廖雪峰Python教程梳理
文章目录
-
-
- 一、不标准前言
- 二、安装python
- 三、编写第一个python程序
- 四、语法复习
-
-
- (1)对变量赋值x = y
- (2)除法类多一个 // 称“地板除”,结果永远是整数,即使除不尽。
- (3)转义字符(2种)、换行符(2种)——练习:打印出以下值
- (4)str与bytes的转换
- (5)格式化
- (6)列表list[] 元组tuple()
- (7)循环 for...in... 与range()
- (8)dict {} 和 set ( [ 1,2,3 ] )
-
- 五、函数
-
-
- (1)自行命名函数名
- (2)定义函数 def
- (3)参数检查、函数返回多个值
- (4)默认参数(有一个空值的坑回看教程)
- (5)\* 可变参数、\** 关键字参数、命名关键字参数、参数组合
- (6)递归函数
-
- 六、高级特性
-
-
- (1)切片:取指定索引范围的元素
- (2)迭代
- (3)列表生成式
- (4)生成器 generator
- (5)迭代器 Iterator(可迭代对象:Iterable)
-
- 七、函数式编程
-
-
- (1)高阶函数
-
- (1)map/reduce
- (2)filter (过滤序列)
- (3)sorted (排序list算法)
- (2)返回函数(返回值是一个函数)、闭包
- (3)匿名函数
- (4)装饰器
- (5)偏函数
-
- 八、模块(Module)
-
-
- (1)介绍
- (2)使用模块的写法
- (3)作用域
- (4)安装第三方模块
-
- 九、面向对象编程Object Oriented Programming(数据封装、继承和多态)
-
-
- (1)类(Class)和实例(Instance)——面向对象最重要的概念
- (2)访问限制——private、public
- (3)继承和多态
- (4)静态语言 vs 动态语言
- (5)获取对象信息
- (6)实例属性和类属性
-
- 十、面向对象高级编程(多重继承、定制类、元类)
-
-
- (1)使用 \__slots\__(限制实例可添加的属性)
- (2)使用@property 装饰器
- (3)多重继承——直接继承多个类——MixIn
- (4)定制类
- (5)使用枚举类
- (6)使用元类 metaclass,type( )
-
- 十一、 错误、调试与测试
-
-
- (1)错误处理
- (2)调试
- (3)单元测试
- (4)文档测试
-
- 十二、IO编程
-
-
- (1)从文件读写
- (2)从内存读写StringIO和ByteslO
- (3)操作文件和目录(查看当前路径、查找目标文件、创建/删除目录...)
- (4)序列化pickling 与 JSON
-
- 十三、进程(Process)和线程(Thread)
-
-
- (1)多进程
- (2)多线程
- (3)ThreadLocal
- (4)进程 vs 线程
- (5)分布式进程
-
- 十四、正则表达式
- 十五、常用内建模块
- 十六、常用第三方模块 virtualenv
- 十七、图形界面
- 十八、网络编程
-
-
- (1)TCP/IP简介
- (2)TCP编程
- (3)UDP编程
-
- 十九、电子邮件
-
-
- (1)SMTP发送邮件
- (2)POP3收取邮件
-
- 二十、访问数据库
-
-
- 数据库前导知识
- (1)使用SQLite
- (2)使用MySQL
- (3)使用SQLAIchemy
-
- 二十一、Web开发
- 二十二、异步IO
-
一、不标准前言
C语言适合开发那些追求运行速度、充分发挥硬件性能的程序。而Python是用来编写应用程序的高级编程语言。
除了编写代码外,还需要很多基本的已经写好的东西,来帮助你加快开发进度。高级编程语言通常都会提供一个比较完善的基础代码库,让你能直接调用,除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。
那Python适合开发哪些类型的应用?
首选是网络应用,包括网站、后台服务等等;
其次是许多日常需要的小工具,包括系统管理员需要的脚本任务等等;
另外就是把其他语言开发的程序再包装起来,方便使用。
python缺点:1、运行速度慢 2、代码不能加密,如果要发布你的python程序实际上就是发布源代码,这一点跟C语言不同,C语言不用发布源代码,只需要把编译后的机器码(也就是你在Windows上常见的xxx.exe文件)发布出去。要从机器码反推出C代码是不可能的,所以,凡是编译型的语言,都没有这个问题,而解释型的语言,则必须把源码发布出去。(不过影响都不大)
二、安装python
官网下载——配置环境变量——命令行“python”是否安装成功
Python解释器有很多,如CPython,IPython,PyPy,Jython,IronPython…其中,当我们从Python官方网站下载并安装好Python 3.x后,我们就直接获得了一个官方版本的解释器:CPython 这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
三、编写第一个python程序
复习一下如何进入python交互模式:
(1)在命令行下敲python进入,在python交互模式下输入exit()并回车,将回到命令行模式。
(2)直接通过开始菜单选择Python (command line)菜单项,直接进入Python交互模式,但是输入exit()后窗口会直接关闭,不会回到命令行模式。
ps两点注意:
(1)如何在命令行模式下运行一个.py文件:执行python hello.py,注意当前文件路径是否正确。
(2)Python交互模式的代码是输入一行,执行一行,而命令行模式下直接运行.py文件是一次性执行该文件内的所有代码。可见,Python交互模式主要是为了调试Python代码用的,也便于初学者学习,它不是正式运行Python代码的环境!
