前端2020年面试题(2)
十一.作用域链
function a(){
var n=0;
function b(){
console.log(n);
}
return b;
}
var fn=a();//fn获得b函数的引用
var n=1;
fn();//fn()相当于执行b(),结果是0
(作用域是在创建定义的时候就确定了的,函数创建在谁的作用域下,谁就是它的父作用域 ,该例子中b函数的父作用域是a函数,a函数的作用域是全局)因此js在寻找的时候,就会沿着这条线寻找下去,哪里找到就哪里停止寻找,直到全局还找不到,就表示不存在。而这条线,便叫做作用域链。
基础:
java的作用域是是以块区分的,也就是{},这个没啥说的。
而JavaScript的作用域,是以方法来区分的。
javascript并没有所谓的块级作用域,javascript的作用域是相对函数而言的,可以称为*函数作用域*
变量的作用域:
全局作用域和局部作用域(函数内部声明变量的时候,一定要使用var命令)
只要函数内定义了一个局部变量,函数在解析的时候都会将这个变量“提前声明”
十二.购物车的实现过程(包括怎么布局,可以用vue、react、jq等)
购物清单:全选、商品、数量、单价、金额、操作
删除所选商品、继续购物、去结算、绑定跟单员
Js实现淘宝购物车类似功能:
主要有添加商品
增加和减少商品数量
根据增加、减少或选择的商品获取金额
实现商品价格的计算

全选按钮:
这里用一个computed(计算属性)就好(如果productList中每一条数据的select都为true,
返回true,否则返回false;)。
详细戳这里
十三.购物车详情页优化(用户商品加入太多导致页面卡顿)(懒加载、分页)
初始第一屏图片>获取滚动条的滚动距离和目录对象离 document 文档顶部的距离>若前者大于后者,滚动时执行加载图片的方法>按需加载图片
window.onload = function () {
var lazyImg = document.getElementsByTagName("img");
var lazyImgLen = lazyImg.length;
var lazyImgArray = [];
var winowBroswerHeight = document.documentElement.clientHeight;
// 初始第一屏图片
loadImg();
// 滚动时执行加载图片的方法
window.onscroll = loadImg;
// 按需加载图片
function loadImg() {
for (var i = 0; i < lazyImgLen; i++) {
var getTD = getTopDistance(lazyImg[i]);
var getST = getScrollTop();
if (!lazyImg[i].loaded && getST < getTD && getTD < (getST + winowBroswerHeight)) {
lazyImg[i].src = lazyImg[i].getAttribute("_src");
lazyImg[i].classList.add("animated", "fadeIn");
lazyImg[i].loaded = true; // 标记为已加载
}
}
}
// 获取目录对象离 document 文档顶部的距离
function getTopDistance(obj) {
var TopDistance = 0;
while (obj) {
TopDistance += obj.offsetTop;
obj = obj.offsetParent;
}
return TopDistance;
}
// 获取滚动条的滚动距离
function getScrollTop() {
return document.documentElement.scrollTop || document.body.scrollTop;
}
}
更多
十四.页面渲染过程
渲染时,大致的流程如下:
(解析html以构建dom树->解析CSS,得到CSSOM树->构建render树->布局render树->绘制render树)
具体的流程如下:
1:浏览器会将HTML解析成一个DOM树,DOM树的构建过程是一个深度遍历过程,
当前节点的所有子节点都构建好后才会去构建当前节点的下一个兄弟节点,
2:将CSS解析成CSS规则树;
3:根据DOM树和CSS来构造render树,渲染树不等于DOM树,像header和display:none;
这种没有具体内容的东西就不在渲染树中;
4:根据render树,浏览器可以计算出网页中有哪些节点,各节点的CSS以及从属关系,
然后可以计算出每个节点在屏幕中的位置;
5:遍历render树进行绘制页面中的各元素。
页面发生重排(回流)的话,会重新加载DOM树,影响页面加载速度。会导致页面重排的原因如下:
1:页面初始化;
2:操作DOM时;
3:某些元素的尺寸变了;
4:CSS的属性发生改变。
为什么script需要放在body的最后位置?
