PySpark学习案例——北京空气质量分析
下方有数据可免费下载
目录
- 原始数据
- 环境
- 各个组件所遇到的问题
- 各种webUI端口
- Python代码
- azkaban调度
- kibana可视化
原始数据
下载数据: 请点击我.提取码:736f
或者登录:http://stateair.net/web/historical/1/1.html
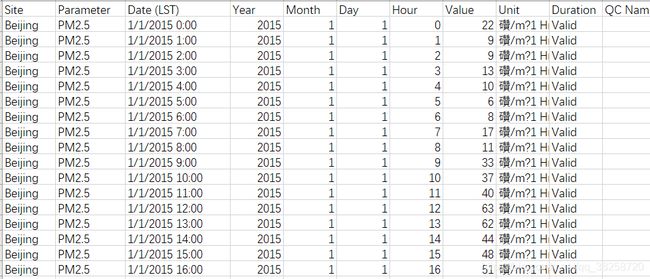
原始数据(北京2015年的空气质量):
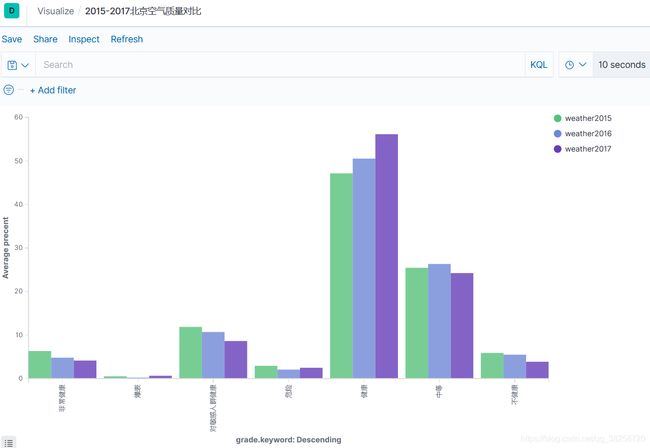
 本次分析的目的只是简单的对比北京2015,2016,2017这3年的PM值,最后用柱状图表示出来。
本次分析的目的只是简单的对比北京2015,2016,2017这3年的PM值,最后用柱状图表示出来。
环境
作业运行环境:
系统:centos7
JDK:1.8.0_91
Python:3.6.8
azkaban:3.81.0(需要编译好的安装包可以私信我)
spark:2.4.3-bin-hadoop2.6
kibana:7.7.1
elasticsearch:7.7.1
开发环境:
系统:Win10
PyCharm:2020.1
Python:3.8.1
开启的进程:
45120 Jps
29361 SecondaryNameNode
29035 NameNode
29179 DataNode
30151 NodeManager
30027 ResourceManager
28157 Elasticsearch
43729 AzkabanExecutorServer
43917 AzkabanWebServer
各个组件所遇到的问题
1.azkaban的编译最让人痛苦(搞了整整一天)
主要参考博客:https://blog.csdn.net/qq_42784606/article/details/106191408
并且每次启动AzkabanWebServer前都要命令行中输入:
curl http://hadoop000:12321/executor?action=activate(出现任何问题,直接看日志是最好的解决方法)
2.elasticsearch和kibana官网下载很慢,用华为镜像
elasticsearch:https://mirrors.huaweicloud.com/elasticsearch/
kibana:https://mirrors.huaweicloud.com/kibana/
3.elasticsearch因为内存问题无法启动
主要参考博客:https://blog.csdn.net/y506798278/article/details/94312445
elasticsearch启动时说jdk要11,这个可以忽略,用8依然可以
各种webUI端口
yarn:8088
kibana:5601
elasticsearch:9200
azkaban:8443(此端口为SSL端口,原端口为8081)
Python代码
weather3.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
//根据value值来判定grade
def get_grade(value):
if 50 >= value >= 0:
return "健康"
elif value <= 100:
return "中等"
elif value <= 150:
return "对敏感人群健康"
elif value <= 200:
return "不健康"
elif value <= 300:
return "非常健康"
elif value <= 500:
return "危险"
elif value > 500:
return "爆表"
else:
return None
//udf函数
grade_function_udf = udf(get_grade, StringType())
if __name__ == '__main__':
spark = SparkSession.builder.appName("weather").getOrCreate()
//数据保存到hdfs中
//option("header", "true")表示原始数据的第一行作为列名,option("inferSchema", "true")会自动判定每一列的数据类型
Data2017 = spark.read.format("CSV").option("header", "true").option("inferSchema", "true").load(
"/weather/Beijing_2017_HourlyPM25_created20170803.csv").select("Year", "Month", "Day", "Hour", "Value")
Data2016 = spark.read.format("CSV").option("header", "true").option("inferSchema", "true").load(
"/weather/Beijing_2016_HourlyPM25_created20170201.csv").select("Year", "Month", "Day", "Hour", "Value")
Data2015 = spark.read.format("CSV").option("header", "true").option("inferSchema", "true").load(
"/weather/Beijing_2015_HourlyPM25_created20160201.csv").select("Year", "Month", "Day", "Hour", "Value")
//通过grade进行分组,并计算每组的数量
group2017 = Data2017.withColumn("Grade", grade_function_udf(Data2017['Value'])).groupBy("Grade").count()
group2016 = Data2016.withColumn("Grade", grade_function_udf(Data2016['Value'])).groupBy("Grade").count()
group2015 = Data2015.withColumn("Grade", grade_function_udf(Data2015['Value'])).groupBy("Grade").count()
//计算每组的数量所占总数的百分比
result2017_2 = group2017.select("Grade", "count").withColumn("precent", group2017['count'] / Data2017.count() * 100)
result2016_2 = group2016.select("Grade", "count").withColumn("precent", group2016['count'] / Data2016.count() * 100)
result2015_2 = group2015.select("Grade", "count").withColumn("precent", group2015['count'] / Data2015.count() * 100)
//数据的列名修改后,将数据写入到elasticsearch中
result2017_2.selectExpr("Grade as grade", "count", "precent").write.format("org.elasticsearch.spark.sql").option(
"es.nodes", "hadoop000:9200").mode("overwrite").save("weather2017/pm")
result2016_2.selectExpr("Grade as grade", "count", "precent").write.format("org.elasticsearch.spark.sql").option(
"es.nodes", "hadoop000:9200").mode("overwrite").save("weather2016/pm")
result2015_2.selectExpr("Grade as grade", "count", "precent").write.format("org.elasticsearch.spark.sql").option(
"es.nodes", "hadoop000:9200").mode("overwrite").save("weather2015/pm")
spark.stop()
azkaban调度
文件一:weather.job
type=command
command=sh ./wea.sh
文件二:wea.sh(spark提交作业的脚本)
/home/hadoop/app/spark-2.4.3-bin-hadoop2.6/bin/spark-submit --master yarn --jars ./elasticsearch-spark-20_2.11-7.7.1.jar ./weather3.py
文件三:elasticsearch-spark-20_2.11-7.7.1.jar(可在maven仓库下载)
文件四:weather3.py(就是上方的python代码)
//将4个文件打包
zip weather.zip weather3.py weather.job wea.sh elasticsearch-spark-20_2.11-7.7.1.jar
kibana可视化
运行的结果图如下所示: