Mysql数据库:sql语句、索引、事务、视图操作命令
文章目录
-
- 一、数据库系统发展史
-
-
- 当今主流数据库介绍
- 数据库的基本概念
-
- 二、数据库存储类型:
-
-
- 1,关系型数据库
-
-
- 关系型数据库应用举例:
- 非关系数据库产品:
-
- 2,非关系型数据库
-
- 三、数据库的基本操作命令:
-
- SQL语句概述
-
- SQL分类 :
-
- 1:DDL操作命令(数据定义语言)
- 2:DML操作命令(数据操纵语言)
- 3:DQL操作命令(数据查询语言)
- 4:DCL操作命令(数据控制语言)
- 四、索引的概念
-
-
- 索引的作用
- 索引的分类
- 创建索引的原则依据
- 创建索引的方法
-
- 五、事务的概念
-
-
- 事务的ACID特点
- 事务的操作
-
-
- ■事务处理命令控制事务
- ■使用set命令进行控制
-
-
- 六、视图的概念:
-
-
-
- 1,基于单表,创建视图:
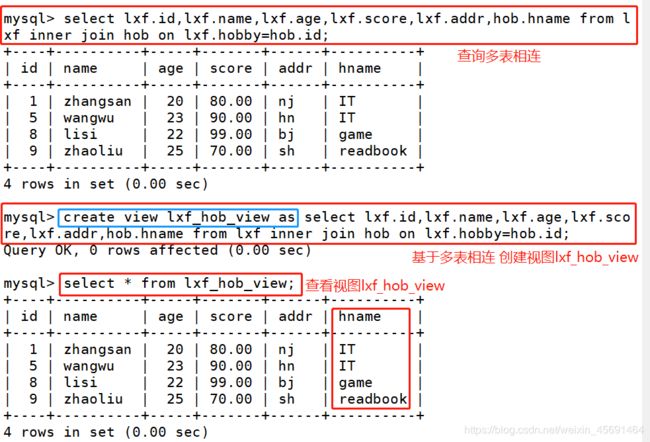
- 2,基于多表相连,创建视图:
-
-
一、数据库系统发展史
■第一代数据库
自20世纪60年代起,第一代数据库系统问世。它们是层次模型与网状模型的数据库系统,为统一管理和共享数据提供了有力的支撑
■第二代数据库
20世纪70年代初,第二代数据库–关系数据库开始出现
20世纪80年代初,IBM公司的关系数据库系统DB2问世,作为第二代数据库系统的关系数据库,开始逐步取代层次与网状模型的数据库,成为占主导地位的数据库,成为行业主流。到目前为止,关系数据库系统仍占领数据库应用的主要地位
■第三代数据库
自20世纪80年代开始,各种适应不同领域的新型数据库系统不断涌现,如工程数据库、多媒体数据库、图形数据库、智能数据库、分布式数据库及面向对象数据库等,特别是面向对象数据库系统,由于其实用性强、适应面广而受到人们的青睐
20世纪90年代后期,形成了多种数据库系统共同支撑应用的局面。当然,在商务应用方面,依然还是关系数据库占主流,不过已经有一些新的元素被添加进主流商务数据库系统中。例如,Oracle支持的"关系–对象”数据库模型
当今主流数据库介绍
■SQL Server (微软公司产品):面向Windows操作系统,简单、易用
