【kafka】--- kafka介绍基本结构和基本概念
Kafka 是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated )、基于ZooKeeper 协调管理的分布式流平台的功能强大的消息系统。与传统的消息系统相比, Kafka能够很好地处理活跃的流数据,使得数据在各个子系统中高性能、低延迟地不停流转。
Kafka定位是一个分布式流处理平台,他具有以下三个特性:
①:能够允许发布和订阅数据。更像是一个消息队列或者消息系统
②:存储流数据时提供相应的容错机制
③:当流数据到达时能够及时处理
kafka中的基本概念
topic(主题):一个主题其实就是对消息的一个分类,也就是将一组特定的消息归纳为一个主题,生产者需要将消息发送到特定的主题,消费者通过订阅主题或主题的某些分区进行消费。
message(消息):消息是kafka通信的基本单位,消息由一个固定的消息头和一个可变长的消息体构成。在老版本中,没一条消息称为message,在Java实现的客户端中,没一条消息被称为record。
分区(partition):Kafka将一组消息归纳为一个主题,而每个主题被分为一个或多个分区(partition),每个分区由一系列有序、不可变的消息组成,是一个有序队列。每个分区在物理上对应为一个文件夹,分区的命名:“主题名—分区编号”,分区编号从0开始。每个主题对应的分区数可以在kafka启动时所加载的配置文件中进行配置,也可以在在创建主题时指定其分区数,当然客户端还可以在主题创建后修改主题的分区数。作用:分区数越多,一般吞吐量会越高,分区也使得Kafka进行顺序消费以及负载均衡。kafka只能保证一个分区之内消息的有序性,因为每条消息被追加到相应的分区,并且是顺序写磁盘,因此效率比较高;
副本(Replica):每个分区由一个或多个副本,分布在集群的不同代理上,以便提高可用性,从存储角度上分析,分区的每个副本在逻辑上抽象为一个日志对象(Log),分区的副本与日志对象是一一对应的;
Leader副本和Follower副本:由于kafka副本的存在,就需要保证一个分区的多个副本之间数据的一致性,Kafka会选择该分区的一个副本作为leader副本,而分区的其他副本作为Follower副本,只有leader副本处理客户端读、写请求,Follower副本从leader副本同步消息,假如没有Leader副本就需要(n*n)条通路来同步数据,有了leader后,只需要(n-1)条通路。
偏移量:任何发布到分区中的消息都会被直接追加到日志文件中(分区目录下以“.log”)为文件名后缀的数据文件的尾部,每条消息在日志文件中的位置都会对应一个按序递增的偏移量,偏移量是一个分区下严格有序的逻辑值。
日志段:一个日志对应多个日志段(LogSegment),一个日志段对应于磁盘上一个具体的日志文件(以“.log”结尾的数据文件)和两个索引文件(“.index”消息偏移量索引文件和“.timeindex”消息时间戳索引文件)。
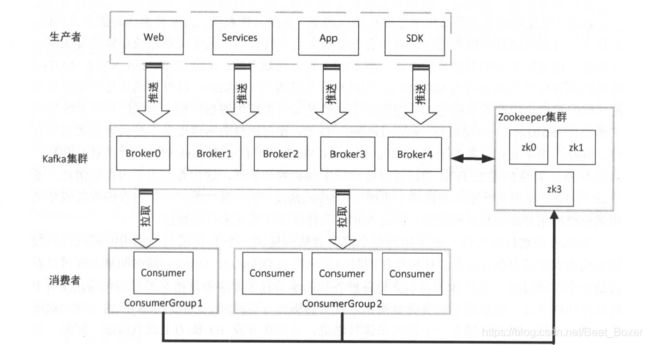
代理(broker):kafka集群一般是由一个或多个Kafka实例构成,kafka实例即为一个代理,称为broker,每一个kafka实例都有唯一标识的id,这个id是一个非负整数,这个Id被称为brokerId
生产者(Producer):生产者负责将消息发送给kafka,也就是向Kafka代理(broker)发送消息的客户端。
消费者(Consumer)和消费组(ConsumerGroup):消费者以拉取pull方式拉取数据,他是消费的客户端。在kafka中,每一个消费者属于一个特定的消费组,用groupId代表消费组名称,通过group.id进行配置,如果不指定消费组,则默认为消费组test-consumer-group.。同时每一个消费者也有一个全局唯一的Id,通过client.id进行配置,如果为配置,则会默认生成(${groupId}-${hostName}-${timestamp}-${UUID});
同步副本列表(ISR):kafka在ZooKeeper中动态维护了一个ISR(In-sync-Replica),此中保存了同步的副本列表,即为所有与Leader副本保持消息同步的所有Follower副本对应的代理节点id,如果某一个follower副本宕机,则该Follower副本节点id将从ISR列表中移除。
kafka集群结构:
kafka对消息的处理:kafka不会删除立即被消费掉的消息,由于磁盘大小的有限,也不会一直存储消息;所以就有了Kafka对消息的处理,其可以通过配置文件进行配置,一是基于消息已存储的时间长度,二是基于分区的大小进行处理。