Linux实战之MySQL数据库——主从复制
MySQL高可用方案
低读低写并发、低数据量方案
方案一:双机高可用方案
(1)数据库架构图
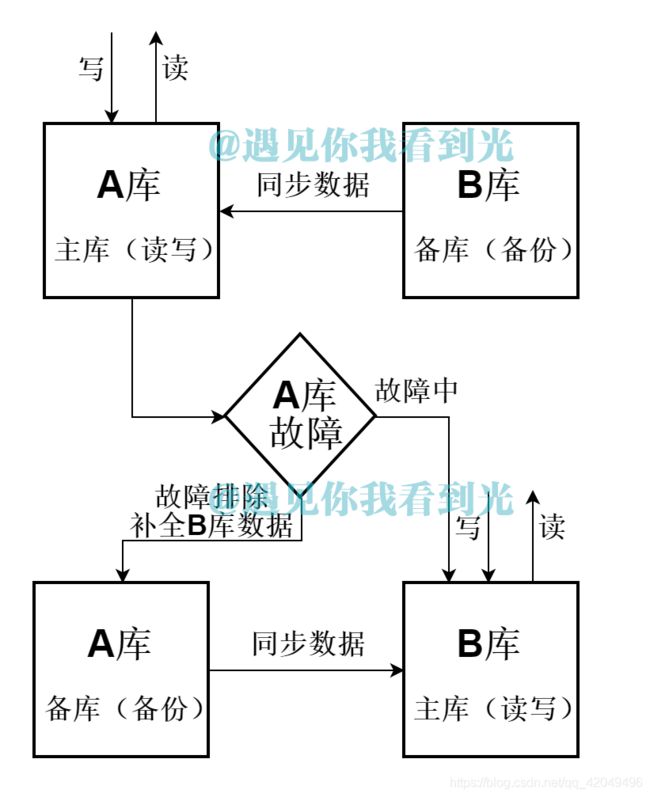
(2)特点
一台机器A作为读写库,另一台B作为备份库;A库故障后B库作为读写库;A库恢复后A作为备库。
(3)开发说明
此种情况下,数据源配置中的数据库IP地址,可采用虚拟的IP地址。虚拟IP地址由两台数据库机器上的keepalive配置,并互相检测心跳。当其中一台故障后,虚拟IP地址会自动漂移到另外一台正常的库上。
(4)适应场景
读和写都不高的场景(单表数据低于500万),双机高可用。
(5)优缺点
优点是一个机器故障了可以自动切换;缺点是只有一个库在工作,读写并未分离,并发有限制。
方案二:主从结构方案
(1)数据库架构图
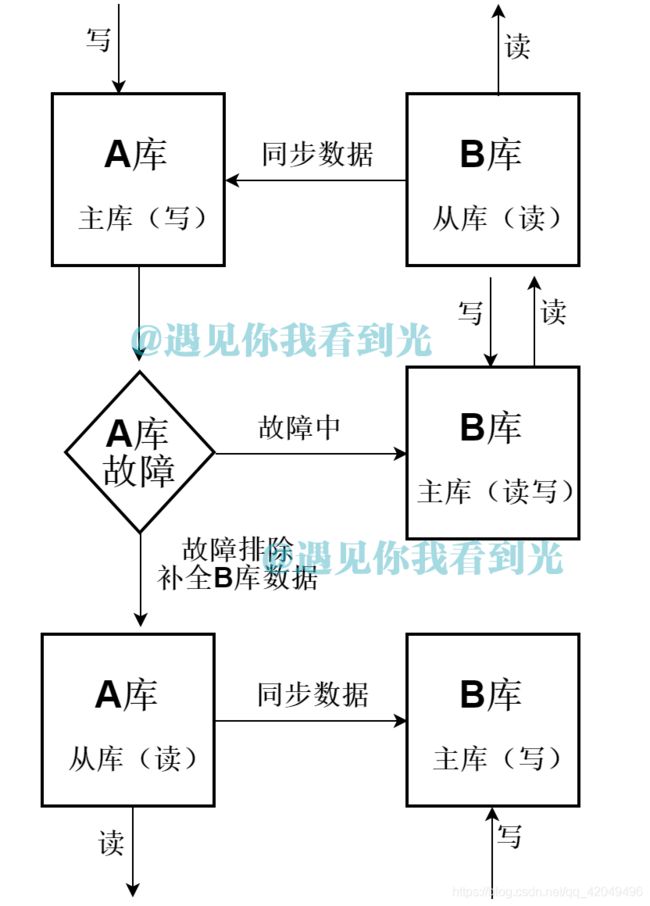
(2)特点
一台机器A作为写库,另一台B作为读库;A库故障后B库充当读写,A修复后,B库为写库,A库为读库。
(3)开发说明
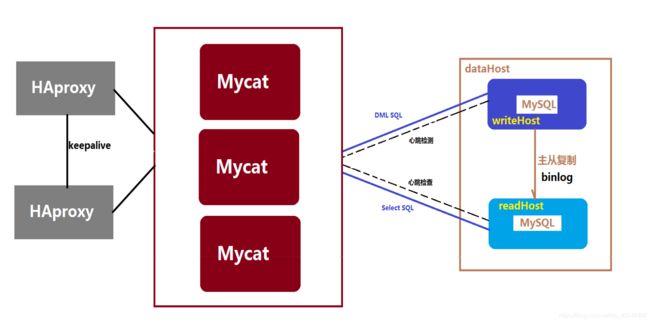
这种方案的实现,要借助数据库中间件Mycat来实现,Mycat的datahost配置如下(注意balance和writetype的设置)
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0"
dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--主,用于写-->
<writeHost host="hostM1" url="192.168.1.135:3306" user="root" password="123" />
<!--主2,用于读,hostM1 down了,自动切换为主,读写都可以-->
<writeHost host="hostM2" url="192.168.1.136:3306" user="root" password="123" />
</dataHost>
(4)适应场景
读和写都不是非常高的场景(单表数据低于1000万),高可用。比方案一并发要高很多。
(5)优缺点
优点是一个机器故障了可以自动切换;读写分离,并发有了很大的提升。
缺点是引入了一个Mycat节点,若要高可用需要引入至少两个Mycat。常规的解决方案是引入haproxy和keepalive对mycat做集群。
高读低写并发、低数据量方案
方案三:一主多从+读写分离
(1)数据库架构图
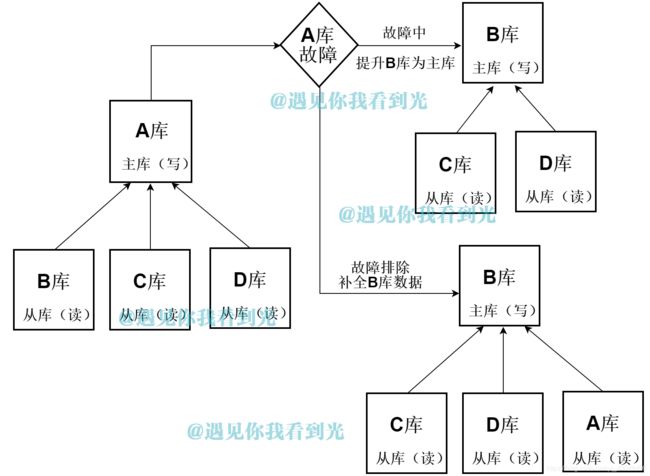
(2)特点
一个主写库A多个从库,当主库A故障时,提升从库B为主写库,同时修改C、D库为B的从库。A故障修复后,作为B的从库。
(3)开发说明
项目开发中需要使用Mycat作为中间件,来配置主库和从库,核心配置如下:
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0"
dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--主A,用于写-->
<writeHost host="hostM1" url="192.168.1.135:3306" user="root" password="123" />
<!—从B,用于读,hostM1 down了,自动切换为主-->
<writeHost host="hostM2" url="192.168.1.136:3306" user="root" password="123456"
/>
<!—从C,用于读-->
<writeHost host="hostM3" url="192.168.1.137:3306" user="root" password="123" />
<!—从D,用于读-->
<writeHost host="hostM4" url="192.168.1.138:3306" user="root" password="123" />
</dataHost>
主库A故障后,Mycat会自动把从B提升为写库;而C、D从库,则可以通过MHA等工具,自动修改其主库为B,实现自动切换。
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
(4)适应场景
该架构适合写并发不大、但是读并发大的很的场景
(5)优缺点
由于配置了多个读节点,读并发的能力有了质的提高;理论上来说,读节点可以多个,可以负载很高级别的读并发。缺点是Mycat依然需要设计高可用方案。
高读写并发、低数据量方案
方案四:MariaDB Galera Cluster方案
(1)数据库架构图

(2)特点
多个数据库,在负载均衡作用下,可同时进行写入和读取操作;各个库之间以Galera Replication的方法进行数据同步,即每个库理论上来说,数据是完全一致的
(3)开发说明
数据库读写时,只需要修改数据库读写IP为keepalive的虚拟节点即可;数据库配置方面相对比较复杂,需要引入haproxy、keepalive、Galaera等各种插件和配置
(4)适用场景
该方案适合读写并发较大、数据量不是非常大的场景
(5)优点缺点
优点:
1)可以在任意节点上进行读
2)自动剔除故障节点
3)自动加入新节点
4)真正并行的复制,基于行级
5)客户端连接跟操作单数据库的体验一致
6) 同步复制,因此具有较高的性能和可靠性
缺点:
1)DELETE操作不支持没有主键的表,没有主键的表在不同的节点顺序将不同
2)处理事务时,会运行一个协调认证程序来保证事务的全局一致性,若该事务长时间运行,就会锁死节点中所有的相关表,导致插入卡住(这种情况和单表插入是一样的)
3)整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件
4)如果DDL语句有问题将破坏集群,建议禁用
5) Mysql数据库5.7.6及之后的版本才支持此种方案
高读写并发、高数据量方案
方案五 数据库中间件
(1)数据库架构图
 (2)特点
(2)特点
采用Mycat进行分片存储,可以解决写负载均衡和数据量过大问题;每个分片配置多个读从库,可以减少单个库的读压力
(3)开发说明
需要配置Haproxy、keepalive和mycat集群,每个分片上又需要配置一主多从的集群,配置和维护量都比较大
(4)适用场景
读写并发都很大并且数据量非常大的场景
(5)优缺点
优点:解决高并发高数据量的问题
缺点:配置和维护都比较麻烦,需要的软硬件设备资源大
MySQL复制技术
MySQL 主从复制概念
MySQL 主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点,MySQL默认采用异步复制方式,从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行
MySQL 主从复制主要用途
- 读写分离
使用主从复制,主库写,从库读,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作 - 数据实时备份
当系统中某个节点发生故障时,可以方便的故障切换 - 高可用HA
- 架构扩展
主从复制增加多个数据存储节点,将负载分布在多个从节点上,降低单机磁盘I/O访问的频率,提高单个机器的I/O性能
重置数据库
service mysqld stop
rm -rf /usr/local/mysql/data/*
#初始化mysql
mysql_secure_installation
#修改uuid
vim /usr/local/mysql/data/auto.cnf
mysql主从复制原理
(1)Slave的I/O线程连接Master,并请求指定日志
(2)Master的binlog dump线程读取并发送bin-log文件(加锁)给Slave的I/O线程
(3)Slave的I/O线程将接收到的日志内容依次写入到relay-log文件,并做标记,以便下次请求时告知Master日志位置
(4)Slave的SQL线程检测到relay-log中新增内容后,将其解析成具体操作并执行,最终保证主从数据的一致性
对于每一个主从复制的连接,都有三个线程
- 拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
- 从库通过创建两个独立的线程,使得在进行复制时,从库的读和写进行了分离,SQL线程不会影响I/O线程读取主库的内容

- 在主库上把数据更改记录到二进制日志(Binary Log)中
- 备库将主库上的日志复制到自己的中继日志(Relay Log)中
- 备库读取中继日志中的事件,将其重放到备库数据库之上
主从复制实现
主/备均为刚初始的数据库
单主到多备: Master-MultiSlave
(1)节点规划
| 主机 | IP | Server_ID |
|---|---|---|
| Master:mysql | 192.168.213.124 | 1 |
| Slave1:mysql-1 | 192.168.213.127 | 2 |
| Slave2:mysql-2 | 192.168.213.128 | 3 |
(2)初始化环境
同步时间
yum -y install ntp ntpdate
ntpdate cn.pool.ntp.org
hwclock --systohc
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
(2)配置主库
修改主库配置文件:开启log-bin功能,并指定server_id为1,这里log-bin必须指定,不然的话bin-log日志会根据主机名来命名,若主库的主机名改变了,那主从复制就失效了
vim /etc/my.cnf
[mysqld]
server_id=1
log-bin=mysql-bin
log-bin-index=master-bin.index
重启服务
[root@localhost ~]# systemctl stop mysqld
[root@localhost ~]# systemctl start mysqld
创建一个用于让从数据库连接的用户(注意Mysql8的授权方式与老版本不同)
mysql> create user 'copy'@'%' identified with mysql_native_password by 'Cloudbu@123';
mysql> grant replication slave on *.* to 'copy'@'%';
mysql> flush privileges; 刷新授权表信息
在从库上测试,用户的客户端能否正常登录
[root@mysql-1 ~]# mysql -h192.168.213.124 -ucopy -pCloudbu@123
获取主节点当前binary log文件名和位置(position)
[root@mysql ~]# mysql -uroot -pCloudbu@123
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 825 | | | |
+------------------+----------+--------------+------------------+-------------------+
(4)配置从库(两从库的配置方法相同,只需要修改配置文件中的server_id)
修改配置文件,必须指定中继日志的名称
[mysqld]
server_id=2
relay-log=relay-log
relay-log-index=relay-log.index
[root@localhost ~]# systemctl stop mysqld
[root@localhost ~]# systemctl start mysqld
在从(Slave)节点上设置主节点参数
[root@mysql-1 ~]# mysql -uroot -pZhao123@com
mysql> CHANGE MASTER TO
MASTER_HOST='192.168.213.124',#主库的IP地址
MASTER_USER='copy', #在主库上创建的复制账号
MASTER_PASSWORD='Cloudbu@123',#在主库上创建的复制账号密码
MASTER_LOG_FILE='mysql-bin.000001',#开始复制的二进制文件名 (从主库查询结果中获
取)
MASTER_LOG_POS=825;#开始复制的二进制文件位置(从主库查询结果中获
取)
开启主从同步 start slave;
查看主从同步状态
mysql> show slave status\G`
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#其中的IO线程和SQL线程均为YES,则配置成功
(5)测试
主库上创建数据库,存库上可以同步到创建的数据库内容,则证明数据同步成功
[root@mysql ~]# mysql -uroot -pZhao123@com
mysql> create database bbs;
Query OK, 1 row affected (0.01 sec)