■Oracle (甲骨文公司产品):面向所有主流平台,安全、完善,操作复杂
■DB2 (IBM公司产品):面向所有主流平台,大型、安全、完善
■ MYSQL (甲骨文公司收购):免费、开源、体积小
数据库的基本概念
■数据:描述事物的符号记录称为数据(Data),包括数字、文字、图形、图像、声音、档案记录等,以“记录”形式按统一的格式进行存储。
■表:将不同的记录组织在一起,就形成了“表”,是用来存储具体数据的。
■数据库:数据库就是表的集合,以一定的组织方式存储的相互有关的数据,是存储数据的仓库。
二、数据库存储类型:
1,关系型数据库
关系型数据库有:MYSQL、 access、Oracle、 DB2、Sybase、SQLServer等
关系数据库存储的是数值,字符,布尔值等,它的存储结构是二维表格,反映事物及其联系的数据是以表格形式保存的,在每个二维表中,每一行称为一条记录,用来描述一个对象的信息; 每一列称为一个字段,用来描述对象的一个属性。
■实体
也称为实例,对应现实世界中可区别于其他对象的"事件”或“事物”,如银行客户、银行账户等
■属性
实体所具有的某一 特性,一个实体可以有多个属性。例如,"银行客户” 实体集中的每个实体均具有姓名、住址、电话等属性
■联系
实体集之间的对应关系称为联系,也称为关系。例如,银行客户和银行账户之间存在“储蓄”的关系
所有实体及实体之间联系的集合构成一个关系数据库。关系数据库的存储结构是二维表格,反映事物及其联系的数据是以表格形式保存的,在每个二维表中,每一行称为一条记录,用来描述一个对象的信息; 每一列称为一个字段,用来描述对象的一个属性。
关系型数据库应用举例:
●12306用户信息系统
●淘宝账号信息系统、支付宝账号系统移动、电信、联通手机号信息系统、计费系统银行用户账号系统
●网站用户信息系统
非关系数据库产品:
MySQL数据库是一款深受欢迎的开源关系型数据库,遵守了GPL协议,可以免费使用与修改。
性能卓越、服务稳定,开源、无版权限制、成本低,多线程、多用户,基于C/S (客户端/服务器)架构,安全可靠。
■设置数据库用户的密码
●mysqladmin -u root [-p] password 新密码
[root@ce ~]# mysqladmin -u root -p password
Enter password: (输入之前的空密码)
