NLP系列文章(四)——ELMO
接文章《NLP系列文章(一)——按照学习思路整理发展史》《NLP系列文章(二)——NLP领域任务分类、NNLM语言模型》《NLP系列文章(三)——word embedding》继续讲述NLP预训练的那些事
ELMO是“Embedding from Language Models”的简称,论文《Deep contextualized word representation》。
在此之前的Word Embedding本质上是个静态的方式,也就是训练好后单词的表达固定不变,在新任务使用的时候,不论新句子上下文是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变。
所以对于比如Bank这个词,它事先学好的Word Embedding中混合了几种语义 ,在应用中,遇到从上下文中明显可以看出它是“银行”含义的句子,其对应的Word Embedding也不会变,它还是混合了多种语义。这是为何说它是静态的,这也是问题所在。
ELMO的本质思想:
先用LM训练好单词的Word Embedding,虽然这时无法区分多义词,不过这没关系。在新任务实际使用Word Embedding的时候,单词具备了特定的上下文,在这个环境下,再根据上下文语义去调整单词的Word Embedding。
这样经过调整后,Word Embedding就具备了表示联系上下文的具体含义,这样也就解决了多义词的问题。
综上,我们能发现ELMO本身是个根据当前上下文对Word Embedding进行动态调整的过程。
ELMO结构:
ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词 网络各层的Word Embedding作为新特征加入下游任务中。
1>预训练
下图是ELMO预训练过程,它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词Wi的上下文去正确预测单词Wi,Wi之前的单词序列称为上文,之后的单词序列称为下文。图中左侧的双层LSTM代表正向encoder,是从左到右的顺序输入Wi的上文;右侧的双层LSTM代表逆向encoder,是从右到左的顺序输入Wi的下文;
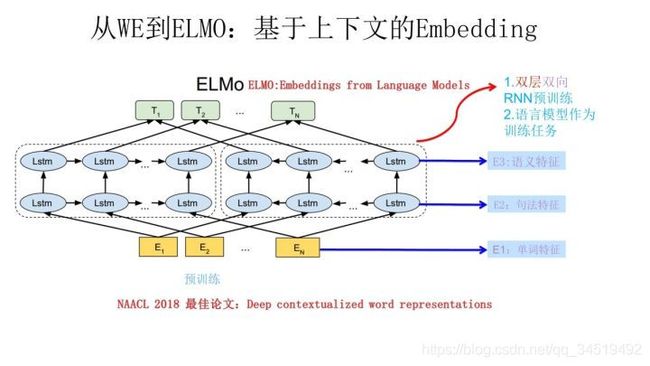
一个单词一个encoder,每个encoder都是双层LSTM的叠加。这个网络结构在NLP领域是常见的,用这个网络结构做LM实现预训练,之后输入一个新句子Snew,句子的每个单词都能得到相应的三个embedding:
①最底层Ex是word embedding,包含单词特征;②接着第一层LSTM的embedding,包含句法特征更多;③在往上第二层LSTM的embedding,包含语义信息更多。
ELMO的预训练过程的产物有两个:①主产品→word embedding②副产品→双层双向LSTM网络。他们两者再后来都有用。
2>下游任务
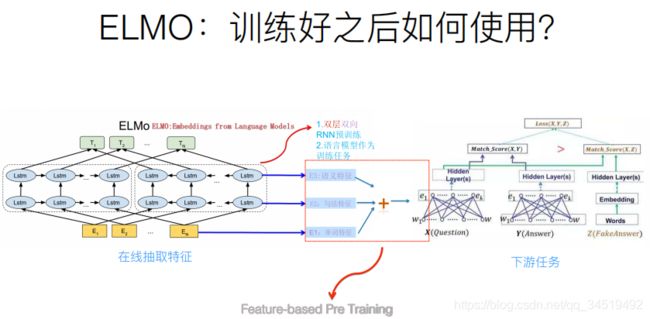
预训练好网络结构后,如何用于下游任务?下图是下游任务的使用过程。
还是针对QA这个下游任务,将问句X输入到预训练好的ELMO网络,获得每个单词的三个Embedding,之后给每一个Embedding一个权重a【权重可学习】,根据各自权重累加求和,将预训练得到的三个embedding整合为一个。然后将整合后的Embedding作为X句在任务的那网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
对于下图所示的下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。至于为何这么做能够达到区分多义词的效果,你可以想一想,其实比较容易想明白原因。
谁是开山之作?
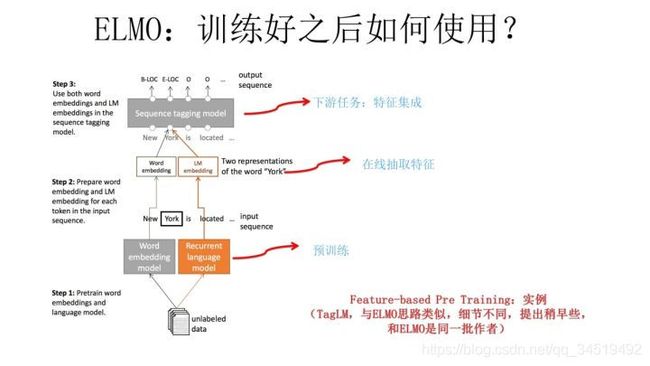
而下图是TagLM采用类似ELMO的思路做NER任务的过程。
TagLM是2017年ACL会议的论文,作者是AllenAI里ELMO的人马,可以将TagLM看做ELMO的一个前导工作。也有人认为18年4月FastAI提出的ULMFiT才是抛弃传统Word Embedding引入新模式的开山之作,其实各有道理。
分析一下为什么说将TagLM看做ELMO的前导工作?
TagLM比ULMFiT出现的更早,结构模式和ELMO基本相似;不将ULMFiT作为前驱者的原因如下:
①ULMFiT结构为三阶段:通用语言模型训练后引入一个领域语言模型【论文的重点也在这里,且方法复杂】,我们知道引入预训练的原因之一就是要解决缺乏领域数据模型训练效果不佳的问题,领域数据不足还将大量的经历放在这里可能不是很合适,毕竟我们最终要的是一个大规模有效的embedding。所以还是回归到通用模型上比较好;
②ULFMiT做了6个任务,都集中在分类问题,应用相对比较窄,不如ELMO验证的问题领域广,这应该就是其中领域语言模型带来的限制。
ELMO获得NAACL2018最佳论文当之无愧,相比ACL很多最佳论文好很多。
所以综合看,尽管ULFMiT也是个不错的工作,但是重要性跟ELMO比至少还是要差一档,当然这是我个人看法。每个人的学术审美口味不同,我个人一直比较赞赏要么简洁有效体现问题本质要么思想特别游离现有框架脑洞开得异常大的工作,所以ULFMiT我看论文的时候就感觉看着有点难受,觉得这工作没抓住重点而且特别麻烦,但是看ELMO论文感觉就赏心悦目,觉得思路特别清晰顺畅,看完暗暗点赞,心里说这样的文章获得NAACL2018最佳论文当之无愧,比ACL很多最佳论文也好得不是一点半点,这就是好工作带给一个有经验人士的一种在读论文时候就能产生的本能的感觉,也就是所谓的这道菜对上了食客的审美口味。——张俊林
前面提到静态Word Embedding无法解决多义词的问题,那么ELMO引入上下文动态调整单词的embedding后 多义词问题解决了吗?
当然毋庸置疑解决了,而且解决得还要好。
如下图这个例子,对于Glove训练出的Word Embedding,根据 多义词play 的embedding找出的最接近的单词大多数集中在体育领域,这很明显是因为训练数据中 包含play的句子中 体育领域的数量 占优;
而使用ELMO,根据上下文动态调整后的embedding不仅能够找出对应的“演出”的相同语义的句子,而且还可以保证找出的句子中的play对应的词性也是相同的,这是超出期待之处。这是因为ELMO预训练模型结构的 第一层LSTM编码了很多句法信息。

ELMO效果如何呢?
实验效果如下图,6个NLP任务中性能都有幅度不同的提升,最高的提升达到25%左右,而且这6个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。

上面讲述了ELMO的思想、结构、应用、开山作之争、效果;那么它有什么缺点导致它没有成为里程碑式的创新?
ELMO有什么值得改进的缺点呢?
①一个非常明显的缺点在特征抽取器的选择上,ELMO使用了LSTM而不是新贵Transformer,Transformer是谷歌在17年做机器翻译任务发表的《Attention is all you need》论文中提出的,引起了相当大的反响,很多研究已经证明了Transformer提取特征的能力是要远强于LSTM的。如果ELMO采取Transformer作为特征提取器,那么估计Bert的反响也不会像现在这样激烈。
②ELMO采取双向拼接这种融合特征的方式,这种方式的能力可能比Bert一体化的融合特征方式弱一些【仅仅是猜想,后续有证据,单拉出来讲】,我们如果把ELMO这种预训练方法和图像领域的预训练方法对比,发现两者模式看上去还是有很大差异的。
除了以ELMO为代表的这种基于特征融合的预训练方法外,NLP里还有一种典型做法,这种做法和图像领域的方式就是看上去一致的了,一般将这种方法称为“基于Fine-tuning的模式”,而GPT就是基于Fine-tuning的模式的典型开创者
