储
硬盘是一个由很多个盘片组成的结构,上下两面都可以读写

图中的一圈圈灰色同心圆为一条条磁道,从圆心向外画直线,可以将磁道划分为若干个弧段,每个磁道上一个弧段被称之为一个扇区(图践绿色部分)。扇区是磁盘的最小组成单元,通常是512字节。
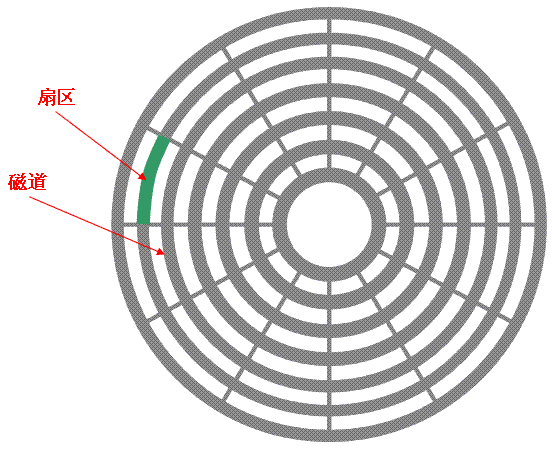
当需要从硬盘读取数据的时候,系统会将数据的存储地址给磁盘,磁头需要移动到相应的磁道上,这个过程叫寻道, 然后磁盘旋转将目标扇区旋转到磁头下,这个耗费的时间叫旋转时间.
根据局部性原理,系统会认为,当某个数据被用到时,它附近的数据也会被使用. 同时也为了减少读取的io次数,避免多次寻道和旋转磁盘, 磁盘往往不是严格按需读取,而是每次都会预读一部分数据.
预读的长度一般为页,通常大小是4k.
2.2.2 B-Tree的特性

一个m阶的B-Tree满足以下特点:
- 每一个节点最多有 m 个子节点
- 每一个非叶子节点(除根节点)最少有 ⌈m/2⌉ 个子节点
- 有 k 个子节点的非叶子节点拥有 k − 1 个关键字
- 非叶子节点都是由关键字,指针和数据组成,指针指向子节点
- 每个节点的关键字key的数量是指针数量n-1,可以理解为指针在关键字的两侧
- 所有叶子节点所处的高度一样
- 关键字只会在树中出现一次
- 关键字从左到右递增
2.2.3 B+Tree的特性
B+Tree是基于B-Tree的优化.

一个m阶的B+Tree满足以下特点:
- 每一个节点最多有 m 个子节点
- 每一个非叶子节点(除根节点)最少有 ⌈m/2⌉ 个子节点
- 所有叶子节点所处的高度一样
- 所有关键字,都会在叶子节点出现
- 非叶子节点只存储关键字key和指针,只有叶子节点保存数据
- 关键字从左到右递增
区别在于:
- B-Tree的关键字分布在各个节点,不会重复出现. 而B+Tree的关键字都会出现在叶子节点
- B+Tree的非叶子节点不会保存数据信息. 数据信息都在叶子节点中
- B+Tree的叶子节点从左到右顺序排列,并且存在指针连接,是一个链表结构
2.3 B树添加数据,删除数据
2.3.1 添加
 g)
g)
2.3.2 删除

动图观看实验网址
可以自己试试添加节点和删除节点
-
B-Tree:
https://www.cs.usfca.edu/~galles/visualization/BTree.html
-
B+Tree
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
这也就解释了为什么主键需要自增,因为主键的顺序和数据存储的顺序是一致的,如果主键不是递增顺序的, 会导致插入数据的时候造成B+Tree的节点的分裂和移动,并且因为分页形成碎片,浪费资源
2.3 为什么B+Tree适合查询硬盘存储数据
由上面硬盘结构可知,读取数据所耗费的时间,绝大多数花在硬盘io上,而内存中的处理则快很多.那么提高查询的效率,就是减少磁盘io的次数. 如上图的主键为29的记录,需要三次io可以定位
我们也可以看出:磁盘的IO次数,和树的高度成正相关,也就是说,降低树的高度,就可以减少io次数.
上面我们知道硬盘有页的概念,InnoDB存储引擎也有页的概念,默认每个页的大小为16KB,在MySQL中可通过如下命令查看页的大小:
mysql> show variables like 'innodb_page_size';

我们假设一行的数据是1K,那我们一页的数据,就能存储16行数据,也就是一个叶节点可以存储16条记录;再来看非叶节点,假设ID是bigint类型,那么长度为8B,指针大小在InnoDB源码中为64(6B),一共就是14B,那么一页里面就可以存储16K/14=1170个(主键+指针)
那么一棵高度为2的B+树能存储的数据为:
1170 * 16=18720条,一棵高度为3的B+树可以存储1170 * 1170 * 16 = 21902400(两千万条)
也就是说,两千万级别的数据,根据主键查询最多都只需要三次IO操作就可以找到记录.
2.4 为什么B+Tree比B-Tree更好
- 因为B+Tree非叶子节点不存储数据,而是只存储关键字和指针,所以每个节点能保存的关键字和指针比B-Tree更多,所以子节点更多,同样的数据量树的高度更矮,磁盘IO操作更少
- B+Tree所有数据都在叶子节点,且叶子节点之间是排好序的链表,范围查询,排序能力比B-Tree更强
三. 索引结构
3.1 聚簇索引(聚集索引)和非聚簇索引(辅助索引,二级索引)
聚簇索引和非聚簇索引并不是一种类似非空索引,主键索引的索引类型,而是一种数据存储方式
简单的说,聚簇索引就是索引和数据存储在一起,在B+Tree中,表示都一个叶子节点上关键字和它代表的数据行存储在一起
非聚簇索引则是相反. 索引和真正的数据行是分开的. 在B+Tree中,叶子节点上存的是主键id
由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有一个聚簇索引
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引.
除了聚簇索引以外,我们建的其他普通索引,都是二级索引,或者叫辅助索引.像复合索引、前缀索引、唯一索引
- 聚簇索引

-
辅助索引
辅助索引最后叶子节点上保存的不是数据行,而是聚簇索引的id(通常就是主键id),所以如果通过辅助索引查询数据, 需要遍历两次B+Tree
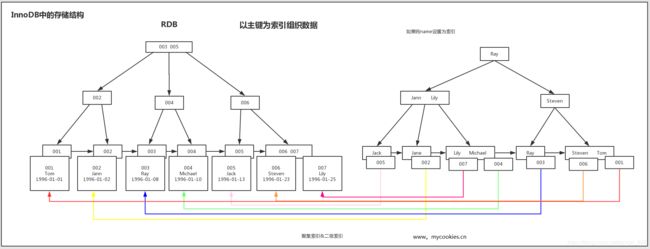
三. InnoDb和MyISAM
在mysql5.5.5之前,默认引擎是MyISAM,之后换成了InnoDb
Before MySQL 5.5.5, MyISAM is the default storage engine. (The default was changed to InnoDB in MySQL 5.5.5.) MyISAM is based on the older (and no longer available) ISAM storage engine but has many useful extensions.
在myisam中,不管是不是主键,还是普通索引,叶子节点上保存的都是数据的物理磁盘的引用地址,当查询到这个引用地址,就可以将这份数据加载到内存.

而在innodb中,使用的就是上面的聚簇索引, 在主键(或者系统默认的隐式一个主键索引)的叶子节点上, 保存的是数据行的真实信息. 其他索引(辅助索引)的叶子节点都是这个主键索引的关键字的值.
比如在主键以外的name字段建立索引,innodb会在辅助索引找到ID索引的值,再通过ID索引获取最终的数据.
这样看起来innnodb似乎比myisam效率更低,但是如果用主键查询的话,在叶子节点查到数据的同时也就将数据读取到内存中了,无需根据物理地址再进行一次磁盘读取操作. 而且辅助索引都是储存的主键的id,所以即便数据迁移了,只要id不变,辅助索引也无需进行变更
