NLP系列文章(五)——发展历程中的GPT、BERT
接文章《NLP系列文章(一)——按照学习思路整理发展史》《NLP系列文章(二)——NLP领域任务分类、NNLM语言模型》《NLP系列文章(三)——word embedding》《NLP系列文章(四)——发展历程中的ELMO》继续讲述NLP预训练的那些事
来源看系列文章(一)其次真的很感谢 张俊林,继续崇拜
GPT是“Generative Pre-Training”的简称,生成式的预训练。
GPT也采用两阶段结构,①语言模型进行预训练,②通过Fine-tuning的模式解决下游任务。
1>预训练
下图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:
①特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;
②GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文,这限制了其在更多应用场景的效果,比如阅读理解,在做任务的时候是可以允许同时看到上文和下文一起做决策的。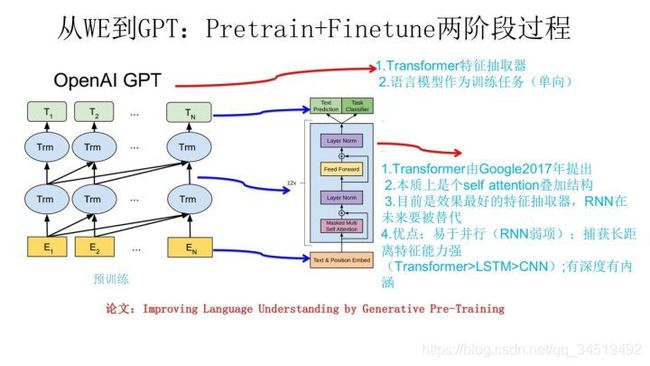
2>下游任务怎么用?
它有自己的个性,和ELMO的方式大有不同。如下图所示。
①对于不同的下游任务,要求其网络结构和GPT的一致,所以要改造下游任务网络。然后,利用第一步预训练好的参数 初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到当前任务里了。
②用新任务去训练这个网络,对网络参数进行Fine-tuning,使得这个网络更适合解决当前问题。
【发现这和之前讲的图像领域的预训练思路是一致的】
怎么改造五花八门的NLP任务模型结构,才能靠近GPT的网络结构呢?
GPT论文中给出改造模型图如下
①分类问题:加上一个起始和终结符号即可;
②句子关系判断问题:如Entailment,两个句子中间再加个分隔符即可;
③文本相似性判断问题:把两个句子顺序颠倒,做出两个输入即可,这是为了告诉模型句子顺序不重要;
④多项选择问题:则多路输入,每一路把文章和答案选项拼接作为输入即可。
从图可知,这种改造还是很方便的,不同任务只需要在输入部分修改即可。
GPT效果如何?
GPT的效果是非常令人惊艳的,在12个任务里,9个达到了最好的效果,有些任务性能提升非常明显。
GPT有什么值得改进的地方呢?
其实最主要的就是单向语言模型。
Bert
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于:①预训练阶段采用了类似ELMO的双向语言模型,②语言模型的数据规模要比GPT大。
Fine-Tuning阶段,这个阶段的做法和GPT是一样的。也面临着下游任务网络结构改造的问题,在改造任务方面Bert和GPT有些不同。
正如前面所讲,NLP下游任务可分为四类,其中各包含很多任务。对于种类如此繁多而且各具特点的下游NLP任务。
Bert如何改造输入输出部分使得大部分NLP任务都可以使用Bert预训练好的模型参数呢?
①句子关系类任务:和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号CLS对应的Transformer最后一层位置上面串接一个softmax分类层即可。
②分类问题:与GPT一样,只需要增加起始和终结符号,输出部分同上。
③序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
从这里可以看出,NLP四大任务里面,除了生成类任务外,Bert其它都覆盖到了,而且改造起来很简单直观。
其实对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在S2S结构【sequence to sequence】上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。
当然,也可以更简单一点,比如直接在单个Transformer结构上加装隐层产生输出也是可以的。
不论如何,从这里可以看出,NLP四大类任务都可以比较方便地改造成Bert能够接受的方式。这其实是Bert的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性,这是很强的。
bert效果如何?
