HBase数据库 及 HappyBase库
HBase数据库 及 HappyBase库
- HBase概念
- HBase 数据模型
- HBase 原理
-
- HMaster 服务器
- RegionServer
- 表储存
- 读数据流程
- REST Server
- HBase Shell
-
- scan 限制查询
- happybase
-
- Connection 连接HBase
-
- tables() 返回此HBase实例中表名列表
- create_table 新建表
- delete_table 删除表
- 禁用和解禁表
- table 创建表对象
-
- families 检索表列族
- regions 检索表区域
- row 检索指定单行数据 rows 检索指定多行数据
- cells 检索指定单元格的多版本数据
- scan
- put 存储记录
- delete 删除记录
- 计数列
- batch 为表创建批处理操作
- 连接池
-
- connection 从池中获取连接
HBase概念
HBase是一个分布式的、面向列的开源数据库HBase是Google BigTable的开源实现HBase不同于一般的关系数据库, 适合非结构化数据存储- 是用来处理海量数据(
PB级)快速实时读写的一种非关系型的数据库 - 并发数据处理,效率极高;易于扩展,支持动态伸缩
HBase整合了Hadoop的水平扩展能力和实时数据服务两方面的优势
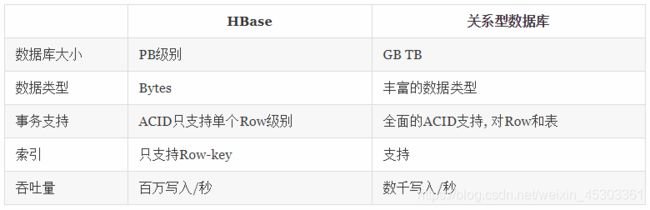
注意:HBase没有复杂的数据类型,仅有字节型数据 Bytes 一种,因此在读写数据时注意只用encode 和 decode
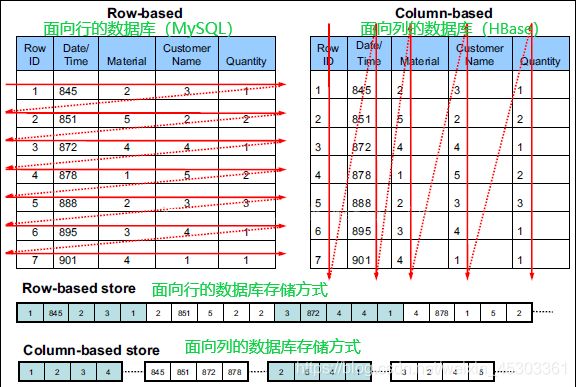
HBase 数据模型
NameSpace: 关系型数据库的"数据库"(database)- 表(
table):用于存储管理数据,具有稀疏的、面向列的特点。HBase中的每一张表,就是所谓的大表(Bigtable),可以有上亿行,上百万列。对于为值为空的列,并不占用存储空间,因此表可以设计的非常稀疏 - 区域(
Region):当HBase表太大时,可将表水平划分成的多个区域,划分的区域随着数据的增大而增多-
行(
Row):在表里面,每一行代表着一个数据对象,每一行都是以一个行键(Row Key)来进行唯一标识的, 行键并没有什么特定的数据类型, 以二进制的字节来存储- 行键(
RowKey):类似于MySQL中的主键,HBase根据行键来快速检索数据,一个行键对应一条记录。与MySQL主键不同的是,HBase的行键是天然固有(创建表示不用指定RowKey列,但填入数据是必须在列数据前写入RowKey)的,每一行数据都存在行键
- 行键(
-
列(
Column):HBase的列由CF:CQ组成- 列族(
ColumnFamily简CF):是列的集合。列族在表定义时需要指定,而列在插入数据时动态指定。列中的数据都是以二进制形式存在,没有数据类型。在物理存储结构上,每个表中的每个列族单独以一个文件存储。一个表可以有多个列簇。 - 列修饰符(
Column Qualifier简CQ) : 列族中的数据通过列标识来进行映射, 可以理解为一个键值对(key-value), 列修饰符(CQ) 就是key对应关系型数据库的列 - 时间戳(
TimeStamp):是列的一个属性,是一个64位整数。由行键和列确定的单元格,可以存储多个数据,每个数据含有时间戳属性,数据具有版本特性。可根据版本(VERSIONS)或时间戳来指定查询历史版本数据,如果都不指定,则默认返回最新版本的数据
- 列族(
-

HBase表由RowKey和一个或者多个列族( CF )组成,一个列族又可包含很多列(包含列修饰符CQ和列值)
在HBase中,常用:行、列、键、单元格、值、行键、时间戳等术语描述
- 行由很多列组成,全部由相同的行键引用
- 列由列族和列修饰符组成,一个列族可以包含很多列
- 单元格:一个列和行键确认一个单元格
- 一个单元格可以有很多版本,由不同时间戳的版本来区分
HBase 原理
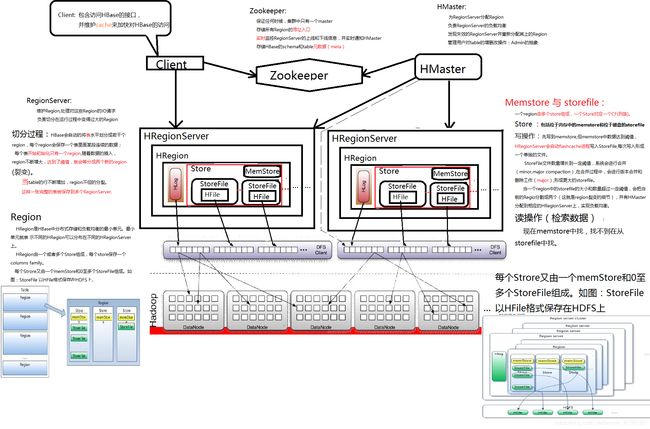
HMaster 服务器
HBase的Master服务器是集群的大脑,负责下面这些操作:
Region分配- 负载均衡
Regionserver恢复Region分裂完成监控- 追踪处于活动和岩机状态的服务器
为了达到高可用性,单个集群可以有多master。但是只能有一个master处于活动状态,负责上面的操作
HBase Master不会有很大的负载压力,可以安装在内存和处理器核数比较小的服务器上,但是必须稳定可靠,不宕机
RegionServer
RegionServer (RS )是 托管并服务HBase region 以及HBase数据的应用程序。
- 维护
region并 处理region的读写请求 - 决定井处理
