SQL使用了索引,为什么还是很慢
数据库的查询性能一直是性能优化的重灾区。近期看了丁奇老师的分享“为什么SQL语言使用了索引,但却还是慢查询?”,收获颇丰,以此做个记录
0 准备
创建一张测试表,设置主键索引(id)和普通索引(a) ,如下:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入两行测试数据
insert into t values(1,1,1),(2,2,2);
1 定义慢查询
我们来看一下官网对慢查询的定义
The slow query log consists of SQL statements that take more than
long_query_timeseconds to execute and require at leastmin_examined_row_limitrows to be examined.
mysql的慢查询与语句的执行时间有关,mysql会将语句的执行时间与系统设置的long_query_time这个参数做对比,如果执行时间time > long_query_time并且扫描的行数超过min_examined_row_limit, 则会被认为是慢查询,并将该语句到慢查询日志中。
查看mysql的long_time_time设置
mysql > show variables like 'long_query_time%';
## 如下所示,慢查询设置的时间为10秒
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
查看慢查询日志的地址
mysql > show variables like '%slow_query_log%';
## slow_query_log 表示慢查询日志是否开启
## slow_query_log_file 表示慢查询日志的地址
+---------------------+-------------------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /usr/local/mysql/data/ali-186590d5fadf-slow.log |
+---------------------+-------------------------------------------------+
2 定义是否使用索引
对于一个语句,是否使用索引的意思是:这个语句在执行过程中是否使用到了索引。具体到表象中,是explain一个语句的时候,输出结果里key的值不是NULL
mysql > explain select * from t ;
## 如下key为null,表示未使用索引
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | t | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
mysql> explain select * from t where id =2;
## 如下key为primary,表示使用了主键索引
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | t | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
mysql> explain select a from t ;
## 如下key为a,表示使用了a这个普通索引
+----+-------------+-------+-------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t | index | NULL | a | 5 | NULL | 2 | Using index |
+----+-------------+-------+-------+---------------+------+---------+------+------+-------------+
看上面的结果可以知道,2和3都使用了索引,但是他们的扫描行数(rows这一个字段)是不同的,2使用主键索引其扫描行数为1条,3使用了普通索引其扫描的行数是2条,由于总记录数是2条,所以3的方式几乎是全表扫描了。如果总记录数达到100万条,2的方式还是会很快,而3的方式其扫描的行数也将达到100万条,查询就会很慢。
但是这并不代表2的方式肯定不是慢查询,因为在极端情况下,如果mysql所在机器的cpu负载很高,2方式查询的执行时间超过了long_query_time,那么它就会被记录到慢查询日志中。
3. 慢查询与索引的关系
看了上述1,2就明白了,是否是慢查询与是否使用索引其实并无关系
慢查询: 慢查询与语句的执行时间相关,当语句的执行时间超过long_query_time,那么它就是慢查询
索引: 是否使用索引描述了语句的执行过程
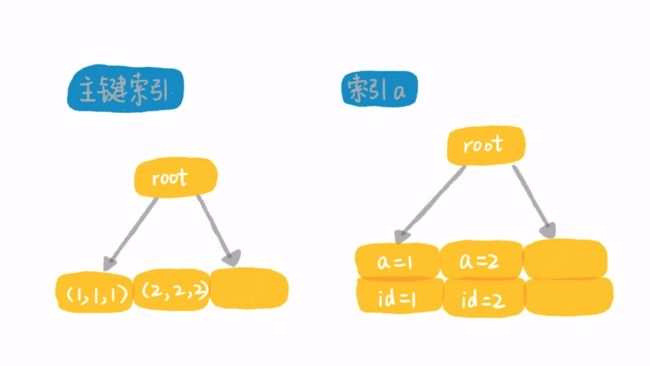
4. 解析使用索引
在InnoDB中,数据都是存储在主键索引上的,如图所示。一行的所有信息都存储在主键索引上(所以InnoDB在查询过程中必然会扫描主键索引树),而普通索引上只记录了普通索引与对应主键索引的映射关系
那么在语句执行过程中,使用了主键索引,就一定不是全表扫描吗? 不一定,如下,虽然key为primary了,但是扫描行数还是全表扫描。优化器认为该语句需要使用主键索引定位到id>0的行,所以认为该执行使用了主键索引,
mysql> explain select * from t where id >0;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | t | range | PRIMARY | PRIMARY | 4 | NULL | 2 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
因此,我们需要理清几个概念:
全表扫描: 我们平时说的使用了全表扫描,指的并不是说语句不使用索引,而是该语句遍历了整个主键索引树 (select * from t where id > 0)
全索引扫描:指的是语句扫描了整个普通索引树(select a from t )
索引扫描: 指的是语句使用了索引的快速搜索功能,并且有效地减少了扫描行数(select * from t where id =2)
4.1 索引的过滤性
除了全索引扫描,还有哪些使用了索引但执行速度不够快的例子呢?
