HDFS 原理史上最详细解析(包含 2.x 版本)
HDFS 原理史上最详细解析(包含 2.x 版本)
-
- 1. 背景
- 2. 架构
-
- 2.1 Moving Computation is Cheaper than Moving Data
- 2.2 The File System Namespace
- 2.3 BlockId
- 2.4 数据校验
- 2.5 元数据备份与恢复
-
- 2.5.1 Secondary NameNode
- 2.5.2 Checkpoint Node
- 2.5.3 Backup Node
- 2.5.4 Recovery Mode
- 2.6 NameNode HA
- 2.7 Multiple NameNodes/Namespaces
- 2.8 配额
- 2.9 访问接口
- 2.10 集中的缓存管理
-
- 2.10.1 主要解决了哪些问题
- 2.10.2 架构和原理
- 2.10.3 对应用的影响
- 2.11 HDFS读写流程
-
- 2.11.1 HDFS中的block、packet、chunk
- 2.11.2 读流程
- 2.11.3 写流程
- 2.11.3 读写流程如何保证一致性❗️
- 2.11.4 透明、端到端数据加密
- 2.11.5 多宿主网络
- 2.11.6 归档存储,SSD,内存
1. 背景
HDFS最初是参考谷歌GFS论文原理开发的一个开源产品,由Lucene开源项目的创始人Doug Cutting开发,现在已经成为大数据平台的基石。HDFS借鉴了GFS的技术架构,在设计理念上又与GFS有很大的不同,它致力于提供一个通用的分布式文件系统,与GFS作为Google内部存储系统的定位有很大区别。
HDFS定义了一套文件系统API规范(http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/filesystem/index.html),确立了HDFS的核心模型,为用户提供了一个稳定的依赖。
HDFS的核心模型:
- 名称
HDFS文件、目录的命名规则,及其逻辑关系,与Linux普通文件系统看起来几乎一模一样。
- 原子性
在HDFS中,创建文件、删除文件、重命名文件、重命名目录、创建目录都是原子操作。递归删除目录也是原子操作。
- 一致性
HDFS的一致性模型是”复制-更新“语义,我理解就是是强一致模型。
Create、Update、Delete、Delete then create、Rename操作,在操作结束后,结果必须对后续的访问可见。
- 并发
HDFS对并发操作没有数据隔离保证。假如一个Client在访问文件的同时,另一个Client正在修改文件,那么修改的内容可能可见,也可能不可见。
- 操作失败
所有操作必须最终完成,要么成功,要么失败。
实现通过重试来保证操作成功,前提是保证一致性语义,并且重试操作对Client透明。
- 超时
HDFS对操作的超时没有定义。
在HDFS中,阻塞操作超时实际上是可变的,因为站点和客户机可能会调优重试参数,从而将文件系统故障和故障排除程序转换为操作中的暂停。取而代之的是一种普遍的假设,即FS操作“快但没有本地FS操作快”,并且数据读写的延迟随数据量的增加而增加。客户机应用程序的这种假设揭示了一个更基本的假设:文件系统性能接近网络延迟和带宽上线。
对于某些操作的开销也有一些隐含的假设。seek()操作非常快,几乎不会造成网络延迟。对于条目较少的目录,目录列表操作非常快。
- vs 对象存储
HDFS与对象存储(例如S3)有明显的不同,
- 对象存储是最终一致性模型。也就是说,一个操作的结果,要经过一段时间才能被所有的Client看到,在此之前,Client可能访问到过期数据。
- 原子性。对象存储没有目录的概念,虽然可以通过基于文件名前缀的操作,来达到类似的效果,比如通过删除前缀/user的文件,来达到删除/user目录的效果,但这不是一个原子操作,而是一个文件一个文件的独立操作。
- 持久性。HDFS和传统文件持久化非常相近,调用flush,close,文件以流的形式不停得更新到存储。而对象存储只有对文件操作结束后的时刻,才把完整的文件PUT到存储系统。
- 权限。HDFS提供传统文件系统的用户、组权限管理概念,对象存储通常没有。
2. 架构
HDFS架构和GFS非常相近
2.1 Moving Computation is Cheaper than Moving Data
这是HDFS的一个设计预期和目标,也是Hadoop大数据处理的精髓所在。
2.2 The File System Namespace