[root@ce ~]# mysql -uroot -p123
■使用mysql工具登录数据库
[root@Mysql1 ~]# /usr/local/mysql/bin/mysqld_safe --user=mysqI & 启动数据库,后台运行
[root@ce ~]# mysql -u root -p
2,非关系型数据库
非关系型数据库有: MongoDB、redis、memcached(内存数据库也称缓存数据库K-V 键值对(key-value)变量名–值)
■非关系数据库
也被称作NoSQL(Not Only SQL), 存储的是图片、视频、语音等 ,存储数据不以关系模型为依据,不需要固定的表格式,非关系型数据库作为关系数据库的一个补充,在日益快速发展的网站时代,发挥着高效率与高性能。
■非关系型数据库的优点:
数据库高并发读写的需求、对海量数据高效率存储与访问、数据库的高扩展性与高可用性的需求
■非关系型数据库存储方式:
键-值方式(key-value),以键为依据存储、删、改数据
列存储(Column-oriented), 将相关的数据存储在列族中
文档的方式,数据库由一系列数据项组成,每个数据项都有名称与对应的值
图形方式,实体为顶点,关系为边,数据保存为一个图形
■非关系数据库产品:
(1)Memcached是一个开源的、高性能的、具有分布式内存对象的缓存系统,以key-value方式存储数据
●缓存数据以减轻数据库压力并能加快访问速度
●加速动态Web应用
●缓存的内容保存在内存中,不可以对对象进行存储
缺点:数据容易丢失
(2)redis也是一个以key-value方式存储数据的, 数据也是保存在内存中,但会定期将数据写入磁盘中。
相对于Memcached有以下特点
●支持内存缓存
●支持持久化
●数据类型更多
●支持集群、分布式
●支持队列
三、数据库的基本操作命令:
1, 设置数据库用户的密码:
#mysqladmin -u root [-p] password 新密码
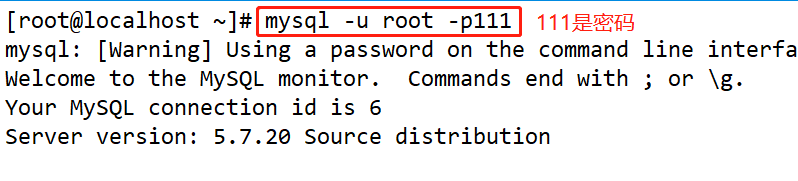
2,登录数据库
#mysql -u root -p111
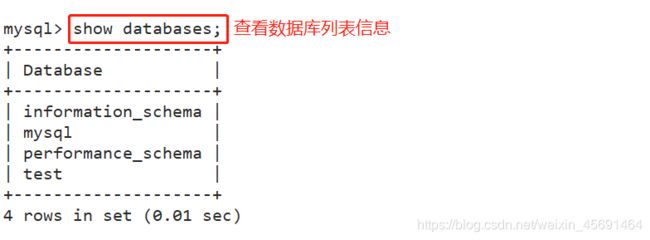
3, 查看数据库列表信息:
mysql> show databases;