假设现在你维护了一张表记录了全国人的基本信息,需要查找所有年龄在10~15岁之间的姓名和基本信息。该语句为:
select * from t_people where age between 10 and 15
一般我们会认为这样的语句需要在age上建立索引,否则它就会变成全表扫描。但是最后你会发现,即使在age上建立了索引,执行的速度还是很慢,因为符合条件了记录数有上亿行。该语句的执行过程如下:
- 在age索引上找到age=10的第一个索引
- 根据索引对应的主键id,回表到主键索引上取整行数据
- 从age索引继续向下搜索,重复步骤2,直到碰到age > 15结束
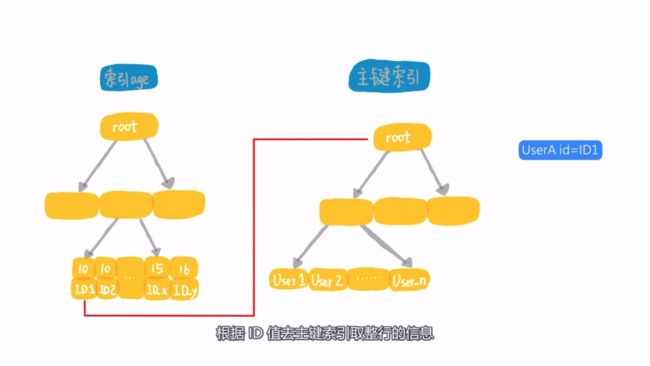
由于上述的执行过程中符合条件的记录数超过上亿行,因此执行的时间会很长,它会被记录到慢查询中。而上述select a from t虽然也是全索引扫描,但是还是比这个全索引扫描的要快,因此它只扫描了2行。因此,语句执行速度的快慢与扫描的行数息息相关,所以我们在讨论索引的时候关心的是扫描行数,因此索引要有效,就要提高索引的过滤性,减少语句的扫描行数。上述的age索引过滤性就不够。
那么过滤性足够好了,扫描的行数就一定少呢?
