XGBoost4J-Spark 1.0.0运行流程与排坑指南
XGBoost4J-Spark配置全解
- 0.前言
- 1.确认版本
- 2.Maven配置
- 3.代码
- 4.运行
- 5.评价
0.前言
XGBoost4J-Spark能够让我们在Spark上玩XGBoost,对于海量数据来说应该是很有用的。这篇文章主要介绍了将其官网提供的Demo部署在Linux上运行的全过程。通过此Demo在Spark上用XGBoost完成iris数据集的多分类任务。
此次选用的是最新的稳定版XGBoost4J-Spark 1.0.0,之前0.81版本的Windows部署可以参考这里。不过其实都是互通的,两边都看看也无妨。我这里会将我选择、填坑时的思路全部记录下来,需要注意的地方我会用这样进行标注,以供你参考,(●´З`●)。
1.确认版本
作为最基础的demo,要考虑的版本包括:
- XGBoost4J-Spark
- Scala
- Spark
- Python
- Hadoop
- Java
在安装之前一定要根据自己的配置选择合适的版本,确保两两之间版本契合,否则后面会报一堆错。我选择的版本如下:
| 模块 | 版本号 |
|---|---|
| XGBoost4J-Spark | 1.0.0 |
| Scala | 2.11.8 |
| Spark | 2.4.5 |
| Python | 3.5.2 |
| Hadoop | 2.6 |
| Java | 1.8.0 |
具体考量如下:首先是选择了当前的最新稳定版——1.0.0的XGBoost4J-Spark,然后在它的官网文档里发现0.9之后的版本仅支持Spark2.4+了,具体原因摘抄在下面:
XGBoost4J-Spark now requires Apache Spark 2.4+. Latest versions of XGBoost4J-Spark uses facilities of org.apache.spark.ml.param.shared extensively to provide for a tight integration with Spark MLLIB framework, and these facilities are not fully available on earlier versions of Spark.
但我Spark是卑微的2.2.0,只能重新装一个高版本了。然后选择了Spark 2.4.5 Prebuild for Apache Hadoop 2.6。这里Hadoop的版本2.6.0就确定好了,好在Hadoop和Spark互通这块网上排坑指南比较多,在实际操作时这块也没出问题,甚至我用的是hadoop-2.6.0-cdh5.7.0也没啥问题,好评。然后这里有个点请注意一下,在Spark下载界面有这么一段话:
Note that, Spark is pre-built with Scala 2.11 except version 2.4.2, which is pre-built with Scala 2.12.
所以对于Spark 2.4.5来说,给咱们的jars是基于Scala 2.11的(当然你也可以选择 Pre-built with Scala 2.12 and user-provided Apache Hadoop这个版本,然而我试了一下发现在spark-submit这个版本的时候坑太多了,比起填这个坑还是转Scala2.11简单点,遂弃之)。
于是Scala的大版本也确定好了,在选择Scala的时候小心每个小版本里也有很多更迭,导致一些方法找不到,最后在尝试过很多小版本后敲定了Scala 2.11.8,至少在这个Demo里没有表现出特别的问题。
另外提一嘴Python,版本需要2.7+,尽量就Python 3+就完事了,不然会在训练的时候报错ImportError: No module named argparse,从而导致出现XGBoostError: XGBoostModel training failed这种诡异的错误。
JDK就是1.8.0,没啥好说的,也没出问题,就写在这以防有老哥要看。
2.Maven配置
要注意各个版本的一一对应,要查包的对应版本的话请在MvnRepository里查找关键字。
这里直接放整体的pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.taipark.xgboostgroupId>
<artifactId>sonarAnalysisartifactId>
<version>1.0version>
<inceptionYear>2008inceptionYear>
<properties>
<scala.version>2.11.8scala.version>
properties>
<repositories>
<repository>
<id>scala-tools.orgid>
<name>Scala-Tools Maven2 Repositoryname>
<url>http://scala-tools.org/repo-releasesurl>
repository>
repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.orgid>
<name>Scala-Tools Maven2 Repositoryname>
<url>http://scala-tools.org/repo-releasesurl>
pluginRepository>
pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>ml.dmlcgroupId>
<artifactId>xgboost4j-spark_2.11artifactId>
<version>1.0.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.4.5version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.11artifactId>
<version>2.4.5version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
<args>
<arg>-target:jvm-1.5arg>