4, 查看数据库中的数据表信息:
mysql> use [数据库名] 进入数据库
mysql> show tables; 查看数据表信息

5,显示数据表的结构(字段):
mysql> describe [数据库名.]表名


SQL语句概述
■SQL语言是Structured Query Language的缩写,即结构化查询语言,是关系型数据库的标准语言,用于维护管理数据库,如数据查询、数据更新、访问控制、对象管理等功能。
SQL分类 :
1:DDL操作命令(数据定义语言)
■DDL语句用于创建数据库对象,如库、表、索引等
创建数据库: create database 数据库名
创建数据表: create table 表名(字段定义…)


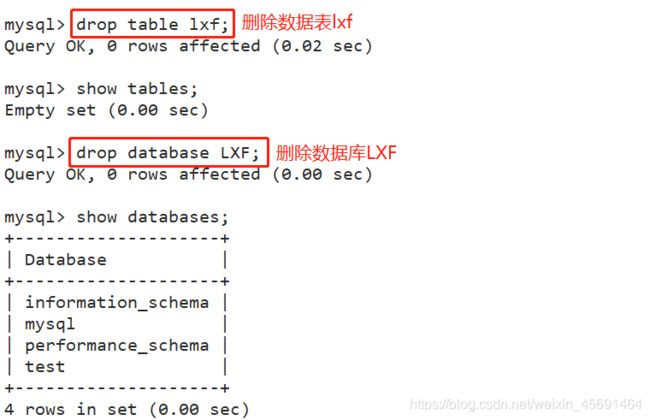
■使用DDL语句删除库、表
删除指定的数据表: drop table [数据库名.]表名
删除指定的数据库: drop database 数据库名
2:DML操作命令(数据操纵语言)
DML语句用于对表中的数据进行管理,包括以下操作:
insert:插入新数据
update:更新原有数据
delete:删除不需要的数据
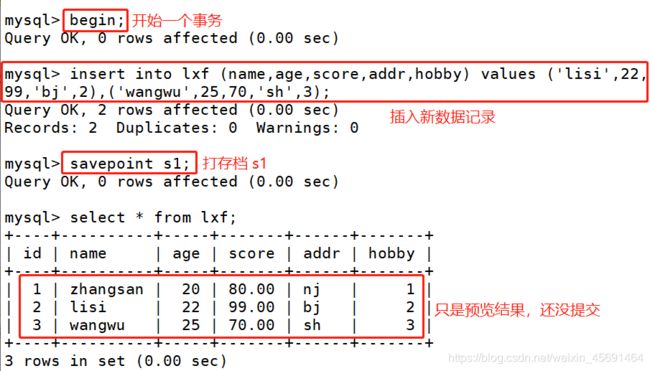
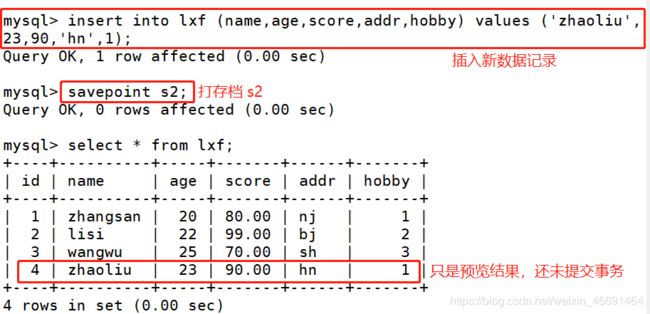
■向数据表中插入新的数据记录
insert into 表名(字段1,字段2, …) values (字段1的值,字段2的值, …)


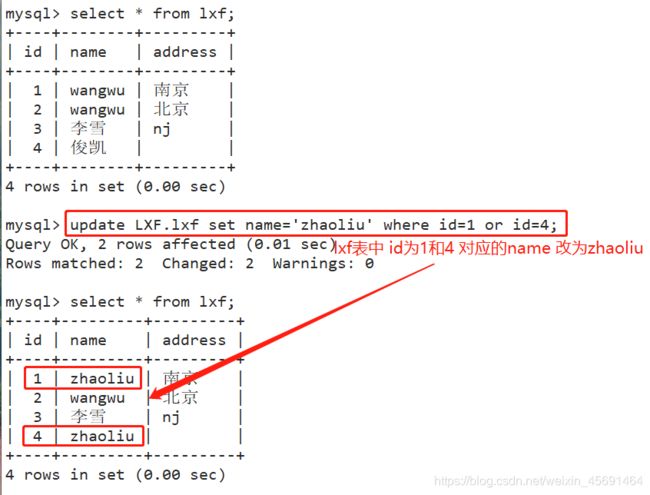
■修改、更新数据表中的数据记录
update 表名 set 字段名1=值1[,字段名2=值2] where条件表达式

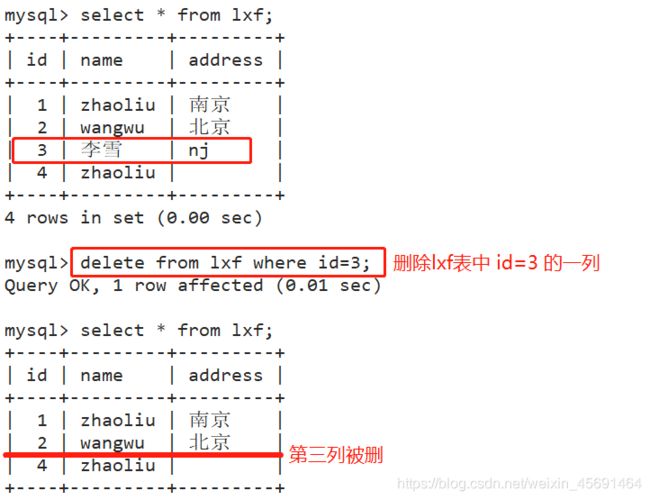
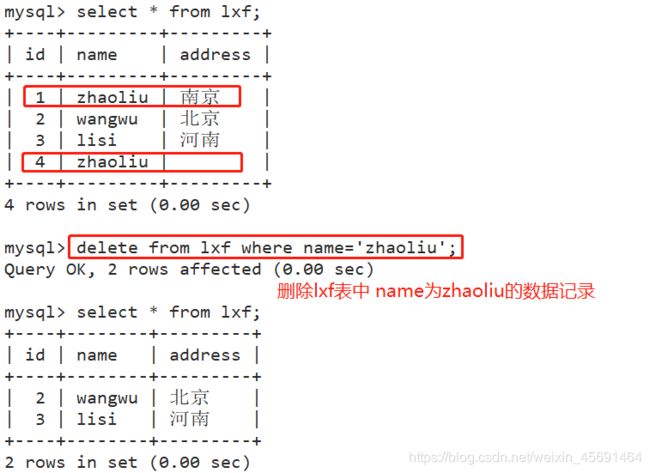
■在数据表中删除指定的数据记录
delete from 表名 where条件表达式
3:DQL操作命令(数据查询语言)
DQL是数据查询语句,只有一条: select 。用于从数据表中查找符合条件的数据记录
■查询时可不指定条件,查看全部
select 字段名1,字段名2 … from 表名