region的分裂和合井,同时将信息报告给Maste
尽管 一个物理机上运行多个RegionServer在技术上是可行的,我们仍然建议在一个物理节点上运行一个RegionServer,并为其提供在两个服务器之间共享的资源。
表储存
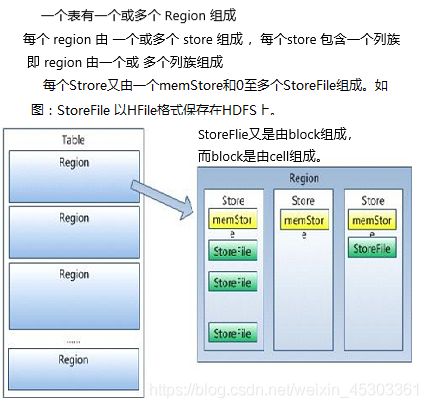
读数据流程
当客户端第一次尝试从HBase卖取数据的时候,首先,它会连接zookeeper寻找master服务器,并在HBase: meta定位出region 的信息(它要查找的region 的位置信息以及RegionServer信息)。若后面同样的客户端请求同样的region ,所有这些连接zookeeper的过程都会被跳过,客户端直接跳到相关的RegionServer上获得数据。这就是为什么在可能的情况下,使用同一台机器执行多次操作的一个重要原因
REST Server
HBase 提供了REST Server API,通过该API客户端以及管理性操作能够被
执行。 Rest API能够通过HTTP请求直接被客户端应用或者命令行应用(如curl)调用。通过指定HTTP头文件中的Accept字段,你可以让REST server来返回不同格式
的结果。下面是相关格式:
text/plain (consult the warning note at the end of this chapter for more information)text/xmlapplication/octet-streamapplication/x-protobufapplication/protobufapplication/json
让我们看 个非常简单的创建表和填充表的示例
create 't1', 'f1'
put 't1','r1','f1:c1','va1'
下面是 个例子,通过HBase REST API调用的方式,从XML的内容检索出我们已插入的单元格数据。
curl -H "Accept: text/xml"http://localhost:8080/t1/r1/f1:c1
返回值如下:
| dmFsMQ== |
base64编码的值可以通过下面的命令解码:
$ echo "dmFsMQ==” I base64 -d
val1
如果不想解码XML和 based64值,你可以使用octet-stream格式:
curl -H "Accept: application/octet-stream" http://localhost 8080/t1/r1/f1:c1
将直接会返回:
val1
HBase Shell
| 名称 | 命令表达式 |
|---|---|
| 创建名称空间 | create_namespace '命名空间名(数据库名)' |
| 显示现有的所有名称空间 | list_namespace |
| 创建表 | create 'namespace名:表名', '列族名1','列族名2','列族名n' 不指定namespace名则会将表创建到default 命名空间中 |
| 查看表的详细信息 | describe '表名' |
| 显示指定名称空间下的表 | list_namespace_tables '指定命名空间' 不指定命名空间,则显示所有命名空间中的表 |
| 删除表 | 第一步:禁用表disable '表名' ;第二步:删除禁用表 drop '表名' |
| 添加/重写 记录 | put '表名','rowkey值','列族:列标识符','值' 若 rowkey值、列名 均已存在,则表示追加覆盖原有数据,注意原数据仍存在,可通过显示多版本获取 |
| 删除记录的部分列 | delete '表名', 'rowkey值','列名(列族:列标识符)' |
| 删除整条记录 | deleteall '表名' |
| 清空数据 | truncate '表名' |
| 查看记录 | get '表名','rowkey值' |
| 查看表中的记录总数 | count '表名' |
| 查看所有记录 | scan "表名" 添加限制条件 |
| 查看指定表指定列所有数据 | scan '表名' ,{COLUMNS=>'列族名:列修饰符'} |
| 添加列族 | alter '表名', NAME=>'新列族名' |
| 修改列族可显示的版本数 | alter '表名', NAME=>'列族',VERSIONS=> 版本数 |
查看HBase可用工具 |
tools |
查看HBase集群状态 |
states |
查看HBase版本 |
version |
注意:
- 没有
;结尾 - 所有的
namespace名、table名、列族、列族:列标识符等都必须使用引号 '引起来
scan 限制查询
通过COLUMNS 、 LIMIT、 STARTROW 等条件缩小查询范围