因为其他位置会推迟或者意外的进行预渲染。
具体原因:解析到body中的第一脚本前,浏览器就会认为已经解析得差不多了,可以进行一次预渲染。所以script如果放在head里,会推迟预渲染。如果放在body的一开头,后面的一大堆标签还没解析,等于欺骗浏览器说已经“差不多了”,也就等于违背了设计预渲染的初衷,会影响页面的效果。放在body中间也是一样的道理,所以还是放在最尾巴上比较好。
十五.闭包
函数和对其周围状态的引用捆绑在一起构成闭包。也就是说,闭包可以让你从内部函数访问外部函数作用域。在 JavaScript 中,每当函数被创建,就会在函数生成时生成闭包。
闭包很有用,因为它允许将函数与其所操作的某些数据(环境)关联起来。这显然类似于面向对象编程。因此,通常你使用只有一个方法的对象的地方,都可以使用闭包。
function makeAdder(x) {
return function(y) {
return x + y;
};
}
var add5 = makeAdder(5);
var add10 = makeAdder(10);
console.log(add5(2)); // 7
console.log(add10(2)); // 12
//add5 和 add10 都是闭包。它们共享相同的函数定义,但是保存了不同的词法环境。
在 add5 的环境中,x 为 5。而在 add10 中,x 则为 10。
十六.http协议
http(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式
http请求由三部分组成,分别是:请求行、消息报头、请求正文
HTTP消息报头包括普通报头、请求报头、响应报头、实体报头。
HTTP协议的主要特点可概括如下:
1.支持客户/服务器模式。
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
十七.http中的方法,除了get方法、post方法
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
十八.数据结构(排序算法,冒泡以外的)
数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成 。常用的数据结构有:数组,栈,链表,队列,树,图,堆,散列表(哈希表)
更多
十大经典算法排序总结对比:
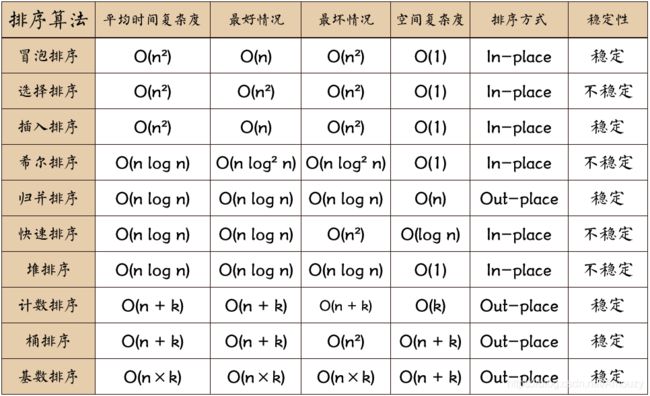
更多
冒泡排序(正序最快,反序最慢):
function bubbleSort(arr) {
var len = arr.length;
for (var i = 0; i < len; i++) {
for (var j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j+1]) { //相邻元素两两对比
var temp = arr[j+1]; //元素交换
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
}
选择排序
时间复杂度上表现最稳定的排序算法之一,因为无论什么数据进去都是O(n²)的时间复杂度
function selectionSort(arr) {
var len = arr.length;
var minIndex, temp;
for (var i = 0; i < len - 1; i++) {
minIndex = i;
for (var j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) { //寻找最小的数
minIndex = j; //将最小数的索引保存
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
插入排序(类似打扑克牌摸牌)
function insertionSort(arr) {
var len = arr.length;
var preIndex, current;
for (var i = 1; i < len; i++) {
preIndex = i - 1;
current = arr[i];
while(preIndex >= 0 && arr[preIndex] > current) {
arr[preIndex+1] = arr[preIndex];
preIndex--;
}
arr[preIndex+1] = current;
}
return arr;
}
希尔排序
希尔排序是插入排序的一种更高效率的实现。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列
function shellSort(arr) {
var len = arr.length,
temp,
gap = 1;
while(gap < len/3) { //动态定义间隔序列
gap =gap*3+1;
}
for (gap; gap > 0; gap = Math.floor(gap/3)) {
for (var i = gap; i < len; i++) {
temp = arr[i];
for (var j = i-gap; j >= 0 && arr[j] > temp; j-=gap) {
arr[j+gap] = arr[j];
}
arr[j+gap] = temp;
}
}
return arr;
}
快速排序(分而治之)
function quickSort(arr, left, right) {
var len = arr.length,
partitionIndex,
left = typeof left != 'number' ? 0 : left,
right = typeof right != 'number' ? len - 1 : right;
if (left < right) {
partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex-1);
quickSort(arr, partitionIndex+1, right);
}
return arr;
}
function partition(arr, left ,right) { //分区操作
var pivot = left, //设定基准值(pivot)
index = pivot + 1;
for (var i = index; i <= right; i++) {
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index-1;
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
十九.vue和react的区别,用法区别
React与Vue存在很多相似之处,例如他们都是JavaScript的UI框架,专注于创造前端的富应用。最大的相似之处是虚拟DOM。Reat与Vue只有框架的骨架,其他的功能如路由、状态管理等是框架分离的组件。
1、监听数据变化的实现原理不同
Vue 通过 getter/setter 以及一些函数的劫持,能精确知道数据变化,不需要特别的优化就能达到很好的性能。
React 默认是通过比较引用的方式进行的,如果不优化(PureComponent/shouldComponentUpdate)可能导致大量不必要的VDOM的重新渲染。
2、数据流的不同
Vue中默认是支持双向绑定的。在Vue1.0中我们可以实现两种双向绑定:
1.父子组件之间,props 可以双向绑定(Vue2.x 中去掉了第一种)
2.组件与DOM之间可以通过 v-model 双向绑定
React 从诞生之初就不支持双向绑定,React一直提倡的是单向数据流,他称之为 onChange/setState()模式。
3、mixins 和 HoC
在 Vue 中我们组合不同功能的方式是通过 mixin,而在React中我们通过 HoC (高阶组件)。
4、组件通信的区别
在Vue 中有三种方式可以实现组件通信:
1.父组件通过 props 向子组件传递数据或者回调,虽然可以传递回调,但是我们一般只传数据,而通过 事件的机制来处理子组件向父组件的通信
2.子组件通过 事件 向父组件发送消息
3.通过 V2.2.0 中新增的 provide/inject 来实现父组件向子组件注入数据,可以跨越多个层级。
在 React 中,也有对应的两种方式:
1.父组件通过 props 可以向子组件传递数据或者回调
2.可以通过 context 进行跨层级的通信,这其实和 provide/inject 起到的作用差不多。
可以看到,React 本身并不支持自定义事件,Vue中子组件向父组件传递消息有两种方式:事件和回调函数,而且Vue更倾向于使用事件。但是在 React 中我们都是使用回调函数的,这可能是他们二者最大的区别。
5、模板渲染方式的不同
在表层上, 模板的语法不同
Vue是通过一种拓展的HTML语法进行渲染。
React 是通过JSX渲染模板(表面现象,毕竟React并不必须依赖JSX。);
在深层上,模板的原理不同,这才是他们的本质区别:
Vue是在和组件JS代码分离的单独的模板中,通过指令来实现的,
比如条件语句就需要 v-if 来实现。
React是在组件JS代码中,通过原生JS实现模板中的常见语法,
比如插值,条件,循环等,都是通过JS语法实现的;
React的好处:
react中render函数是支持闭包特性的,所以我们import的组件在render中可以直接调用。但是在Vue中,由于模板中使用的数据都必须挂在 this 上进行一次中转,所以我们import 一个组件完了之后,还需要在 components 中再声明下,这样显然是很奇怪但又不得不这样的做法。
6、Vuex 和 Redux 的区别
从表面上来说,store 注入和使用方式有一些区别。
在 Vuex 中,$store 被直接注入到了组件实例中,因此可以比较灵活的使用:
使用 dispatch 和 commit 提交更新;
通过 mapState 或者直接通过 this.$store 来读取数据。
在 Redux 中,我们每一个组件都需要显示的用 connect 把需要的 props 和 dispatch 连接起来。另外 Vuex 更加灵活一些,组件中既可以 dispatch action 也可以 commit updates,而 Redux 中只能进行 dispatch,并不能直接调用 reducer 进行修改。
从实现原理上来说,最大的区别是两点:
1.Redux 使用的是不可变数据,而Vuex的数据是可变的。Redux每次都是用新的state替换旧的state,而Vuex是直接修改
2.Vuex其实和Vue的原理一样,是通过 getter/setter来比较的(如果看Vuex源码会知道,其实他内部直接创建一个Vue实例用来跟踪数据变化)Redux 在检测数据变化的时候,是通过 diff 的方式比较差异的,而
相比之下,Vue更偏向于简单迅速的解决问题,更灵活,不那么严格遵循条条框框。因此也会给人一种大型项目用React,小型项目用 Vue 的感觉。
更多
二十.网页上哪里可以看到请求的所有信息
审查元素>network