■查询时指定条件
select 字段名1,字段名2 … from 表名 where 条件表达式
4:DCL操作命令(数据控制语言)
■设置用户权限(用户不存在时,则新建用户)
grant 权限列表 on 数据库名.表名 to 用户名@来源地址 [ identified by ‘密码’ ]
% 代表任意终端,如果用户已存在,则更改用户密码;如果用户不存在,就新建用户密码
■查看用户的权限
show grants for 用户名@来源地址
■撤销用户的权限
revoke 权限列表 on 数据库名.表名 from 用户名@来源地址
■授权其他主机可以远程登录:
mysql> grant all privileges on * . * to root ’ @’% ’ identified by 'abc123 ’ with grant option ;

四、索引的概念
■在数据库中,索引使数据库程序无须对整个表进行扫描,就可以在其中找到所需数据,数据库中的索引是某个表中一列或者若干列值的集合,以及物理标识这些值的数据页的逻辑指针清单。
索引的作用
■设置了合适的索引之后,数据库利用各种快速的定位技术,能够大大加快查询速率,特别是当表很大时,或者查询涉及到多个表时,使用索引可使查询加快成千倍
■可以降低数据库的I0成本,并且索引还可以降低数据库的排序成本
■通过创建唯一性索引保证数据表数据的唯一性
■可以加快表与表之间的连接
■在使用分组和排序时,可大大减少分组和排序时间
索引的分类
■普通索引:这是最基本的索引类型,而且它没有唯一性之类的限制
■唯一性索引:这种索引和前面的 “普通索引” 相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一
■主键索引:主键是一种唯一性索引,但它必须指定为“PRIMARY KEY"
■全文索引:MySQL从3.23.23版开始支持全文索引和全文检索。在MySQL中,全文索引的索引类型为FULLTEXT,全文索引可以在VARCHAR或者TEXT类型的列上创建
■单列索引与多列索引:索引可以是单列上创建的索引,也可以是在多列上创建的索引
创建索引的原则依据
■表的主键、外键必须有索引
■数据量超过300行的表应该有索引
■经常与其他表进行连接的表,在连接字段_上应该建立索引
