Hadoop HA高可用安装过程和wordcount实例
一、HA介绍
HA是为解决HDFS中单点故障。
高可用通过主备NameNode来解决问题,如果当NameNode(active)发生故障,则切换到备用NameNode(standby)上。

DateNode中数据时间等发生变化(不断)都要跟NameNode汇报,为了防止单点故障,所以我们用HA高可用方式。
我们准备两台NameNode,一台正在工作(active)的NameNode,一台备用(standby)的NameNode。如果NameNode(active)故障了,standby状态的NameNode变为active状态的NameNode,active状态的NameNode变为standby状态的NameNode。这一种转换是由JournalNode管理。
JournalNode是用来管理NameNode资源共享。当JournalNode发现NameNode有问题,就切换NameNode的当前状态。
JournalNode不放一台:JournalNode如果一台出故障了,跟只有一台NameNode一样,数据都没有了,也不安全。
JournalNode放三台:过半原则。
ZooKeeper管理JournalNode,NameNode。不用手动改变它们standy和active状态。并且它有两个进程:Failover Controller Active和Failover Controller Standby监视NameNode。
如果NameNode(active )挂了,Failover Controller Active就汇报给ZooKeeper,ZooKeeper发现NameNode(active )挂了,就检查Failover Controller是不是standby准备好了,如果准备好了就将NameNode(active )自动切换成NameNode(standby)。每个NameNode都有一个ZooKeeperFailoverController监视。
我们的安装方案如下图。只有三台的,将NN-2也放在node01,DN在node02,node03

二、前期准备!!!
准备
四台虚拟机,且四台虚拟机能相互ping通。可根据这个链接学习https://blog.csdn.net/Dlychee/article/details/106756219
并且要将
Xshell和Xftp连接虚拟机,可根据这个链接学习https://blog.csdn.net/Dlychee/article/details/106756519
知识点1:按“i”编辑文件,编辑完内容后,按“Esc”键,然后输入“:wq”为保存编辑内容并退出,输入“:q!”为不保存编辑内容并退出。
知识点2:在敲当前目录下文件名的时候可以按 Tab 键,它会自动帮你补全文件名。
(一)、安装jdk
这里给一个jdk-7u67-linux-x64.rpm
网盘链接: https://pan.baidu.com/s/1cwuoJLPcclQEKwJSqaNMIQ
提取码:688f
我们将四台虚拟机都开启且与Xshell连接上。

首先配置node01虚拟机的jdk,在node01上操作以下步骤
1.将在Windows中的jdk.rpm文件传输给node01。 (rpm相当于Windows的exe文件)
(
右边部分为虚拟机中root目录下)
首先,单击“新建文件传输”。然后,在左边部分找到在Windows下jdk-7u67-linux-x64.rpm文件,右键,单击“传输”。
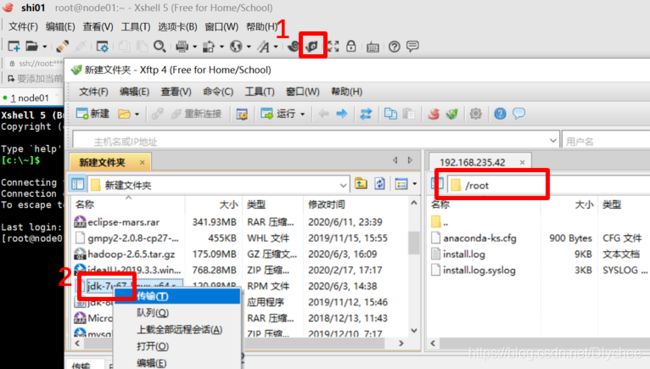
2.输入命令
rpm -i jdk-7u67-linux-x64.rpm

3.查询jdk安装路径
whereis java

4.配置全局环境变量
(1)进入profile中进行编辑的命令,“vi + 文件路径”表示打开文件,并将光标置于最后一行首 。
vi + /etc/profile
按“i”编辑文件,编辑完内容后,按“Esc”键,然后输入“:wq”为保存编辑内容并退出,输入“:q!”为不保存编辑内容并退出。(后面将不再重复此知识点。)
(2)在它最后插入:
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:$JAVA_HOME/bin

5.使环境变量生效(每次修改过/etc/profile文件后记得一定要source一下)
source /etc/profile
6.输入命令jps,如果出现-bash: jps: command not found

(1)此时更改环境变量,输入命令:
vi + /etc/profile
(2)更改刚刚前面输入的内容:
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin
(3)使环境变量生效
source /etc/profile
(4)再次输入命令jps,查看是否出现Jps

这时候我们虚拟机中 node01中的jdk安装成功。
开始配置node02,node03,node04虚拟机的jdk
7.现在我们将node01中的jdk分发给node02,node03,node04中。
在虚拟机node01中,我们cd到存放jdk.rpm文件的目录下(这里我们的jdk刚刚放在了根目录中,所以cd ~),然后输入以下命令将jdk发送给node02:
scp jdk-7u67-linux-x64.rpm node02:'pwd'
scp是发送命令,pwd是当前目录。即将jdk-7u67-linux-x64.rpm文件发送给node02的当前目录下。
不要忘了还要发送给node03,node04。
scp jdk-7u67-linux-x64.rpm node03:'pwd'
scp jdk-7u67-linux-x64.rpm node04:'pwd'