HDFS目标是做一个通用文件系统,支持传统的文件、目录概念。在这方面,GFS更像一个对象存储,它不支持文件系统模型。
2.3 BlockId
根据[1],早期block id是一个64位数随机数。当时实现比较简单,并没有判重,所以如果两个block碰巧得到同样的block id,系统会误认为是多余的备份block,而将其中一个删除。这样这个block很有可能会出错,包含它的文件则损坏。解决的办法有两个,一是记录好所有使用过的block id,以实现判重功能;二是以一种不会重复的方式生成block id,比如顺序生成。顺序生成的缺点有三个,一是现有的系统迁移困难,所有的block都要重新命名;二是用完了64位数后仍然有麻烦;三是要记录好最高的block id。
判重并不是最优的方法,因为它需要额外的工作,而且随着文件系统变得庞大将变重。假设用一个Hash实现判重,一个1PB的文件系统,假设1个block大小64MB,则包含有16M个block id,每个id为8个byte,则需要一个128MB的Hash表,这对于一个本身就很复杂的NameNode是个不小的压力。[2]中提出了一种综合的方法,给一个文件的所有block指定一个相同的range id(5个byte)作为它们block id的高位,然后按顺序每个block生成剩余的3个byte。较之前的单纯判重,好处在于减小了判重的数量;同时又方便管理同一个文件的block,因为它们的block id是连续的。[2]也指出这种方法的问题,当一个文件被删除时,此range id要从系统中抹去,如果此时某个包含此文件某block的数据结点掉线了,在它重新上线之后,它又带回这个已经无效的range id。所以需要timestamps,即creation time of the file,当两个文件碰巧有相同的range id时,根据timestamps来判定谁是最新的文件,旧的文件将被删除。[2]中能看到Doug Cutting和Sameer Paranjpye的一些其它討論,比如range-id也采用顺序生成(又回到随机VS顺序的问题上)。
[1] potential conflict in block id’s, leading to data corruption
https://issues.apache.org/jira/browse/HADOOP-146
[2] dfs should allocate a random blockid range to a file, then assign ids sequentially to blocks in the file
https://issues.apache.org/jira/browse/HADOOP-158
[3] Sequential generation of block ids
https://issues.apache.org/jira/browse/HDFS-898
2.4 数据校验
硬盘故障、网络错误或软件漏洞,都可能造成数据损坏。客户端创建文件时,会针对文件的每一个Block计算校验码,并把校验码存储在相同命名空间一个单独的因此文件中。当客户端读数据时,会使用这些校验码进行数据验证。如果校验失败,客户端会从其他副本重新拉取文件。
这一点上HDFS与GFS差异明显。GFS数据校验是在chunkserver上做的,并且是对每一个64K的块计算一个校验码,应用程序也需要构建自己的记录校验码,因为GFS文件可能中可能存在填充数据、重复数据。而HDFS是强一致模型,各副本在字节上完全一致,所以客户端可以直接使用每一个Block的校验码进行数据校验。
2.5 元数据备份与恢复
2.5.1 Secondary NameNode
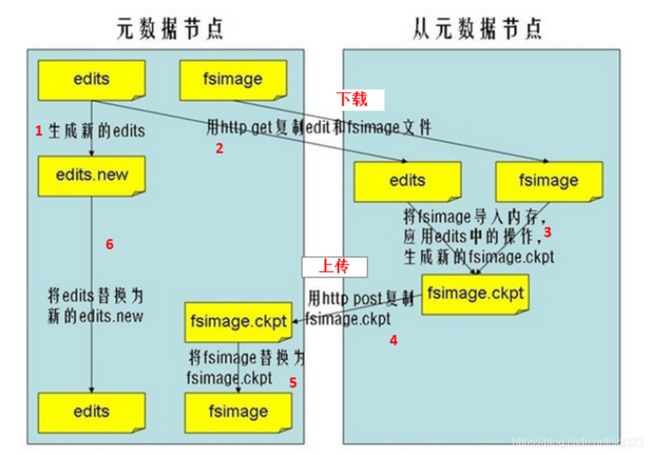
Secondary NameNode不是NameNode的备份。它的作用是:定期合并fsImage和editsLog,并推送给NameNode,辅助恢复NameNode(editsLog越大NameNode恢复越慢)。
Secondary NameNode的作用现在可以被CheckpointNode和BackupNode替换掉。CheckpointNode 和 BackupNode 是 2.x 版本的 Hadoop 才有的。
Secondary NameNode定期合并流程,如下图所示。
2.5.2 Checkpoint Node
CheckpointNode和SecondaryNameNode的作用以及配置完全相同。
2.5.3 Backup Node
Backup Node在内存中维护了一份从Namenode同步过来的fsimage,同时它还从namenode接收edits文件的日志流,并把它们持久化硬盘,Backup Node把收到的这些edits文件和内存中的fsimage文件进行合并,创建一份元数据备份。Backup Node高效的秘密就在这儿,它不需要从Namenode下载fsimage和edit,把内存中的元数据持久化到磁盘然后进行合并即可。
配置了BackupNode以后,NameNode自身不再需要持久化存储,而是把这个职责完全委托给BackupNode。
目前,hadoop集群只支持一个Backup Node,如果Backup Node出了问题,Hadoop元数据的备份机制也就失效了,所以hadoop计划在未来能支持多个Backup Node。
2.5.4 Recovery Mode
当所有的元数据备份都失效时,可以启动Recovery模式,来恢复大部分数据。
2.6 NameNode HA
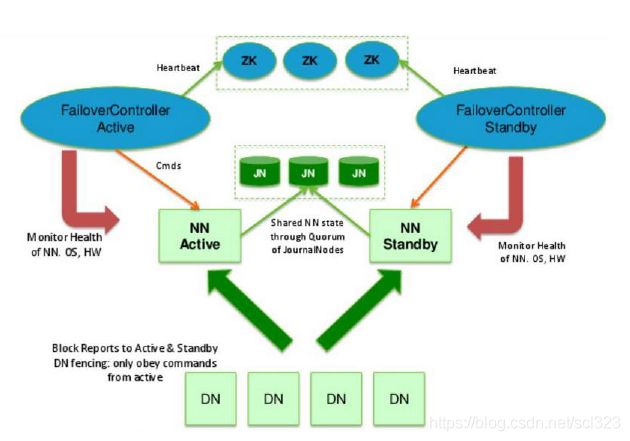
NameNode的HA,指的是在一个集群中存在两个NameNode,分别运行在独立的物理节点上。在任何时间点, 只有一个NameNodes是处于Active状态,另一种是在Standby状态。
Active NameNode负责所有的客户端的操作,而Standby NameNode用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
为了保证Active NameNode与Standby NameNode节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes” ,用来同步FsEdits信息。当Active NameNode执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NameNode负责观察JNs的变化,读取从Active NameNode发送过来的FsEdits信息,并更新其内部的命名空间。
一旦Active NameNode遇到错误, Standby NameNode需要保证从JNs中读出了全部的FsEdits, 然后切换成Active状态。
在这个图里,我们可以看出HA的大致架构,其设计上的考虑包括:
- 利用共享存储来在两个NN间同步edits信息。
共享存储有两个方案,一是通过NFS,在中高端的存储设备内部都有各种RAID以及冗余硬件包括电源以及网卡等,比服务器的可靠性还是略有提高。二是通过QJM集群,QJM集群有一个特性,数据写入只有被集群的大多数节点接受,才算写入成功,这也就保证任何时刻,只有一个NameNode可以写入数据。
- DataNode同时向两个NameNode汇报块信息。
这是让Standby NameNode保持集群最新状态的必需步骤。
- 用于监视和控制NN进程的FailoverController进程
显然,我们不能在NameNode进程内进行心跳等信息同步。最简单的原因,一次FullGC就可以让NameNode挂起十几分钟。所以,必须要有一个独立的短小精悍的watchdog来专门负责监控。这也是一个松耦合的设计,便于扩展或更改,目前版本里是用ZooKeeper(以下简称ZK)来做同步锁,但用户可以方便的把这个ZooKeeper FailoverController(以下简称ZKFC)替换为其他的HA方案或leader选举方案。
- 隔离(Fencing),防止脑裂,就是保证在任何时候只有一个主NameNode,包括三个方面:
共享存储fencing,确保只有一个NameNode可以写入edits。
客户端fencing,确保只有一个NameNode可以响应客户端的请求。
DataNode fencing,确保只有一个NameNode可以向DateNode下发命令,譬如删除,复制等等。
2.7 Multiple NameNodes/Namespaces
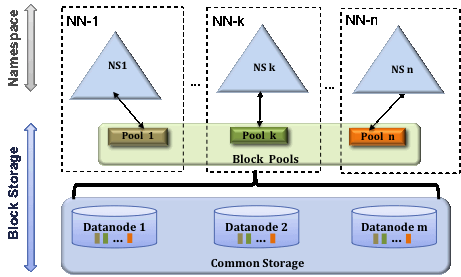
HDFS提供了一种水平扩展方案,即通过NameNode集群+共享DateNode的方式,支持多个独立的命名空间。
DateNode向集群的所有NameNode注册,周期性发送心跳,发送BlockReport。NameNode之间彼此不通信。
每一个NameNode维护自己的BlockPools,BlockPools在DataNode上被单独管理。因此,NameNode节点之间不需要任何同步,可以单独生成Block IDs。当一个NameNode发生故障时,不影响DateNode向其他的NameNode正常提供服务。
命名空间和它的BlockPool一起构成一个“卷”,它是一个独立管理的单位,当一个"卷"被删除时,BlockPool对应的Block也会被DateNode节点删除。在集群升级期间,每个命名空间卷作为一个单元进行升级。
这种方案带来的好处:
- 命名空间可扩展性:在使用小文件的场景中,可以从扩展多个命名空间获益。
- 性能:使性能不再局限于一个NameNode节点。
- 隔离:通过命名空间避免不同的应用,避免互相影响。
为了让多个命名空间对Client看起来还像是一个集群,可以使用ViewFs。这就像是Linux文件系统的挂载表,每个文件系统挂载在一个目录上,使用起来,看到的是一个命名空间,不必关心具体是由几个文件系统构成的。
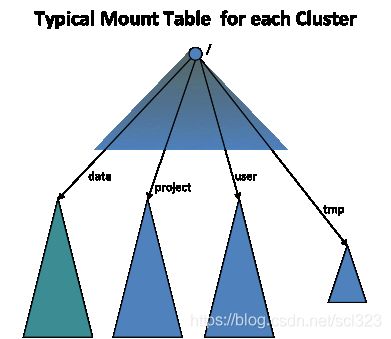
为了给Client提供一个统一视图,HDFS提供了一个Router方案,即通过Router代理Client对NameNode的请求,使多集群对Client透明。
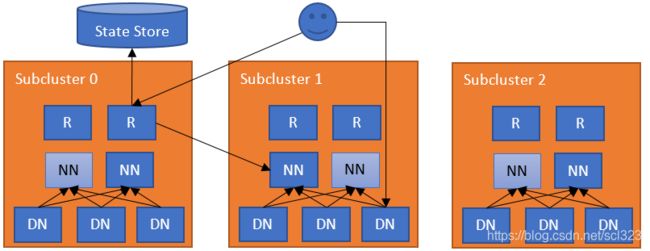
最简单的配置是在每个NameNode机器上部署Router。当ClientS访问文件系统中的文件时,路由器检查StateStore找出哪个子集群包含该文件, 然后代理请求到相应的NameNode。
2.8 配额
HDFS支持对一个目录下的子目录和文件数进行限额,对一个目录的存储空间限额,对一个目录在不同存储介质上的存储空间(DISK/SSD/ARCHIVE)。限额数据在NameNode被持久化保存。
2.9 访问接口
HDFS支持众多访问接口,包括:
- Shell
- 标准Java API
- HFTP
- C API libhdfs
- RestApi
- NFS GateWay
2.10 集中的缓存管理
HDFS提供了一种集中式缓存管理机制,允许用户指定HDFS缓存的路径。NameNode与存储相应下文件的DateNode进行通信,指示它们将块缓存到堆外缓存中。
2.10.1 主要解决了哪些问题
- 用户可以根据自己的逻辑指定一些经常被使用的数据或者高优先级任务对应的数据常驻内存而不被淘汰到磁盘。例如在Hive或Impala构建的数据仓库应用中fact表会频繁地与其他表做JOIN,显然应该让fact常驻内存,这样DataNode在内存使用紧张的时候也不会把这些数据淘汰出去,同时也实现了对于 mixed workloads的SLA。
- centralized cache是由NameNode统一管理的,那么HDFS client(例如MapReduce、Impala)就可以根据block被cache的分布情况去调度任务,做到memory-locality。
- HDFS原来单纯靠DataNode的OS buffer cache,这样不但没有把block被cache的分布情况对外暴露给上层应用优化任务调度,也有可能会造成cache浪费。例如一个block的三个replica分别存储在三个DataNote 上,有可能这个block同时被这三台DataNode的OS buffer cache,那么从HDFS的全局看就有同一个block在cache中存了三份,造成了资源浪费。
- 加快HDFS client读速度。过去NameNode处理读请求时只根据拓扑远近决定去哪个DataNode读,现在还要加入speed的因素。当HDFS client和要读取的block被cache在同一台DataNode的时候,可以通过zero-copy read直接从内存读,略过磁盘I/O、checksum校验等环节。
2.10.2 架构和原理
用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS centralized cache中。这个centralized cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
Client读取文件时向NameNode发送getBlockLocations RPC请求。NameNode会返回一个LocatedBlock列表给Client,这个LocatedBlock对象里有这个block的replica所在的DataNode和cache了这个block的DataNode。可以理解为把被cache到内存中的replica当做三副本外的一个高速的replica。
2.10.3 对应用的影响
对于HDFS上的某个目录已经被addDirective缓存起来之后,如果这个目录里新加入了文件,那么新加入的文件也会被自动缓存。这一点对于Hive/Impala式的应用非常有用。
HBase in-memory table:可以直接把某个HBase表的HFile放到centralized cache中,这会显著提高HBase的读性能,降低读请求延迟。
和Spark RDD的区别:多个RDD的之间的读写操作可能完全在内存中完成,出错就重算。HDFS centralized cache中被cache的block一定是先写到磁盘上的,然后才能显式被cache到内存。也就是说==只能cache读,不能cache写==。
目前的centralized cache不是DFSClient读了谁就会把谁cache,而是==需要DFSClient显式指定要cache==谁,cache多长时间,淘汰谁。目前也没有类似LRU的置换策略,如果内存不够用的时候需要client显式去淘汰对应的directive到磁盘。
现在还没有跟YARN整合,需要用户自己调整留给DataNode用于cache的内存和NodeManager的内存使用。
2.11 HDFS读写流程
2.11.1 HDFS中的block、packet、chunk
要把读写过程细节搞明白前,必须知道block、packet与chunk。
- block
这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不过不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
- packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间==传数据的基本单位==,默认64KB。
- chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行==数据校验的基本单位==,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk(追加操作如何计算chunk的校验码?)。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
2.11.2 读流程
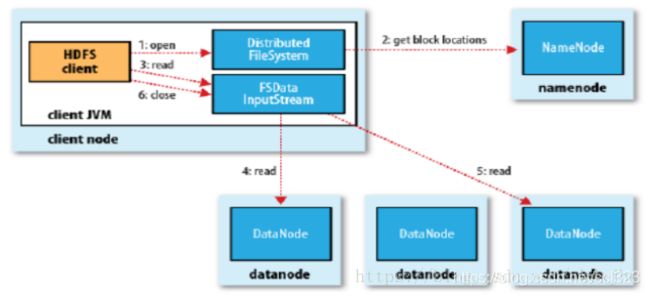
HDFS的读主要有三种: 网络I/O读 -> short circuit read -> zero-copy read。网络I/O读就是传统的HDFS读,通过DFSClient和Block所在的DataNode建立网络连接传输数据。
当DFSClient和它要读取的block在同一台DataNode时,DFSClient可以跨过网络I/O直接从本地磁盘读取数据,这种读取数据的方式叫short circuit read。
目前HDFS实现的short circuit read是通过共享内存获取要读的block在DataNode磁盘上文件的file descriptor(因为这样比传递文件目录更安全),然后直接用对应的file descriptor建立起本地磁盘输入流,所以目前的short circuit read也是一种zero-copy read。这需要在DataNode和Client做配置。
增加了Centralized cache的HDFS的读接口并没有改变。DFSClient通过RPC获取LocatedBlock时里面多了个成员表示哪个DataNode把这个block cache到内存里面了。如果DFSClient和该block被cache的DataNode在一起,就可以通过zero-copy read大大提升读效率。而且即使在读取的过程中该block被uncache了,那么这个读就被退化成了本地磁盘读,一样能够获取数据。
2.11.3 写流程

写详细步骤:
-
客户端向NameNode发出写文件请求。
-
检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功。
-
client端按128MB的块切分文件。
-
client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
注:并不是写好一个块或一整个文件后才向后分发
-
每个DataNode==写完一个==块后,会返回确认信息。
注:并==不是每写完一个packet后就返回确认信息==,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生。
-
写完数据,关闭输输出流。
-
发送完成信号给NameNode。
注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性。
在写数据的过程中,如果Pipeline数据流管道中的一个DataNode节点写失败了会发生什问题、需要做哪些内部处理呢?如果这种情况发生,那么就会执行一些操作:
首先,Pipeline数据流管道会被关闭,ack queue中的packets会被添加到data queue的前面以确保不会发生packets数据包的丢失;
接着,在正常的DataNode节点上的已保存好的block的ID版本会升级——这样发生故障的DataNode节点上的block数据会在节点恢复正常后被删除,失效节点也会被从Pipeline中删除;
最后,剩下的数据会被写入到Pipeline数据流管道中的其他两个节点中。
如果Pipeline中的多个节点在写数据时发生失败,那么只要写成功的block的数量达到==dfs.replication.min(默认为1)==,那么这个任务就是写成功的,然后NameNode会通过一步的方式将block复制到其他节点,最后使数据副本达到dfs.replication参数配置的个数。
在一个繁忙的HDFS集群当中,可能会发生DataNode写失败的情况。此时,NameNode就会把这个DataNode实例排除掉,去寻找新的可用DataNode。假如集群的可用DataNode数较少,找不到新的可用DataNode,文件无法恢复到要求的副本数,就会导致文件无法再写入。
解决办法有两个:
- 增加集群的机器数量。
- 修改配置,让写入的行为发生改变。dfs.client.block.write.replace-datanode-on-failure.enable配置默认是true,表示如果在写入的pipeline有datanode失败的时候是否要切换到新的机器。但是如果集群比较小的话,有两台机器失败的话,就没有其他机器可以切换了,所以把该配置设置成false后就能解决问题。
2.11.3 读写流程如何保证一致性❗️
通过校验和。因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。HDFS的client端即实现了对HDFS文件内容的校验和(checksum)检查。
当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个HDFS命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
HDFS中文件块目录结构具体格式如下:
${dfs.datanode.data.dir}/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073741825
│ │ │ ├── blk_1073741825_1001.meta
│ │ │ ├── blk_1073741826
│ │ │ └── blk_1073741826_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
in_use.lock表示DataNode正在对文件夹进行操作
rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。校验和也正是存在其中。
2.11.4 透明、端到端数据加密
2.11.5 多宿主网络
2.11.6 归档存储,SSD,内存
HDFS为分离冷热数据提供了支持,通过storagepolicies命令行工具可以指定一个目录(递归)或文件的存储策略。当然,必须首先在DateNode启用存储策略,并配置不同的存储介质。
- 存储类型:ARCHIVE, DISK, SSD and RAM_DISK
HDFS支持异构存储,DateNode支持多个存储,每个存储对应一种存储介质。
ARCHIVE:我理解这泛指高密度归档存储设备。
RAM_DISK:要求Client位于DataNode节点上,因为跨网络时延足以抵消内存写入带来的好处。
- 存储策略:Hot, Warm, Cold, All_SSD, One_SSD and Lazy_Persist
HDFS定义了集中存储策略,
- Hot - 热数据,有存储和计算的双重用途。所有的副本都存储在DISK。
- Cold - 冷数据,数据已经不再使用,仅仅是归档保存。所有副本存储在ARCHIVE。
- Warm - 温数据。部分副本存储在DISK,其他副本存储在ARCHIVE。
- All_SSD - 所有副本存储在SSD。
- One_SSD - 一个副本存储在SSD,其他副本存在在DISK。
- Lazy_Persist - 用于在内存中写入具有单个副本的块。副本首先在RAM_DISK中写入,然后在DISK中惰性持久化。