■唯一性太差的字段不适合建立索引
■更新太频繁地字段不适合创建索引
■经常出现在Where子句中的字段,特别是大表的字段,应该建立索引
■索引应该建在选择性高的字段上
■索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引
创建索引的方法
■根据企业需求选择了合适的索引之后,可使用CREATEINDEX创建索引
■CREATE INDEX加上各个索引关键字便可创建各个类型的索引
■创建普通索引
create index <索引的名字> on tablename (列的列表);
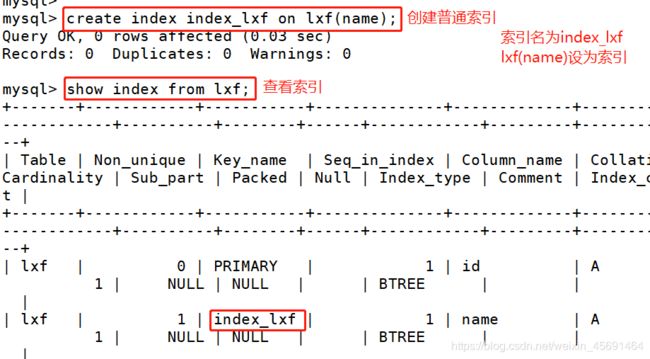
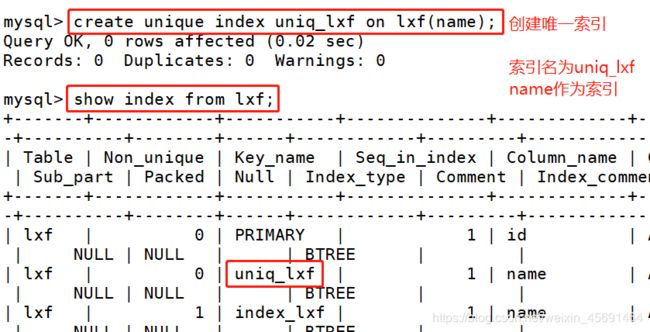
■创建唯一性索引
create unique index <索引的名字> on tablename (列的列表);
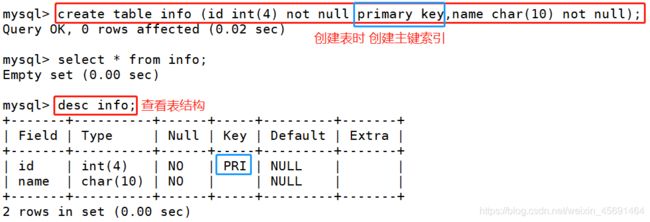
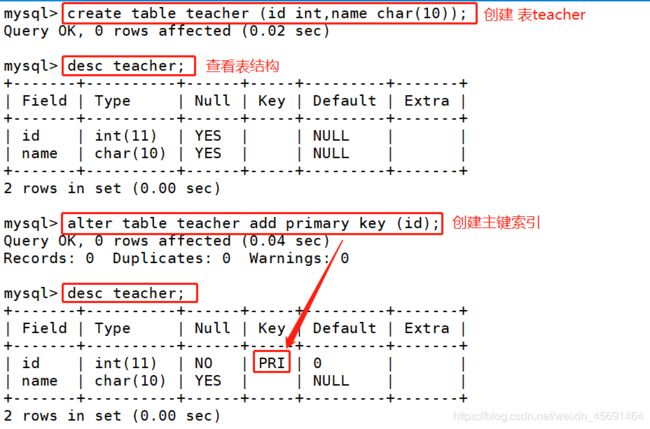
■创建主键索引 2种方式:
<1> create table tablename ( […],primary key (列的列表) );
<2> alter table tablename add primary key (列的列表);
1:在创建表时创建主键索引
2:表已存在的情况下,创建主键索引:
■创建全文索引:

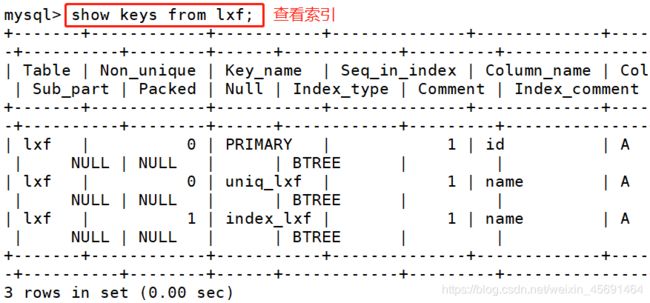
■索引查看
show index from tablename;
show keys from tablename ;

五、事务的概念
■事务是一种机制、一个操作序列,包含了- -组数据库操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行
■事务是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是最小的控制单元
■适用于多用户同时操作的数据库系统的场景,如银行、保险公司及证券交易系统等等
■通过事务的整体性以保证数据的一致性
事务的ACID特点
■原子性(Atomicity)