COLUMNS查询指定列,可指定多个LIMIT限制输出的行数(相同的rowkey是一行数据)STARTROW限制起始的Rowkey值VERSIONS最多可以显示的版本数TIMERANGE指定时间戳范围内 版本的数据
scan '名称空间:表名', {COLUMNS => ['列族名1', '列族名2'], LIMIT => 10, STARTROW => '起始的rowkey'}
scan 'user',{COLUMNS => 'base_info', TIMERANGE => [起始时间点, 结束时间点]}
添加前缀过滤器
scan '名称空间:表名', {ROWPREFIXFILTER=>'rowkey值的前缀'}
添加时间戳过滤器
scan '名称空间:表名',{FILTER => 'TimestampsFilter (时间戳1, 时间戳2)'}
注意:包含时间戳1 不包含时间戳2
# 获取最近多个版本的数据
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>10}
返回结果如下
COLUMN CELL
base_info:username timestamp=1558323918953, value=Tom4
base_info:username timestamp=1558323904133, value=Tom3
base_info:username timestamp=1558323758696, value=Tom2
base_info:username timestamp=1558323139575, value=Tom
# 通过指定时间戳获取不同版本的数据
get 'user','rowkey_10',{COLUMN=>'base_info:username',TIMESTAMP=>1558323904133}
返回结果如下
COLUMN CELL
base_info:username timestamp=1558323904133, value=Tom3
get 'user','rowkey_10',{COLUMN=>'base_info:username',TIMESTAMP=>1558323918953}
返回结果如下
COLUMN CELL
base_info:username timestamp=1558323918953, value=Tom4
happybase
HBase的python库, 其基于Python Thrift
- 启动
HBase thrift server:hbase-daemon.sh start thrift - 安装
happy base
建议安装HappyBase和Thrift的方法是使用virtualenv创建的虚拟环境设置并激活一个新的虚拟环境,如下所示:
使用$ virtualenv 虚拟环境名 $ source 虚拟环境名/bin/activatevirtualenvwrapper脚本,请键入以下内容:
安装$ mkvirtualenv 虚拟环境名 # 若以存在虚拟环境,则可直接使用已有的虚拟环境HappyBase软件包
验证软件包是否正确安装:(虚拟环境名) $ pip install happybase
如果没有看到任何错误,则表明安装成功(envname) $ python -c 'import happybase' - 建立连接
import happybase # 导包 connection = happybase.Connection('somehost') - 执行
hbase操作 - 关闭连接
connection.close()
Connection 连接HBase
类
hbasa对象名 = happybase.Connection(host ='localhost',port = 9090,timeout = None,autoconnect = True,table_prefix = None,
table_prefix_separator = b'_',compat ='0.98',transport ='buffered',protocol ='binary' )
host(str):要连接的HBase Thrift主机,默认为本机port(int):要连接的端口timeout(int):套接字超时(以毫秒为单位)(可选)autoconnect (bool):是否应直接连接HBase,若为false则需要手动开启Connection.open()table_prefix(str):用于构造表名的前缀(可选)table_prefix_separator(str):用于连接table_prefix前缀和表名的分隔符compat(str):兼容模式(可选)transport(str):指定要使用的Thrift传输模式(可选)protocol(str):指定要使用的Thrift传输协议(可选)
tables() 返回此HBase实例中表名列表
格式:hbasa对象名.tables()
如果为此设置了table_prefixConnection,则仅列出具有指定前缀的表。
返回值: 表名(字符串清单)
create_table 新建表
格式:hbasa对象名.create_table('表名',{'列族名': dict()})
families = {
'cf1': dict(max_versions=10),
'cf2': dict(max_versions=1, block_cache_enabled=False),
'cf3': dict(), # use defaults
}
connection.create_table('mytable', families)
delete_table 删除表
格式: hbase对象名.delete_table('表名',disable = False )
在HBase中,始终需要先禁用表才能将其删除。如果disable参数为True,则此方法首先禁用该表(如果尚未创建),然后将其删除。
禁用和解禁表
禁用表 格式:hbase对象名.disable_table('表名')
解禁表 格式:hbase对象名.enable_table('表名')
查看指定表是否启用:hbase对象名.is_table_enabled('表名')
table 创建表对象
格式:table对象名 = hbase对象名.table('表名',use_prefix = True )
返回指定表的实例对象。这不会导致服务器往返,并且不会检查该表是否存在。
参数:
use_prefix(bool):是否使用表前缀(如果有)
返回值: 表实例( Table )
families 检索表列族
格式:table对象名.families()
返回值: 以列族名为键;设置为值的 映射字典
regions 检索表区域
格式:table对象名.regions()
返回值: 字典列表
row 检索指定单行数据 rows 检索指定多行数据
table对象名.row('rowkey值1',column = None,timestamp = None,include_timestamp = False )
table对象名.rows(['rowkey值1','rowkey值2',...],column = None,timestamp = None,include_timestamp = False )
根据指定的rowkey值或rowkey值列表来检索指定行,并将该行的列和值作为字典返回
参数:
columns (list_or_tuple):检索指定列 列表(可选) ,若不指定则返回所有列的数据 格式:['列族1:列分隔符1','列族1:列分隔符2','列族2:列分隔符3',....]timestamp (int):时间戳(可选)用于选择版本,默认最新版本include_timestamp(bool):是否返回时间戳
返回值: 包含列名为键(列族:列分隔符)和值的字典
cells 检索指定单元格的多版本数据
table对象名.cells('rowkey值',column,versions= None,timestamp = None,include_timestamp = False )
参数:
columns (str):检索指定列名 ,格式:'列族:列分隔符'versions(int):要检索的最大版本数timestamp (int):时间戳(可选)用于选择版本,默认最新版本include_timestamp(bool):是否返回时间戳
返回值: 单元格值组成的列表
scan
table对象名.scan(row_start=None, row_stop=None, row_prefix=None, columns=None, filter=None, timestamp=None, include_timestamp=False,
batch_size=1000, scan_batching=None, limit=None, sorted_columns=False, reverse=False)
为表中的数据创建一个扫描仪,返回一个可迭代的对象,可用于循环匹配的行
参数:
row_start(str):检索开始的行键值(包括端点)忽略表示从表开始检索row_stop(str):停止检索的行键值(不包括端点),若row_start和row_stop都省略,则进行全表扫描。请注意,这通常会导致严重的性能问题row_prefix(str):检索匹配指定行键前缀的行键,注意:如果给定,则不能使用row_start和row_stopcolumns(list_or_tuple):检索的列(列族:列分隔符)数据 列表(可选),若不指定则显示所有列filter(str):过滤字符串(可选)HBase 0.92以上可用timestamp(int):时间戳(可选),主要用来选择版本。若不指定表示最新include_timestamp(bool):是否返回时间戳batch_size(int):用于检索结果的批处理大小,较低的批处理大小会导致服务器往返次数增加scan_batching(bool):服务器端扫描批处理(可选)limit(int):要返回的最大行数(同一rowkey值为一行)sorted_columns(bool):是否返回列的检索顺序HBase 0.96以上可用reverse(布尔):是否进行反向扫描;注意:row_start必须按字典顺序在row_stop之后HBase 0.98以上可用