在11个各种类型的NLP任务中达到目前最好的效果,某些任务性能有极大的提升。
8、word2vec、ELMO、GPT、BERT演进关系

从上图可见,如果把GPT预训练阶段换成双向语言模型,那么就得到了Bert;如果把ELMO的特征抽取器换成Transformer,那么也会得到Bert。
所以可以看出:Bert最关键两点,一点是特征抽取器采用Transformer;第二点是预训练的时候采用双向语言模型。
对于Transformer来说,怎么才能在这个结构上做双向语言模型任务呢?
直观做法:只需要把ELMO的两个LSTM替换成两个Transformer,一个负责正向,一个负责反向提取特征即可。而Bert没这么做。
那么Bert是怎么做的呢?
前面说word2vec的时候提到了CBOW方法,bert的处理方法和它很像:在做语言模型任务的时候,将要预测的单词mask掉,然后根据它的上下文预测单词。【bert论文中讲这个思路是来自完形填空,但是梳理过来表面上还是和CBOW相似的】
模型上似乎没有很大的创新,但是效果很好、普适性也很强。
Bert本身在模型和方法角度有什么创新?
Masked 语言模型和Next Sentence Prediction。
而Masked语言模型上面讲了,本质思想类似CBOW,但是细节方面有改进。
Masked语言模型做法:
随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。
但是这里有个问题:训练过程看到大量的[mask]标记,但最后并不会有这个标记的。
这就会导致模型认为输出是针对[mask]这个标记的,但是实际并没有这个标记,这就会产生问题。
为了避免,Bert选取语料15%做掩码改造,同时这15%中只有80%被替换成[mask],10%被随机换成另一个单词,10%还在保持不变。
Next Sentence Prediction:指的是做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另一种是第二个句子从语料库中随机选一个拼到第一个句子后面。
这就要求模型除了做Masked语言模型任务,还要再做一个句子关系预测,判断第二个句子是不是第一个句子的后续句子。主要是考虑到很多NLP下游任务是句子关系判断,单词级的预测训练到不了句子关系这个层级,增加NSP有助于下游句子关系判断任务。所以BERT的预训练是个多任务过程【创新点】
BERT的输入
BERT的输入部分是个线性序列,两个句子通过分隔符[SEP]分割,最前面和最后增加两个标识符号;
每个单词有三个embedding:
①位置信息embedding:因为NLP中单词顺序是很重要的特征,需要在这里对位置信息进行编码;
②单词embedding:这个就是之前一直提到的单词embedding;
③句子embedding:论文中训练的时候都是由两个句子构成的,那么每个句子都要有表示为同一个句子的embedding赋给每个单词。
把每个单词的三个embedding叠加,就形成了Bert的输入。
Bert在预训练的输出处理
Bert效果特别好的原因是什么?
跟GPT相比,双向语言模型起到了最主要的作用,尤其是针对下游任务。
NSP对整体性能影响不算太大,跟具体任务关联度比较高。
对Bert的评价和看法
Bert借鉴了ELMO,GPT及CBOW,主要提出了Masked 语言模型及Next Sentence Prediction,但是这里Next Sentence Prediction基本不影响大局,而Masked LM明显借鉴了CBOW的思想。
所以说Bert的模型没什么大的创新,更像最近几年NLP重要进展的集大成者,这点如果你看懂了上文估计也没有太大异议。
归纳进展:
①两阶段模型,第一阶段双向语言模型预训练,第二阶段采用具体任务Fine-tuning或者特征集成;
②特征抽取用Transformer而不是RNN或者CNN;
③双向语言模型可以采取CBOW的方法去做
Bert最大的亮点在于效果好及普适性强,几乎所有NLP任务都可以套用Bert这种两阶段解决思路,而且效果应该会有明显提升。