Python_Pandas学习笔记03:DataFrame按列筛选满足特定条件的行
一、参考资料
[1] Pandas数据合并与重塑
[2] Python随机数
[3] Python中小数点位数控制
二、DataFrame数据框的筛选
首先为了进行该部分的展示,创建测试数据集,测试数据集的内容为A,B两省的2000-2002年农业、工业和服务业的月度GDP产值。具体创建代码如下
# 0. 模块导入
import numpy as np
import pandas as pd
np.random.seed(42)
# 1.函数定义
def random_uf_series(count,dmin,dmax):
'''
1. 功能:数目为count,在[dmin,dmax]区间的随机数
2. 输入:
count: 数目 int
dmin: 随机数下限 int
dmax: 随机数上限 int
3. 输出
rus:随机数序列 list
'''
num = 1
rus = []
while num <= count:
rus_temp = np.random.uniform(dmin,dmax)
rus_temp = round(rus_temp,2)
rus.append(rus_temp)
num += 1
return rus
# 2. 测试数据生成
province = pd.DataFrame(['A']*36+['B']*36,columns=['Province'])
year_month = pd.date_range('1/2000',periods=12*3,freq='m')
year = pd.DataFrame(data = year_month.year,columns=['Year'])
year = year.append(year,ignore_index=True) # 因为是A,B两个省
month = pd.DataFrame(year_month.month,columns=['Month'])
month = month.append(month,ignore_index=True)
agriculture_gdp = pd.DataFrame(random_uf_series(36*2,6,9),columns=['Agr_GDP'])
industry_gdp = pd.DataFrame(random_uf_series(36*2,9,12),columns=['Indu_GDP'])
service_gdp = pd.DataFrame(random_uf_series(36*2,12,15),columns=['Serv_GDP'])
economic_condiction = province.join([year,month,agriculture_gdp,industry_gdp,service_gdp])
print(economic_condiction)
测试数据形式如下图所示:
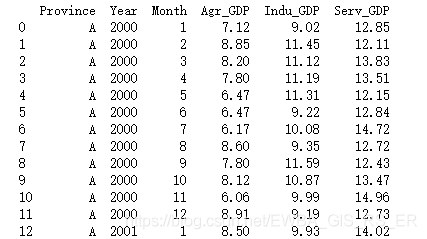
1. 选取DataFrame中特定列满足某一条件的子数据框
(1)选取economic_condiction数据框中Agr_GDP大于8的子数据框
eco_con_agr_gt8 = economic_condiction.loc[economic_condiction['Agr_GDP']>8]
print(eco_con_agr_gt8)
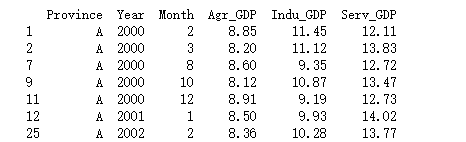
(2)选取economic_condiction数据框中Agr_GDP大于8且Indu_GDP大于10的子数据框
eco_con_choose = economic_condiction.loc[(economic_condiction['Agr_GDP']>8)\
& (economic_condiction['Indu_GDP']>10)]
print(eco_con_choose )
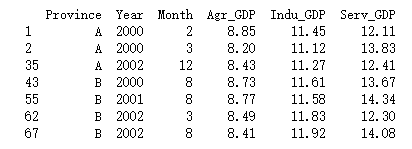
注意: 由于运算符之间的优先级关系,economic_condiction[‘Agr_GDP’]>8和economic_condiction[‘Indu_GDP’]>10需要分别加括号。
2. 利用Pandas自带函数实现数据框的聚合,进而筛选数据
数据聚合实际上是关系型数据库中的常用术语,基于Pandas自带的数据聚合函数,也可以进行数据筛选。
(1) 对economic_condiction数据框按照Province列进行分组,并分别打印
eco_con_by_province = eco_con_choose.groupby('Province')
print(type(eco_con_by_province))
print('***************************************')
num = 0
for name, group in eco_con_by_province:
num += 1
print('Group',num,name)
print(group)
print('******************************************')
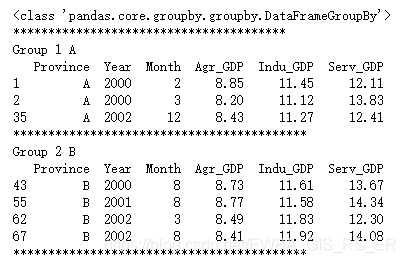
(2) 对economic_condiction数据框按照Province列和Year列共同进行分组,并分别打印
eco_con_by_province = eco_con_choose.groupby(['Province','Year'])
print(type(eco_con_by_province))
print('***************************************')
num = 0
for name, group in eco_con_by_province:
num += 1
print('Group',num,name)
print(group)
print('******************************************')