返回值: 生成器产生与扫描匹配的行
返回类型: (row_key,row_data)元组的可迭代
put 存储记录
table对象名.put('rowkey值',data,timestamp = None,wal = True )
参数:
data(字典):要存储的数据,该数据参数是列名和列值的字典映射。列名必须包含Family和qualifier部分,并且qualifier可为空字符串。例如:b'cf:col'或b'cf:'timestamp(int):时间戳(可选)wal(bool):是否写入WAL(可选)
delete 删除记录
table对象名.delete('rowkey值',column = None,timestamp = None,wal = True )
删除由rowkey值指定的行中的由column 列表指定的所有列
参数:
column(list_or_tuple):列名(列族:列分隔符)列表(可选),若不指定则删除所整行数据timestamp(int):时间戳(可选)wal(bool):是否写入WAL(可选)
计数列
- 增加计数列并设置值
格式:table对象名.counter_set('指定rowkey值','计数列名', value=计数值)计数值默认为0 - 获取当前计数列的值
格式:table对象名.counter_get('指定rowkey值','计数列名')
请注意,应用程序代码永远不要直接存储递增或递减的计数列值。而是使用 table对象名.counter_inc()和table对象名.counter_dec()方法。
- 指定步长递增计数行的值
格式:table对象名.counter_inc('指定rowkey值','计数列名',, value=步长)
值为正(递增);值为负(递减)
如果计数器列不存在,则在将其递增之前会自动初始化为0 - 指定步长减少计数器值
格式:table对象名.counter_dec('指定rowkey值','计数列名',, value=1)
值为正(递减);值为负(递增)
batch 为表创建批处理操作
batch对象名 = table对象名.batch(timestamp = None,batch_size = None,transaction = False,wal = True )
此方法返回Batch可用于海量数据操作的新实例
参数:
batch_size(int):批处理大小(可选),该批处理会将变化发送到服务器。默认无界transaction(bool):该批处理是否应像事务一样(仅当用作上下文管理器时有用)注意:不能与batch_size组合使用timestamp(int):时间戳(可选)wal(bool):是否写入WAL(可选)
该参数确定突变是否应写入HBase的写日志(WAL)。该标志只能与最新的HBase版本一起使用
如果指定,它将为该批次上的所有put和删除操作提供默认设置
通常不应该使用; 它的唯一用途是覆盖wal参数Batch.put()和Batch.delete()
的值
返回值: 批处理实例
返回类型: Batch
可用方法:
batch对象名.send():将批次发送到服务器batch对象名.put('rowkey值',data,wal = None ): 将数据存储在表中batch对象名.delete('rowkey值',column = None,wal = None ): 从表中删除数据
连接池
happybase.ConnectionPool(size,** kwargs )
线程安全的连接池
pool对象名 = happybase.Connection除autoconnect参数外,其他关键字参数未经修改地传递给 构造函数,因为维护连接是池的任务。
参数:
size(int):该连接池同时打开的最大连接数kwargs:传递给的关键字参数happybase.Connection
connection 从池中获取连接
格式:pool对象名.connection(timeout=等待秒数) timeout默认为None,表示永远等待链接
此方法必须用作上下文管理器,即与Python的with块一起使用。即:
with pool.connection() as connection:
pass
如果指定了超时,则这是在NoConnectionsAvailable引发连接之前等待连接可用的秒数 。如果省略,此方法将永远等待连接可用。
返回值: 池中的活动连接
返回类型: happybase.Connection