如下有一个(name,age)联合索引,如果执行语句是 select * from t_people where name =‘张三’ and age = 8,那么该联合索引的过滤性非常不错,扫描的行数也会很少,执行的效率较高
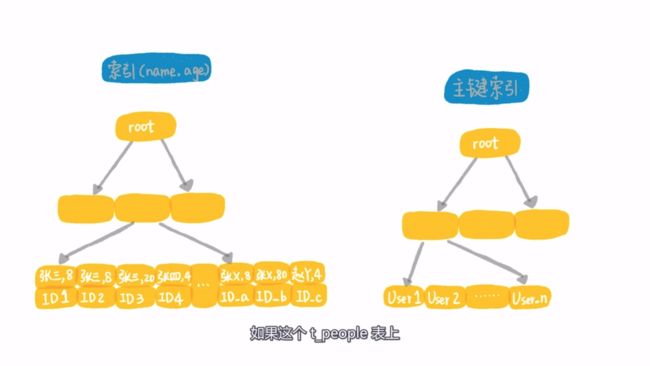
但是查询的过滤性和索引的过滤性不一定是一样的,如果现在的需求是
select * from t_prople where name like ‘张%’ and age =8
在mysql 5.5及之前的版本中,这个语句的执行流程如下:
- 在联合索引上查找第一个名字为张的联合索引
- 取出联合索引对应的主键id,回表到主键索引中获取整行速度并对比age是否为8
- 继续在联合索引中向下扫描,重复2,直到碰到第一个名字不为张结束
可以看到,上述的执行过程中,最耗费时间的就是2步骤的回表。假设全国第一个名字开头是张的有8000万,那么这个执行过程就需要回表8000万次。为什么联合索引需要回表取判断age是否为8? 这是因为在使用联合索引的时候,只能使用联合索引的最左前缀,这被称为最左前缀原则。
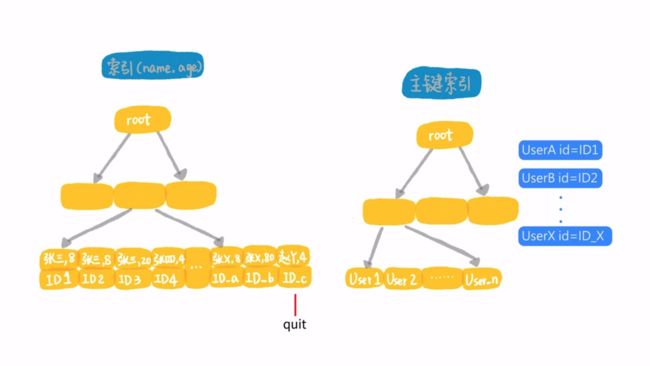
在mysql 5.6版本引入了一个优化方案,该优化方案是在联合索引中先判断age是否为8(将判断下推到索引搜索过程中),如果是才回表取出整行数据,假设名字开头是张的有8000万,其中age=8的有1000万行,那么该查询只需要回表1000万次,这会大大减少回表的次数。
但是该查询还是要扫描8000万行的记录,是否可以继续优化,减少扫描行数呢?
我们可以把名字的第一个字和年龄做一个联合索引,我们可以使用mysql 5.7引入的新特性:虚拟列,来实现
alter table t_people add name_first varchar(2) generated always as (left(name,1)), add index(name_first,age);
如上,虚拟列name_first永远自动生成并等于name列的前两个字节。并根据虚拟列生成了一个新的联合索引(name_first,age)。有了这个新的联合索引,我们就可以通过以下语句来优化执行语句
select * from t_prople where name_first = ‘张’ and age =8
假设结果是1000万行,那么该语句只需要扫描1000万行,回表1000万次。这个优化的本质是我们创建了一个过滤性更好的索引。
我们使用索引,或者说索引优化的过程,实质上是减少扫描行数的过程
5. 问题
5.1 什么是SQL的执行时间 ?
sql语句的执行时间并不包含其获取锁的等待时间,而且慢查询日志插入的时间是在sql语句释放所有锁之后,因此日志顺序和执行顺序很可能是不同的
5.2 我在where中使用了普通索引字段,系统一定会使用全索引扫描吗?
不一定,系统可能会走全表扫描,这取决与系统的判断。判断来源于系统的预测,也就是说,如果要走 c 字段索引的话,系统会预测走 c 字段索引大概需要扫描多少行。如果预测到要扫描的行数很多,它可能就不走索引而直接扫描全表了。
5.3 如果查询的字段上有索引,查询语句一定会使用索引扫描吗?
不一定,查询优化器在选择查询计划的时候,会对不同查询计划进行评估(通过一个cost function),选择它认为执行最快的查询计划。
5.4 优化器使用的索引不满意,可以自行指定sql使用的索引吗?
是可以的,使用use index来指定sql执行使用的索引,这是一种优化手段,具体可看: https://www.cnblogs.com/edwardlost/archive/2010/12/31/1923105.html
6. 本文摘录及参考自:
###1. The Slow Query Log - MySQL :: Developer Zone
###2. 为什么我加了索引,SQL执行还是这么慢*(一)? - 李佳霖i - 博客园
###3. https://www.zhihu.com/question/49738281?sort=created