args>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-eclipse-pluginartifactId>
<configuration>
<downloadSources>truedownloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilderbuildcommand>
buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanatureprojectnature>
additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINERclasspathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINERclasspathContainer>
classpathContainers>
configuration>
plugin>
plugins>
build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
configuration>
plugin>
plugins>
reporting>
project>
3.代码
配置好之后就要开始写代码了,代码在xgboost的文档里说的其实还是蛮清楚的,这里把完整的能运行的代码放出来理解一下:
注:代码是用Scala编写的。
首先是import:
import org.apache.spark.ml.feature.{
StringIndexer, VectorAssembler}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{
DoubleType, StringType, StructField, StructType}
import ml.dmlc.xgboost4j.scala.spark.XGBoostClassifier
创建SparkSession:
val spark = SparkSession.builder().getOrCreate()
根据数据集设置Schema:
val schema = new StructType(Array(
StructField("sepal length", DoubleType, true),
StructField("sepal width", DoubleType, true),
StructField("petal length", DoubleType, true),
StructField("petal width", DoubleType, true),
StructField("class", StringType, true)
))
导入数据,使其与Schema一一对应,这里注意数据在转为csv的时候不要使用UTF-8之类的编码,而是使用Windows默认编码,不然会导致XGBoost识别分类数量错误从而报有关num_class的错误:
val dataPath = args(0)
val rawInput = spark.read.schema(schema).csv(dataPath)
这里的class列是用String表示的,我们要将其转化为Double类型,可以使用StringIndexer来转换:
val stringIndexer = new StringIndexer()
.setInputCol("class")
.setOutputCol("classIndex")
.fit(rawInput)
val labelTransformed = stringIndexer.transform(rawInput).drop("class")
将转换后的列classIndex替换之前的列class:
val vectorAssembler = new VectorAssembler()
.setInputCols(Array("sepal length","sepal width","petal length","petal width"))
.setOutputCol("features")
val xgbInput = vectorAssembler.transform(labelTransformed)
.select("features","classIndex")
将数据八二分为训练集与测试集:
val splitXgbInput = xgbInput.randomSplit(Array(0.8, 0.2))
val trainXgbInput = splitXgbInput(0)
val testXgbInput = splitXgbInput(1)
设置XGBoost的参数,需要特别注意的是num_workers的值需要小于等于之后传进spark-submit的master的值,即XGBoost用到的线程要小于Spark启的线程:
val xgbParam = Map(
"eta" -> 0.1f,
"max_depth" -> 2,
"objective" -> "multi:softprob",
"num_class" -> 3,
"num_round" -> 100,
"num_workers" -> 2
)
创建XGBoost函数,并且展示了另一种设置参数的方法,这里需要注意只要你是用分布式进行训练,那么setTreeMethod(“approx”)是一定要设置的,不然最后在训练的时候JVM会报Core dump written:
//创建xgb函数,指定特征向量与标签
val xgbClassifier = new XGBoostClassifier(xgbParam)
.setFeaturesCol("features")
.setLabelCol("classIndex")
xgbClassifier.setMaxDepth(2)
xgbClassifier.setTreeMethod("approx")
参数设置完毕,开始训练:
val xgbClassificationModel = xgbClassifier.fit(trainXgbInput)
进行预测:
val result = xgbClassificationModel.transform(testXgbInput)
展示并停止:
result.show(1000)
spark.stop()
最后再放一个完整的代码:
package com.taipark.xgboost
import org.apache.spark.ml.feature.{
StringIndexer, VectorAssembler}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{
DoubleType, StringType, StructField, StructType}
import ml.dmlc.xgboost4j.scala.spark.XGBoostClassifier
object IrisAnalysis {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark = SparkSession.builder()
.getOrCreate()
//设置schema
val schema = new StructType(Array(
StructField("sepal length", DoubleType, true),
StructField("sepal width", DoubleType, true),
StructField("petal length", DoubleType, true),
StructField("petal width", DoubleType, true),
StructField("class", StringType, true)
))
//导入数据
val dataPath = args(0)
val rawInput = spark.read.schema(schema).csv(dataPath)
//将class由string转为double
val stringIndexer = new StringIndexer()
.setInputCol("class")
.setOutputCol("classIndex")
.fit(rawInput)
val labelTransformed = stringIndexer.transform(rawInput).drop("class")
//拼合组成整体数据集
val vectorAssembler = new VectorAssembler()
.setInputCols(Array("sepal length","sepal width","petal length","petal width"))
.setOutputCol("features")
val xgbInput = vectorAssembler.transform(labelTransformed)
.select("features","classIndex")
//将数据切分为训练集与测试集
val splitXgbInput = xgbInput.randomSplit(Array(0.8, 0.2))
val trainXgbInput = splitXgbInput(0)
val testXgbInput = splitXgbInput(1)
//设置xgb参数
val xgbParam = Map(
"eta" -> 0.1f,
"max_depth" -> 2,
"objective" -> "multi:softprob",
"num_class" -> 3,
"num_round" -> 100,
"num_workers" -> 2
)
//创建xgb函数,指定特征向量与标签
val xgbClassifier = new XGBoostClassifier(xgbParam)
.setFeaturesCol("features")
.setLabelCol("classIndex")
xgbClassifier.setMaxDepth(2)
xgbClassifier.setTreeMethod("approx")
//开始训练
val xgbClassificationModel = xgbClassifier.fit(trainXgbInput)
//预测
val result = xgbClassificationModel.transform(testXgbInput)
//展示
result.show(1000)
spark.stop()
}
}
4.运行
打包后上传Linux服务器,需要一并上传的内容包括:
- 数据集.csv
- 打包好的jar包
- xgboost4j_2.11-1.0.0.jar
- xgboost4j-spark_2.11-1.0.0.jar
后面两个jar包需要单独上传上去,这两个文件应该在Maven的仓库里,可以用IDEA找,或者用Everything直接在Windows里找。
首先需要将数据集放在HDFS里,然后运行spark-submit:
./spark-submit \
--master local[2] \
--class com.taipark.xgboost.IrisAnalysis \
--jars /home/hadoop/lib/xgboost4j-spark_2.11-1.0.0.jar,/home/hadoop/lib/xgboost4j_2.11-1.0.0.jar \
/home/hadoop/lib/sonarAnalysis-1.0.jar hdfs://hadoop000:8020/tai/iris.csv
其中传入的第一个local[2]的2要大于等于之前设置的num_workers,这个之前说过了。其他的根据你自己放的位置引就可以了。
最后给个跑出来的结果:
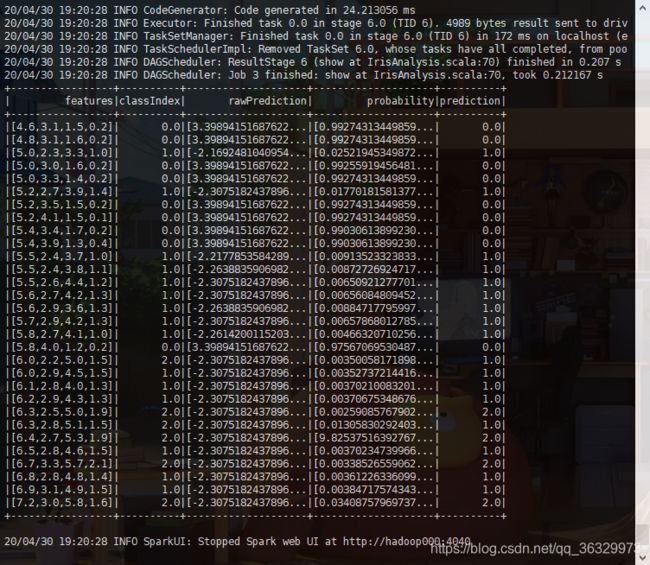
5.评价
用AUC来对模型进行评价,在预测和展示之后、spark.stop()之前加入如下代码段即可:
//评价
val scoreAndLabels = result.select(xgbClassificationModel.getPredictionCol,xgbClassificationModel.getLabelCol)
.rdd.map{
case Row(score: Double,lable: Double) => (score,lable)}
val metric = new BinaryClassificationMetrics(scoreAndLabels)
val auc = metric.areaUnderROC()
println("auc:" + auc)
如果对你有用,就给个关注吧,(●´З`●)