事务是一个完整的操作,事务的各元素是不可分的(原子的);事务中的所有元素必须作为一个整体提交或回滚,如果事务中的任何元素失败,则整个事务将失败
■一致性(Consistency)
当事务完成时,数据必须处于一致状态; 在事务开始之前,数据库中存储的数据处于一致状态;在正在进行的事务中,数据可能处于不一致的状态; 当事务成功完成时,数据必须再次回到已知的一致状态
■隔离性(Isolation)
对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务; 修改数据的事务可以在另一个使用相同数据的事务开始之前访问这些数据,或者在另一个使用相同数据的事务结束之后访问这些数据
■持久性(Durability)
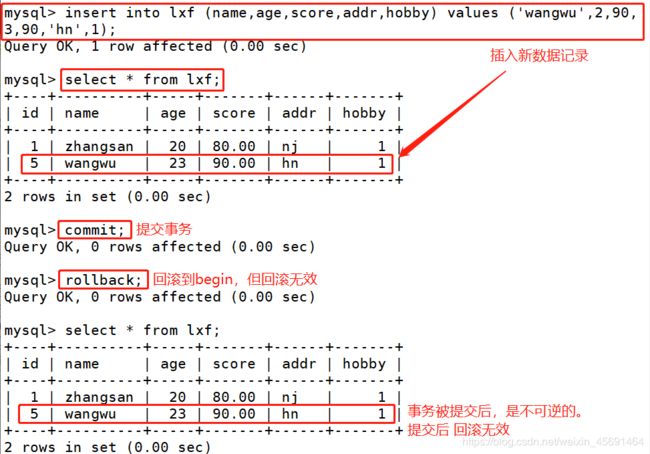
事务持久性指不管系统是否发生故障,事务处理的结果都是永久的, 一旦事务被提交,事务的效果会被永久地保留在数据库中
事务的操作
■默认情况下MySQL的事务是自动提交的,当sql语句提交时事务便自动提交
■手动对事务进行控制的方法
事务处理命令控制
使用set设置事务处理方式
■事务处理命令控制事务
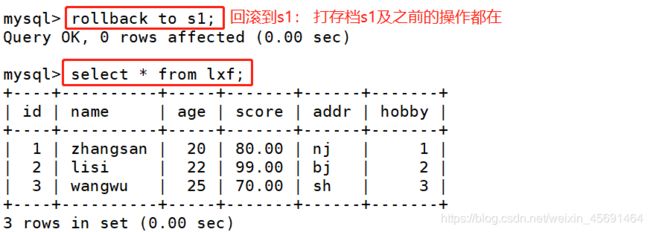
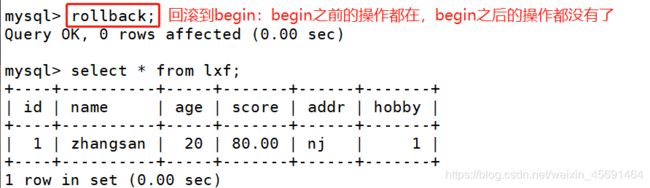
●begin:开始一个事务
●commit:提交一个事务
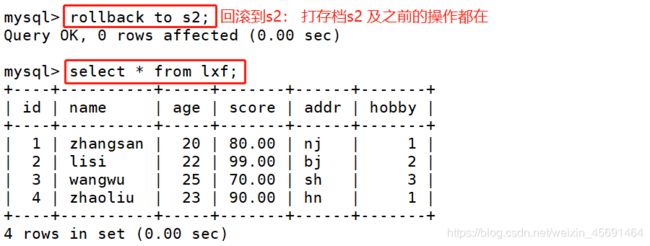
●rollback:回滚一个事务
■使用set命令进行控制
●set autocommit=0 : 禁止自动提交
●set autocommit=1 : 开启自动提交

六、视图的概念:
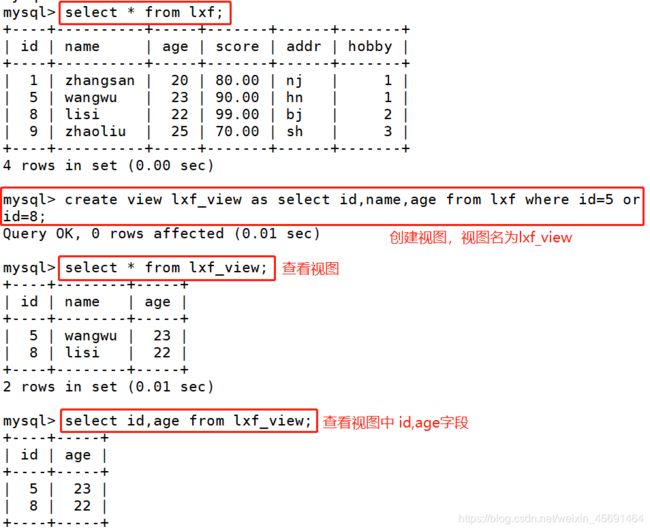
视图是一张虚拟的表,数据不存在视图中,是真实表的映射数据。如水中捞月。软连接。自己照镜子。是利用条件筛选 分组 排序等 产生出 一个结果集,把结果集做成持久化保存,保存在内存上。真实表中的数据有变化,视图中的数据也会变。
好处:能够方便友好的查询,不占空间。
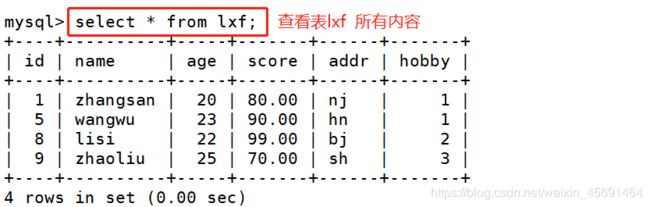
1,基于单表,创建视图:
2,基于多表相连,创建视图: