python为自己龟蜗速更新的小说生成词云
文章目录
-
- python 词云的hello word
- 中文词语的显示问题
- 使用jieba进行分词
- 一个完整的例子
-
- stopwords
- 最终效果
- 素材来源
python 词云的hello word
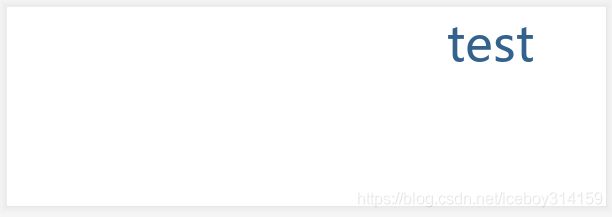
下边几行代码可以算是python词云的hello word,要安装WordCloud才可以运行(pip install wordcloud),直接运行,会发现生成了一个词test的词云。
from wordcloud import WordCloud
import os
wc = WordCloud(
background_color="white",
max_words=300,
# font_path="./msyh.ttc",
min_font_size=10,
max_font_size=49,
width=600
)
wc.generate('test')
wc.to_file("wdc.png")
os.system(".\wdc.png")
中文词语的显示问题
我们把上述代码略微改一下,生成一个稍微正常一点儿的多个词的词云,可是生成的是一个个的框框。。。
from wordcloud import WordCloud
import os
wc = WordCloud(
background_color="white",
max_words=300,
#font_path="./msyh.ttc",
min_font_size=10,
max_font_size=49,
width=600
)
wc.generate('你好,这里,那里,而且,哈哈')
wc.to_file("wdc.png")
os.system(".\wdc.png")

现在我们把注释掉的那一行加上,OK了。msyh.ttc是微软雅黑字体的意思。从windows/Fonts目录下直接拷贝过来的。
from wordcloud import WordCloud
import os
wc = WordCloud(
background_color="white",
max_words=300,
font_path="./msyh.ttc",
min_font_size=10,
max_font_size=49,
width=600
)
wc.generate('你好,这里,那里,而且,哈哈')
wc.to_file("wdc.png")
os.system(".\wdc.png")

使用jieba进行分词
要为一篇文章或一本书生成词云,首先得把这连续的句子分成一个一个的中文词汇,python中可以用jieba完成这样的工作。下边是一个例子,
我这里使用
pip install jieba总是安装失败,换成pip3 install jieba就好了
import jieba
seg_list = jieba.cut("冯丙虎哼了一声,当年突厥数千人突袭便桥,我百十兄弟追随冯立将军,将其杀退,用的正是此刀,足下今天是要试试么!")
print(",".join(seg_list))
输出如下,
PS F:\1-own\0-code\word_cloud> python test.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\XIAOQI~1\AppData\Local\Temp\jieba.cache
Loading model cost 1.051 seconds.
Prefix dict has been built successfully.
冯丙虎,哼,了,一声,,,当年,突厥,数千,人,突袭,便桥,,,我,百十,兄弟,追随,冯立,将军,,,将,其,杀退,,,用,的,正是,此刀,,,足下,今天,是,要,试试,么,!
一个完整的例子
# encoding=utf-8
import jieba
from jieba import analyse
import os
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
txt = open("xyxs.txt", "r", encoding='utf-8').read()
seg_list = jieba.cut(txt)
segSentence=''
for word in seg_list:
if word != '\t':
if word not in stopwords:
segSentence += word + ","
cloud_test = ",".join(seg_list)
from wordcloud import WordCloud
wc = WordCloud(
background_color="white",
max_words=300,
font_path="./msyh.ttc",
min_font_size=10,
max_font_size=49,
width=600
)
wc.generate(segSentence)
wc.to_file("pic.png")
os.system(".\pic.png")
stopwords
代码中的一个文件stopwords.txt片段如下,这个stopwords.txt是自己编的,不是很完善,可以看到最终生成的词云中有一些,“正在”,“一边”之类的词。
已经
知道
没有
自己
之后
不是
就是
最终效果

素材来源
下边是可以跳过的内容,属于个人的广告行为>_<. 若是有兴趣的可以捧个人场。
本文中生成词云的素材来自于最近在写的一篇历史武侠类的小说雪夜箫声,关注可以看到。更新的速度比较龟速,现在写到的是玄武门和上清宗,马上也要更新了。