8.查看node02,node03,node04是否接收到jdk-7u67-linux-x64.rpm。
(1)我们将Xshell软件的右下角的 “三” 图标单击一下,然后选择全部会话。

(2)在Xshell全部会话框中输入 ll ,然后按“Enter”键。来查看jdk是否传输成功。
![]()
当每台虚拟机中都出现jdk-7u67-linux-x64.rpm,则证明传输成功。
![]()
如果没有显示jdk-7u67-linux-x64.rpm,有可能是虚拟机之间不能ping通。
9.分别在node02,node03,ndoe04上执行rpm安装命令。
rpm -i jdk-7u67-linux-x64.rpm

10.在node01上cd /etc,在此目录下把profile文件分发到node02、node03、node04上。
scp profile node02:`pwd`
scp profile node03:`pwd`
scp profile node04:`pwd`

11.看node02、node03、node04这三台机子的jdk是否装好
(1)利用Xshell全部会话栏输入source /etc/profile
![]() (2)利用Xshell全部会话栏输入
(2)利用Xshell全部会话栏输入jps
![]() 在每台虚拟机中我们可以看到 jps 进程启动,则四台虚拟机的jdk安装成功。
在每台虚拟机中我们可以看到 jps 进程启动,则四台虚拟机的jdk安装成功。

(二)、同步所有服务器时间
1.查看每台虚拟机当前时间。(时间不能差太大,否则集群启动后某些进程跑不起来。)
利用Xshell全部会话栏输入命令 date,看四台虚拟机当前时间,一不一样。

2.时间不同步,我们可以做一下操作。(不管时间同步同步,这里建议都执行一遍以下操作。)
(1)用yum安装时间同步器。
利用Xshell全部会话栏输入
yum -y install ntp
当最后显示“Complete!”安装完成。
(2)执行时间同步命令。
这里我们做和阿里云第一台服务器时间同步。(做这个的前提是虚拟机ping外网能ping通,例如ping www.baidu.com能成功。)
利用Xshell全部会话栏输入
ntpdate time1.aliyun.com
 3.再次查看每台虚拟机当前时间。
3.再次查看每台虚拟机当前时间。
利用Xshell全部会话栏输入命令 date,看四台虚拟机当前时间,一不一样。
(三)、配置文件检查
1.查看四台虚拟机的HOSTNAME是否正确。
cat为查看命令,我们的hostname存放在/etc/sysconfig/network路径中。
利用Xshell全部会话栏输入命令
cat /etc/sysconfig/network
这里给出node01和node02截图


如果不正确可以输入命令vi /etc/sysconfig/network来更改。
2.查看四台虚拟机IP映射是否正确。
利用Xshell全部会话栏输入命令
cat /etc/hosts
这里给出node01和node02截图,查看最后四行,IP和主机名是否一一对应。

 如果不正确,可以输入命令
如果不正确,可以输入命令vi /etc/hosts来更改。
3.查看四台虚拟机中SELINUX=disabled
利用Xshell全部会话栏输入命令
cat /etc/sysconfig/selinux

如果不正确,可以输入命令vi /etc/sysconfig/selinux来更改。
4.查看四台虚拟机的防火墙是否关闭。
利用Xshell全部会话栏输入命令
service iptables status
显示Firewall is not running,则证明防火墙关闭。

没有关闭则输入命令service iptables stop
(四)、查询.ssh文件
1.四台虚拟中在根目录(即cd ~)中查看是否有 .ssh 文件
利用Xshell全部会话栏输入命令ll -a
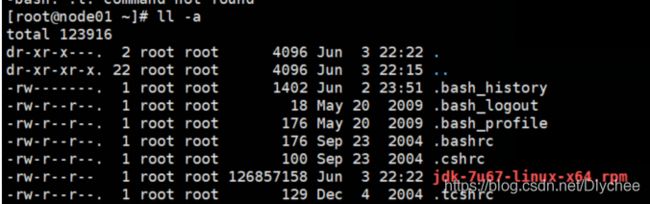
2.哪一台虚拟机里没有 .ssh文件 ,则就在该台虚拟机中输入命令 ssh localhost
遇到问(yes/no)输入 yes ,遇到password输入你的 密码 。ssh登录完后记得最后要退出登录,输入命令 exit
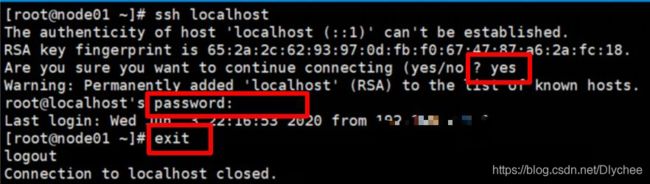
3.再次输入命令 ll -a,看 .ssh 文件是否出现。
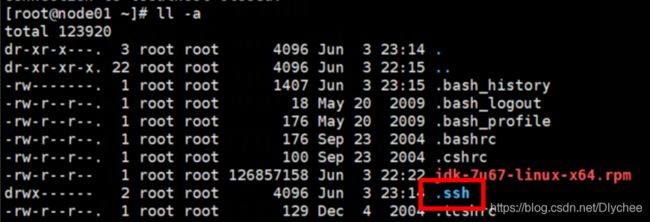
(五)、设置免密
(五.1)、四台虚拟机自身的免密钥
这里以node01为例,其它三台免密步骤相同
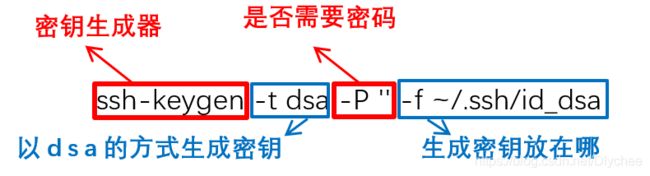
1.输入命令:(P为大写)
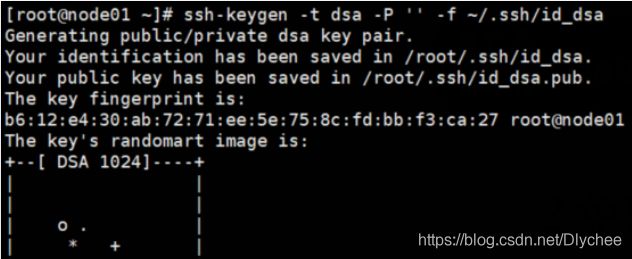
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2.把id_dsa.pub追加到authorized_keys。
输入命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
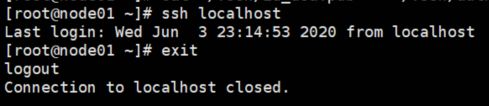
3.免密验证(此次ssh localhost不需要输入密码)
(1)输入命令 ssh localhost,记得要退出登录 exit
(2)输入命令 ssh node01,记得要退出登录 exit