mysql> create table bbs.t1(id int);
Query OK, 0 rows affected (0.00 sec)
mysql> insert into bbs.t1 value(1);
Query OK, 1 row affected (0.08 sec)
mysql> select * from bbs.t1;
+------+
| id |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
从库上查看主库上创建的数据是否存在
[root@mysql-1 ~]# mysql -uroot -pZhao123@com
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| bbs |
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.01 sec)
mysql> select * from bbs.t1;
+------+
| id |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
#创建内容存在,则数据同步成功
针对已经运行一段时间的主库实现主/备
单主到多备: Master-MultiSlave
(1)节点规划
| 主机 | IP | Server_ID |
|---|---|---|
| Master:mysql | 192.168.213.124 | 1 |
| Slave1:mysql-1 | 192.168.213.127 | 2 |
| Slave2:mysql-2 | 192.168.213.128 | 3 |
(2)初始化环境
同步时间
yum -y install ntp ntpdate
ntpdate cn.pool.ntp.org
hwclock --systohc
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
(3)配置主库
修改主库配置文件:开启log-bin功能,并指定server_id为1,这里log-bin必须指定,不然的话bin-log日志会根据主机名来命名,若主库的主机名改变了,那主从复制就失效了
vim /etc/my.cnf
[mysqld]
server_id=11
log-bin=mysql-bin
log-bin-index=master-bin.index
重启服务
[root@localhost ~]# systemctl stop mysqld
[root@localhost ~]# systemctl start mysqld
创建一个用于让从数据库连接的用户(注意Mysql8的授权方式与老版本不同)
mysql> create user 'copy'@'%' identified with mysql_native_password by
'Cloudbu@123';
mysql> grant replication slave on *.* to 'copy'@'%';
mysql> flush privileges; 刷新授权表信息
(4) 初始化备库(使其和主库数据一致): 逻辑备份,物理备份
备份主库数据,并拷贝到从库上。
注意:在备份数据之前将表锁定,以保证数据一致。
mysql> flush tables with read lock;
#备份除系统自带库的所有数据库
[root@master ~]# mysql -uroot -pZhao123@com -e "show databases;"|tail -n +2|grep -Ev "sys|mysql|information_schema|performance_schema"|xargs mysqldump -uroot -ppassword -B | gzip > all_$(date +%F).sql.tar.gz
[root@master ~]# scp all_2019-07-21.sql.tar.gz 192.168.213.127:/root
[root@master ~]# scp all_2019-07-21.sql.tar.gz 192.168.213.128:/root
[root@master ~]# mysql -e 'show master status'
在从库上解压并导入数据
[root@localhost ~]# gunzip all_2019-11-04.sql.tar.gz
[root@localhost ~]# mysql -uroot -pCloudbu@123
(4)配置从库
修改配置文件,必须指定中继日志的名称
[mysqld]
server_id=22
relay-log=relay-log
relay-log-index=relay-log.index
[root@localhost ~]# systemctl stop mysql
[root@localhost ~]# systemctl start mysql
在从(Slave)节点上设置主节点参数
[root@mysql-1 ~]# mysql -uroot -pZhao123@com
mysql> CHANGE MASTER TO
MASTER_HOST='192.168.213.124',
MASTER_USER='copy',
MASTER_PASSWORD='Cloudbu@123',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=825;
开启主从同步 start slave;
查看主从同步状态
mysql> show slave status\G`
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#其中的IO线程和SQL线程均为YES,则配置成功
(5)测试
#在主库上解表测试
mysql> unlock tables;
mysql> create database mmp;
#在从库上查看创建信息
mysql> show databases;
MySQL主从复制的状况监测
主从状况监测主要参数
Slave_IO_Running: IO线程是否打开 YES/No/NULL
Slave_SQL_Running: SQL线程是否打开 YES/No/NULL
Seconds_Behind_Master: NULL #和主库比同步的延迟的秒数
可能导致主从延时的因素
主从时钟是否一致
网络通信是否存在延迟
从库性能,有没开启binlog
从库查询是否优化
常见状态错误排除
(1)发现IO进程错误,检查日志,排除故障:
[root@mysql ~]# tail /var/log/mysql-error.log
...2015-11-18 10:55:50 3566 [ERROR] Slave I/O: Fatal error: The slave I/O
thread stops because master and slave have equal MySQL server UUIDs; these UUIDs
must be different for replication to work. Error_code: 159
找到原因:从5.6开始复制引入了uuid的概念,各个复制结构中的server_uuid得保证不一样
解决方法:(从库是克隆机器)修改从库的uuid
[root@localhost ~]# find / -name auto.cnf
/var/lib/mysql/auto.cnf
[root@localhost ~]# cd /var/lib/mysql/
[root@localhost ~]# rm auto.cnf
[root@localhost ~]# systemctl stop mysqld
[root@localhost ~]# systemctl start mysqld
(2)show slave status;报错:Error xxx doesn’t exist
解决方法:
mysql> stop slave;
mysql> set global sql_slave_skip_counter = 1; #跳过slave上的1个错误
mysql> start slave;
(3)Relay log 导致复制启动失败
mysql> start slave;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
通过上面的报错可以知道由于mysql.slave_relay_log_info表中保留了以前的复制信息,导致新从库启动时无法找到对应文件
解决方法
mysql> reset slave;
mysql> CHANGE MASTER TO ...
用冷备份恢复实例后,在启动slave前,先进行reset slave清空下以前的旧信息