4.这个时候我们输入命令 ll,就可以看到 .shh目录中有以下几个文件。

不要忘了其它三台虚拟机也要免密钥!!!到各自对应的虚拟机中执行刚刚的步骤,完成免密钥配置。
(五.2)、NN-1与其它三台台虚拟机免密钥
当四台虚拟机都自身免密钥成功后,我们让NN-1与三台DN免秘钥设置。这样NN-1可以快速访问DN
我们这里设置node01为NN-1所以我们现在将node01的公钥发送给其它三台虚拟机。
1.首先我们要进入.ssh目录下。
利用Xshell全部会话栏输入命令cd /root/.ssh
2.然后在虚拟机node01中,输入以下命令。
scp id_dsa.pub node02:`pwd`/node01.pub
scp id_dsa.pub node03:`pwd`/node01.pub
scp id_dsa.pub node04:`pwd`/node01.pub


3.传输完成后,我们 分别到node02,node03,node04虚拟机 中的 .ssh目录 查看是否存在node01.pub。并且分别依次输入命令cd /root/.ssh和ll即可查看。
这里给一个node02的截图
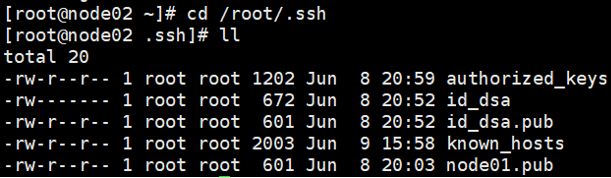
4.如果有node01.pub,我们就将它追加到authorized_keys中,使其它三台虚拟机可以获取node01公钥的权限。
分别在node02,node03,node04虚拟机上输入命令
cat node01.pub >> authorized_keys
这里给一个node02的截图
![]()
5.验证在node01中我们是否可以免密钥登录node02,node03,node04三台虚拟机。
首先,我们回到node01虚拟机中,依次输入一下命令,每次ssh登录成功后,不要忘了exit退出登录。如果登录时不再需要输入密码,则表示由node01到其它三台虚拟机免密成功。
ssh node02
exit
ssh node03
exit
ssh node04
exit

(五.3)、两个NameNode之间相互免密钥
在HA高可用中,我们有两个NameNode,它们需要时常相互传输数据,以保持两个NN中数据相同,防止其中一台挂了之后,出现故障,所以我们要使这两个NN也相互免密钥一下。
我们这里设置node01和node02为NameNode,现在需要node01与node相互免密登录。刚刚我们实现了在node01上免密登录node02,现在只需做在node02上免密登录node01。
1.我们在node02的虚拟机上,验证一下刚刚前面 (五.1) 中是否实现了对自身的免密。验证方式如下:输入ssh localhost ,如果不需要密码登录,则免密成功,记得最后不要忘了退出登录exit

2.node02自身免密成功后,我们 cd /root/.ssh 到 .ssh目录 下将它的id_dsa.pub公钥发送给node01。
scp id_dsa.pub node01:`pwd`/node02.pub

3.我们在node01虚拟机上, cd /root/.ssh 到 .ssh目录 下,并且ll一下,我们可以看到node02.pub这个公钥文件。

4.如果有node02.pub,我们就可以把它追加到authorized_keys中,使node01虚拟机可以获取node02公钥的权限。
在node01虚拟机的.ssh目录上输入命令
cat node02.pub >> authorized_keys
5.验证在node02上是否可以免密登录node01。
我们现在到ndoe02的虚拟机上,依次输入以下命令,每次ssh登录成功后,不要忘了exit退出登录。如果登录时不再需要输入密码,则表示由node02到node01免密成功。
ssh node01
exit

这就是我们现在所完成的免密关系图。

三、安装Hadoop并配置文件信息
提供一个绿色版本hadoop-2.6.5,解压就能用。
网盘链接: https://pan.baidu.com/s/1tPnm0hhr0w3yGFNX1nBJwg
提取码:zbqq
(一)、在node01中安装Hadoop
1.首先,我们要在虚拟机主目录下建立一个新的目录用来等下来存放hadoop的压缩包,这里我取的文件名是software
到主目录的命令为 cd ~
新建目录的命令为 mkdir 文件名
![]()
2.将Windows中hadoop压缩包传到虚拟机node01中。
单击“新建文件传输”图标,右边虚拟机进入刚刚创建的software目录中,在Windows(即本地)中找到存放hadoop-2.6.5的压缩包,右键,选择“传输”。
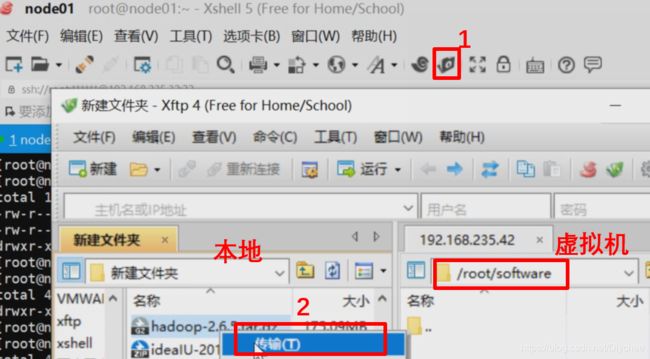
3.到opt目录下(该本身就存在,不需要我们创建),创建一个新的目录用来等下存放hadoop解压后的文件.这里我取的目录名为lychee,大家可以用自己的名字命名(例如:陈芊芊→cyy)
记住这个文件名,我们下面会经常用到它
到opt目录下命令为 cd /opt
新建目录的命令为 mkdir 文件名

4.解压hadoop压缩包。
(1)首先到存放hadoop压缩包的目录(software)下。
cd /root/software

(2)将 hadoop压缩包 解压到 lychee 目录(刚刚以自己名字命名的目录)下。
(注:C为大写)
tar xf hadoop-2.6.5.tar.gz -C /opt/lychee

(3)这个时候我们在 lychee 目录下输入命令 ll 就能看到已经解压好的hadoop。

5.想要在任意目录下启动Hadoop,我们需要在配置文件profile中做一些修改。
(1)进入profile中进行编辑的命令,“vi + 文件路径”表示打开文件,并将光标置于最后一行首 。
vi + /etc/profile
(2)对它进行配置,配置成功后保存并退出。配置内容如下:
export JAVA_HOME=/usr/java/bin
export HADOOP_HOME=/opt/自己的文件名/hadoop-2.6.5
export PATH=$PATH:usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
 (3)修改过/etc/profile文件后,不要忘了
(3)修改过/etc/profile文件后,不要忘了source一下
source /etc/profile
6.输入hd后,按Tab键可以出现hdfs 和 输入start-d后,按Tab键可以出现start-dfs. 就表示成功了。
(二)、在node01中配置文件信息
配置文件信息要仔细!!!!要不然后续很容易出错!!
1.首先到hadoop目录下:
cd /opt/lychee/hadoop-2.6.5/etc/hadoop
然后,我们 ll 一下,会看到很多配置文件。
2.配置hadoop-env.sh文件
vi hadoop-env.sh
给它的JAVA_HOME更改成绝对路径/usr/java/jdk1.7.0_67,并且保存退出。

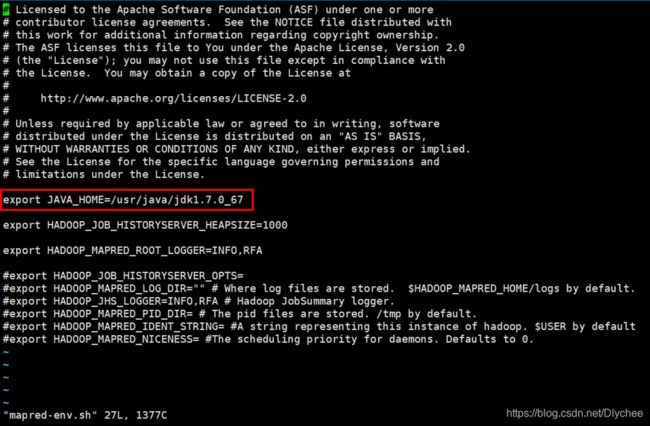
3.配置mapred-env.sh文件
vi mapred-env.sh
给它的JAVA_HOME更改成绝对路径/usr/java/jdk1.7.0_67,并且保存退出。(注:这里export JAVA_HOME这句开头有一个 注释号 #,我们需要把这个#删掉。)
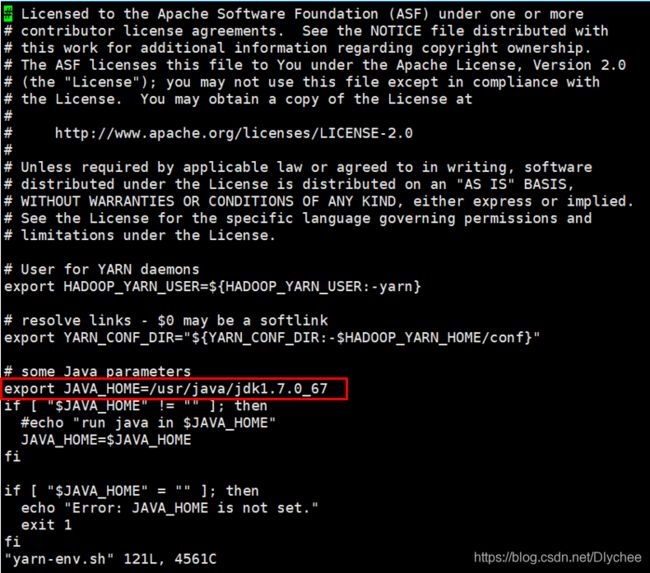
4.配置yarn-env.sh文件
vi yarn-env.sh
给它的JAVA_HOME更改成绝对路径/usr/java/jdk1.7.0_67,并且保存退出。(注:这里export JAVA_HOME这句开头也有一个 注释号 #,我们需要把这个#删掉。)
5.配置hdfs-site.xml文件
vi hdfs-site.xml
在
dfs.replication
3
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
node01:8020
dfs.namenode.rpc-address.mycluster.nn2
node02:8020
dfs.namenode.http-address.mycluster.nn1
node01:50070
dfs.namenode.http-address.mycluster.nn2
node02:50070
dfs.namenode.shared.edits.dir
qjournal://node01:8485;node02:8485;node03:8485/mycluster
dfs.journalnode.edits.dir
/var/lychee/hadoop/ha/jn
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.ha.automatic-failover.enabled
true
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.name.dir
/data/hadoop/tmp/dfs/name
dfs.data.dir
/data/hadoop/tmp/dfs/data
注意:配置信息里用自己主机名,例如:我这里用的node01,node02,node03,node04,大家自己四台虚拟机的主机名是什么要一一对应修改。

6.配置core-site.xml文件
vi core-site.xml
在
fs.defaultFS
hdfs://mycluster
ha.zookeeper.quorum
node02:2181,node03:2181,node04:2181
NameNode的元数据信息和DateNode数据文件本来默认保存在一个临时tmp文件里,这样不安全,所以更改它的Hadoop的临时目录

7.配置slaves文件
vi slaves
在里面删除原有的 localhost ,添加当前DateNode节点 所在的 虚拟机主机名。然后保存并退出。这里我们配置的是(DateNode节点)。

(三)、其他三台虚拟机中Hadoop的安装和配置文件
我们已经在node01这台虚拟机中将Hadoop安装好和配置好相关文件。现在我们从node01中将这些信息分发给其他三台虚拟机,这样我们就不需要像node01中那么麻烦的安装和配置Hadoop。
1.利用Xshell全部会话栏输入命令cd /opt
2.在node01虚拟机上 ,将opt目录下,以自己名字命名的目录(我的是lychee)分发给ndoe02,node03,node04中。
scp -r lychee/ node02:`pwd`
scp -r lychee/ node03:`pwd`
scp -r lychee/ node04:`pwd`
3.查看/opt/lychee是否传输成功。
首先,利用Xshell全部会话栏输入命令cd /opt/lychee。
然后,利用Xshell全部会话栏输入命令ll。
这时候查看每台虚拟机上,是否有hadoop-2.6.5
![]()
四、安装ZooKeeper并配置文件信息
提供一个zookeeper-3.4.6.tar。
网盘链接: https://pan.baidu.com/s/1VP_XxGz8lZ7o5ztPHQSVSA
提取码:lptw
(一)、在node02中安装zookeeper
1.首先,我们要在node02虚拟机主目录下建立一个新的目录用来等下来存放zookeeper的安装包,这里我取的文件名是software
到主目录的命令为 cd ~
新建目录的命令为 mkdir 文件名
![]()
2.将Windows中zookeeper压缩包传到虚拟机node02中。
单击“新建文件传输”图标,右边虚拟机进入刚刚创建的software目录中,在Windows(即本地)中找到存放zookeeper-3.4.6.tar的安装包,右键,选择“传输”。

3.解压zookeeper压缩包。
(1)首先到存放zookeeper压缩包的目录(software)下。
cd /root/software
(2)将 zookeeper压缩包 解压到 lychee 目录(刚刚以自己名字命名的目录)下。
(注:C为大写)
tar xf zookeeper-3.4.6.tar.gz -C /opt/lychee
![]()
(3)这个时候我们在 lychee 目录下输入命令 ll 就能看到已经解压好的zookeeper。

(二)、在node02中配置文件信息
配置文件信息要仔细!!!!要不然后续很容易出错!!
1.首先到/opt/lychee/zookeeper-3.4.6/conf目录下:
cd /opt/lychee/zookeeper-3.4.6/conf
然后,我们 ll 一下,会看到有一个zoo_sample.cfg文件。
2.我们要配置一下zoo_sample.cfg文件,以防我们将它修改坏了,现在我们拷贝一下zoo_sample.cfg这个文件,拷贝出来的新文件命名为zoo.cfg。然后我们在拷贝出的zoo.cfg这个文件中配置信息。
用以下命令来实现:
cp zoo_sample.cfg zoo.cfg
然后我们ll一下,发现zoo.cfg拷贝成功。

3.配置zoo.cfg文件
vi zoo.cfg
![]()
(1)修改dataDir=/var/自己名字命名的目录/zk,这里我修改的是dataDir=/var/lychee/zk
(2)并在文件末尾追加
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
2888是主从通信端口,3888是当主挂断后进行选举机制的端口。

(三)、其他两台虚拟机中ZooKeeper的安装和配置文件
我们已经在node02这台虚拟机中将ZooKeeper安装好和配置好相关文件。现在我们从node02中将这些信息分发给其他两台虚拟机,这样我们就不需要像node02中那么麻烦的安装和配置ZooKeeper。
1.利用Xshell全部会话栏输入命令cd /opt/lychee
2.在node02虚拟机上 ,将 zookeeper-3.4.6 分发给node03,node04中。
scp -r zookeeper-3.4.6/ node03:`pwd`
scp -r zookeeper-3.4.6/ node04:`pwd`
3.查看zookeeper-3.4.6是否传输成功。
首先,利用Xshell全部会话栏输入命令cd /opt/lychee。
然后,利用Xshell全部会话栏输入命令ll。
这时候查看node03,node04两台虚拟机上,是否有zookeeper-3.4.6
这里给出node03的截图

4.给node02,node03,node04虚拟机创建刚配置文件的路径。
分别在node02,node03,node04三台虚拟机中,输入命令:
p是小写 (我的是mkdir -p /var/lychee/zk)
mkdir -p /var/自己名字命名的目录/zk
5.给每台机子配置其编号(必须是阿拉伯数字)
注意: 再次强调lychee是你自己名字命名的那个文件
(1)首先,我们要在node02,node03,node04三台虚拟机中分别敲这个命令:cd /var/lychee/zk
(2)
在node02虚拟机上:
echo 1 > /var/lychee/zk/myid
cat /var/lychee/zk/myid
在node03虚拟机上:
echo 2 > /var/lychee/zk/myid
cat /var/lychee/zk/myid
在node04虚拟机上:
echo 3 > /var/lychee/zk/myid
cat /var/lychee/zk/myid
6.配置/etc/profile
(1)在node02虚拟机上,我们输入命令:vi + /etc/profile可以看到末尾有这三行配置。
 (2)现在我们对它们进行添加和更改。
(2)现在我们对它们进行添加和更改。
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/opt/自己名字命名的文件/hadoop-2.6.5
export ZOOKEEPER_HOME=/opt/自己名字命名的文件/zookeeper-3.4.6
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
 (3)编辑过profile的文件后,不要忘了source一下。
(3)编辑过profile的文件后,不要忘了source一下。
source /etc/profile
(4)在node02虚拟机上,我们将**/etc/profile**分发到node03,node04虚拟机上。
scp /etc/profile node03:/etc
scp /etc/profile node04:/etc
因为node02与node03,node04没有相互免密,所以node02发送文件给node03,node04是需要输密码的。
这里给一个由node02传送文件给node03的截图

(5)/etc/profile分发成功后,我们在node03和node04两台虚拟机中也要刷新重读一遍/etc/profile。
所以,在node03,node04中都要执行这条命令:source /etc/profile
(6)验证是否完成。
在node02,node03,node04分别输入zkCli.s,然后按Tab键可以把名字补全为zkCli.sh。这条命令不需要执行。
这时候我们在node02,node03,node04中zookeeper安装结束。
五、启动ZooKeeper
zookeeper启动命令在任何目录下都可以执行。
1.利用Xshell全部会话栏输入命令zkServer.sh start。
在node02,node03, node04虚拟机中显示zookeeper已开启:Starting zookeeper ... STARTED
这里给一个node02的截图
 node01中我们没有安装zookeeper,所以node01中会显示没有找到这个命令。结果如下图:
node01中我们没有安装zookeeper,所以node01中会显示没有找到这个命令。结果如下图:
![]()
2.显示了Starting zookeeper … STARTED,我们也不能确定zookeeper是否真正的开启,它有可能是一个假象。现在让我们查看每个zookeeper节点的状态,来确定zookeeper是否真正的开启。
利用Xshell全部会话栏输入命令zkServer.sh status。
在node02,node03,node04三台虚拟机中,有 两台 的状态是 follower,一台 状态是 leader。(这三台虚拟机的状态没有规定哪个状态一定是follower或者leader。只要确保两台是follower和一台是leader)
 3.如果出现了状态是
3.如果出现了状态是 standalone,那么在出现该状态的虚拟机中输入命令:jps查看进程。然后,杀死现在被QuorumPeerMain占领的进程。执行命令 kill -9 进程号 。
例如,下面这张图的情况,我们执行**kill -9 1237** 。

六、启动journalnode
为了使两台namenode之间完成数据同步,我们要启动journalnode。
我们这里将journalnode放在node01,node02,node03三台虚拟机上。为什么放在这三台虚拟机上呢?
因为我们journalnode是用来管理namenode的,还用一台用来备用。
1.分别在node01,node02,node03虚拟机上启动journalnode。
hadoop-daemon.sh start journalnode
2.分别在node01,node02,node03虚拟机上,用 jps命令 检查一下进程,看journalnode有没有启动成功。
这里给一个node02虚拟机的截图,当出现JournalNode的进程的时候,证明启动成功。

七、启动namenode
(一)、格式化任一台namenode
1.随意挑一台namenode上执行 hdfs namenode –format。
另一台namenode不用执行,否则clusterID变了,就找不到集群了。这里我在node01上执行格式化。
2.然后,在刚刚格式化的那台namenode中(这里我是node01上),我们敲命令:
hadoop-daemon.sh start namenode
然后jps一下,会出现NameNode的进程。

(二)、给另一台namenode同步数据
1.现在我们给另一台namenode同步一下数据,这样好让两台namenode进行数据交互。这里我们的另一台namenode是node02。
在node02虚拟机上,我们执行命令:
hdfs namenode -bootstrapStandby
2.格式化zkfc。
回到node01虚拟机上,我们执行命令:
hdfs zkfc -formatZK
3.打开zookeeper客户端,查看hadoop-ha是否打开。
(1)首先,执行下图步骤。
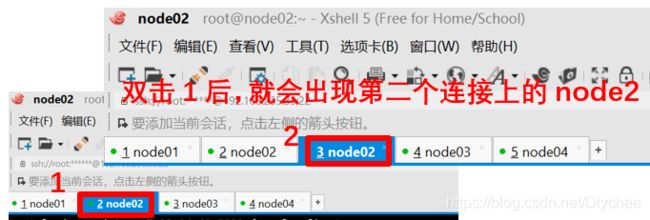
(2)在刚刚新打开的node02上,我们执行命令:
zkCli.sh
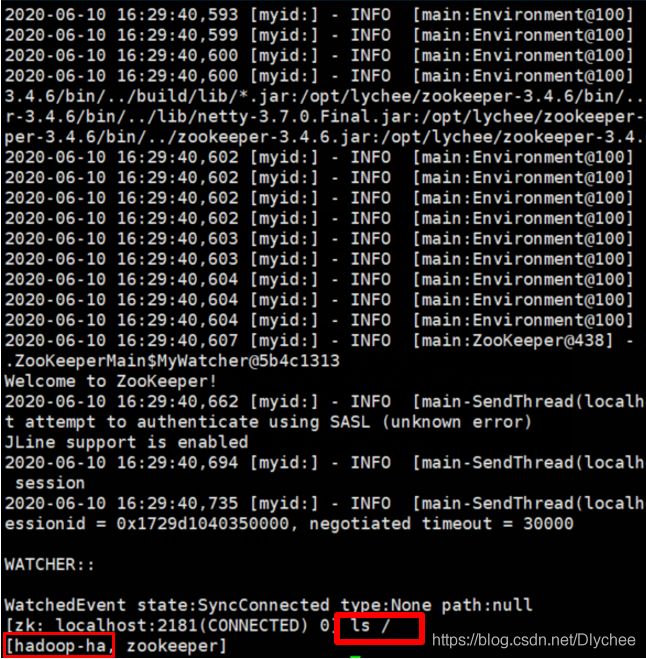
当这个命令执行完之后,我们还是在这个新打开的node02上,我们执行命令:
ls /
看是否出现hadoop-ha。
八、启动hdfs集群
如果那个节点没起来到hadoop目录下去看那个node的日志文件log
1.在node01虚拟机上,启动hdfs集群,输入命令:start-dfs.sh

2.利用Xshell全部会话栏输入命令jps,查看进程。
四台虚拟机的进程如下。

九、在windows环境看Hadoop集群
在集群启动的情况下,我们在浏览器(不要用360浏览器,这里我用火狐)中搜索有 namenode节点的虚拟机主机名:50070,这里我搜的是node01:50070和
node02:50070
一台红框内显示active,一台显示standby,则成功。没有规定哪一台一定是active,那一台是standby。
这时候我们的hdfs算是搭建成功了。

十、MapReduce前期准备
(一)、配置文件
1.首先我们要关闭集群,在node01中,我们输入:stop-dfs.sh
2.然后关闭zookeeper,利用Xshell全部会话栏输入命令,我们输入:zkServer.sh stop
注意:你下一次启动hdfs集群的时候还需要用hadoop-daemon.sh start journalnode命令启动journalnode吗?
不需要,只要start-dfs.sh就可以了。我们之前启动journalnode是为了同步两个namenode之间的信息。
3.首先到/opt/lychee/hadoop-2.6.5/etc/hadoop
目录下。利用Xshell全部会话栏输入命令:
cd /opt/lychee/hadoop-2.6.5/etc/hadoop
然后,我们 ll 一下,会看到有一个mapred-site.xml.template文件。
在node01中操作
4.我们要给mapred-site.xml.template文件留一个备份,以防我们将它修改坏了,现在我们拷贝一下mapred-site.xml.template这个文件,拷贝出来的新文件命名为mapred-site.xml。然后我们在拷贝出的mapred-site.xml这个文件中配置信息。
用以下命令来实现:
cp mapred-site.xml.template mapred-site.xml
然后我们在ll一下,发现mapred-site.xml拷贝成功。

5.配置mapred-site.xml
在
mapreduce.framework.name
yarn

6.配置yarn-site
在
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node03
yarn.resourcemanager.hostname.rm2
node04
yarn.resourcemanager.zk-address
node02:2181,node03:2181,node04:2181
7.在node01中把mapred-site.xml和yarn-site.xml 分发到node02、node03、node04三台虚拟机中。
scp mapred-site.xml yarn-site.xml node02:`pwd`
scp mapred-site.xml yarn-site.xml node03:`pwd`
scp mapred-site.xml yarn-site.xml node04:`pwd`
(二)、node03与node4相互免密
为什么它们要相互免密?
因为它们俩都是resourcemanager。resourcemanager是管理resource资源
在前面我们做过了node03,node04它们自身的免密
1.利用Xshell全部会话栏输入命令cd /root/.ssh。
2.把node03的公钥分发给node04。
在node03虚拟机上执行命令
scp id_dsa.pub node04:`pwd`/node03.pub
3.在node04虚拟机上执行命令
cat node03.pub >> authorized_keys
执行一下命令,看是否免密,最后不要忘记exit退出登录。
ssh node04
exit
4.把node04的公钥分发给node03。
在node04虚拟机上执行命令
scp id_dsa.pub node03:`pwd`/node04.pub
5.在node03虚拟机上执行命令
cat node04.pub >> authorized_keys
执行一下命令,看是否免密,最后不要忘记exit退出登录。
ssh node03
exit
这是我们最后所完成的免密关系图。

(三)、启动集群
1.利用Xshell全部会话栏输入命令zkServer.sh start。
2.在node01上启动dfs, start-dfs.sh
3.在node01上启动yarn, start-yarn.sh
4.在node03,node04上分别启动resourcemanager。
yarn-daemon.sh start resourcemanager
5.利用Xshell全部会话栏输入命令jps,查看进程全不全。
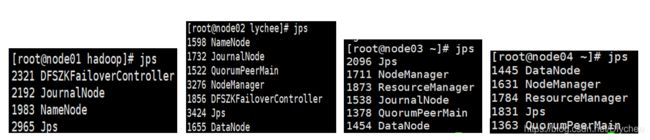
(四)、在windows环境看resourcemanager管理内容
在集群启动的情况下,我们在浏览器(不要用360浏览器,这里我用火狐)中搜索有 resourcemanager节点的虚拟机主机名:8088,这里我搜的是 node03:8088
单击active node,我们可以看到ndoe02,ndoe03,ndoe04活跃着。

十一、关闭集群
1.在node01上启动dfs, stop-dfs.sh
2.在node01上启动yarn, stop-yarn.sh
3.在node03,node04上分别启动resourcemanager。
yarn-daemon.sh stop resourcemanager
4.利用Xshell全部会话栏输入命令zkServer.sh stop。
5.利用Xshell全部会话栏输入命令jps,查看进程只剩下jps一个进程,则退出成功。
十二、wordcount实例
现在让我们来跑一个wordcount试试!!
这个实例我们在node01虚拟机上操作,并且把 集群开启。。
1.这里首先我们在Windows内准备一个有内容的.txt文件夹,这里我给它命名为500miles。
(1)利用Xshell和Xftp将它传输给虚拟机内你要存放的路径中,这里我存放在根目录root下。

(2)我们可以到存放的目录下,ll一下,会发现你存的500miles.txt。

2.在HDFS中创建输入目录和输出目录。
(1)创建输入目录命令(就是把我们要wordcount那个文件里的东西放入其中)
hdfs dfs -mkdir -p /data/in
![]()
(2)创建输出目录命令(就是把wordcount的结果放入其中)
hdfs dfs -mkdir -p /data/out
![]()
(3)在Windows环境下,用浏览器搜node01:50070。按照下图步骤来,如果出现in和out目录则证明创建成功。

3.将要统计数据的文件上传到输入目录并查看
(1)将要统计数据的文件上传到输入目录。
hdfs dfs -put 要统计数据的文件名 /data/in
例如:
hdfs dfs -put 500miles.txt /data/in
![]()
(2)在浏览器中刷新并查看500miles文件是否存在。

也可以在虚拟机用命令查看 hdfs dfs -ls /data/in
4.进入MapReduce目录(对大数据进行计算)
cd /opt/lychee/hadoop-2.6.5/share/hadoop/mapreduce
 然后我们
然后我们 ll一下,可以看到其中有一个样例jar包hadoop-mapreduce-examples-2.6.5.jar。

5.运行wordcount。此时的/data/out必须是空目录
输入命令:
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/in /data/out/result


6.查看运行结果
(1)查看result目录下生成的文件。
hdfs dfs -ls /data/out/result
SUCCESS放的是成功与否的信息。

我们刷新一下浏览器,也可以查看是否成功。

(2)查看part-r-00000里面的信息。
-cat查看文件的命令
ls查看目录的命令
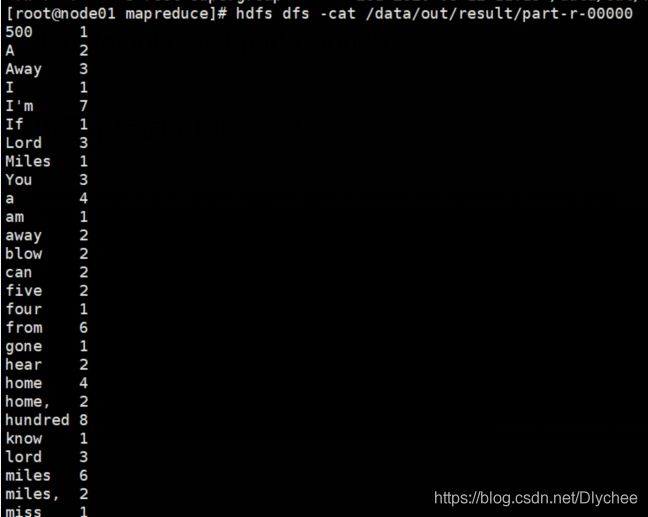
hdfs dfs -cat /data/out/result/part-r-00000
我们就可以看见每个单词出现的次数。
7.最后我们可以关闭集群了。