文本编辑器
推荐微软出品的Visual Studio Code,它是一个精简版的迷你Visual Studio,并且可以跨平台Windows、Mac和Linux通用。(注:不要用Word和Windows自带的记事本。Word保存的不是纯文本文件,而记事本会自作聪明地在文件开始的地方加上几个特殊字符(UTF-8 BOM),结果会导致程序运行出现莫名其妙的错误。)
高效用法:用Python开发程序,完全可以一边在文本编辑器里写代码,一边开一个交互式命令窗口,在写代码的过程中,把部分代码粘到命令行去验证,事半功倍。
Python代码运行助手 - 廖雪峰的官方网站
https://www.liaoxuefeng.com/wiki/1016959663602400/1018877595088352
四、语法复习
(1)对变量赋值x = y
意思是把变量x指向真正的对象,该对象是变量y所指向的。随后对变量y的赋值不影响变量x的指向。

(2)除法类多一个 // 称“地板除”,结果永远是整数,即使除不尽。
(3)转义字符(2种)、换行符(2种)——练习:打印出以下值
n = 123
f = 456.789
s1 = 'Hello, world'
s2 = 'Hello, \'Adam\''
s3 = r'Hello, "Bart"'
s4 = r'''Hello,
Lisa!'''
(4)str与bytes的转换
字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
bytes类型的数据用带 b‘ 数据 ’ 或者 b“ 数据 ” 表示,如 x = b‘ ABC ’
要注意区分’ABC’和b’ABC’,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "", line 1, in
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
//综上,纯英文str可以用ASCII编码为bytes,含有中文的str可以用UTF-8编码为bytes,但是含中文str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
如果bytes中包含无法解码的字节,decode()方法会报错;如果bytes中只有一小部分无效的字节,可以传入errors='ignore’忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
len()函数,可计算str包含多少个字符,可计算bytes包含多少个字节
>>> len('中文'.encode('utf-8'))
6
//可见,1个中文字符经过utf-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3 //这是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
# -*- coding: utf-8 -*-//这是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
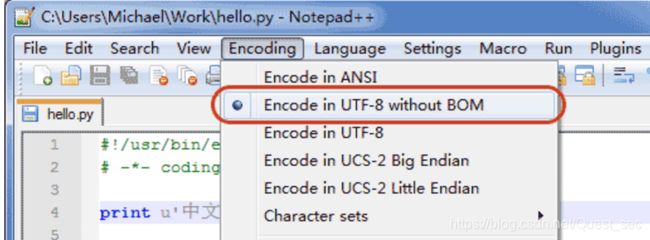
如果.py文件本身使用UTF-8编码,并且也申明了# -- coding: utf-8 --,打开命令提示符测试就可以正常显示中文:
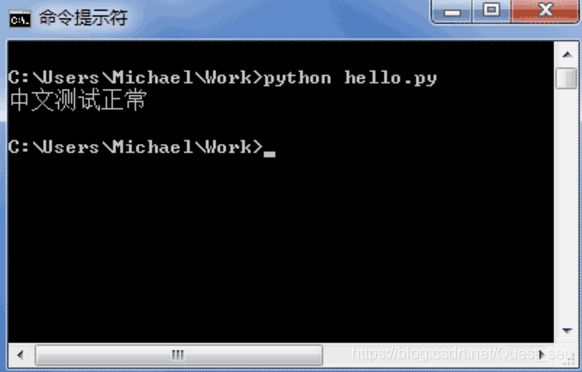
(5)格式化
如何输出格式化的字符串。比如 “亲爱的xxx你好!你xx月的话费是xx,余额是xx” 之类的字符串,而xxx的内容都是根据变量变化的。做法与c一致,用%实现。

比如
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> print('Her name is %s , and age is %d ' % ('manny',18) )
Her name is manny , and age is 18
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串。
如果要打印 % 呢?转义——用 %% 来表示一个 %
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'
(6)列表list[] 元组tuple()
(0)索引从【0】开始
(1)最后一个元素的索引是 len(列表名)-1,或者直接获取 列表名[-1]、列表名[-2]倒数第二个…
(2)list里面的元素的数据类型可以不同
(3)list是一个可变的有序表,可以往list中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
删除末尾一个:pop()
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy','Adam']
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置。
list元素也可以是另一个list,即把s看作一个二维数组,如下:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4
要拿到’php’,写做s[2][1] (时刻注意索引从0开始!!!)
那么元组tuple呢?
tuple和list非常类似,但是tuple一旦初始化就不能修改,只可以获取元素数据。
不可变的tuple有什么意义?
因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:
当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,即每个都赋值。
如果定义一个空的tuple: t =()
如果定义只有1个元素的tuple:t = (1,) 逗号消除歧义。
一个可变的情况?
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
即 tuple中含有一个list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向’a’,就不能改成指向’b’,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
(7)循环 for…in… 与range()
names = ['Michael', 'Bob', 'Tracy']
for x in names:
print(x)
会依次打印names的每一个元素:
Michael
Bob
Tracy
Python提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。比如range(5)生成的序列是从0开始小于5的整数:
>>> list(range(5))
[0, 1, 2, 3, 4]
注意,不要滥用break和continue语句。break和continue会造成代码执行逻辑分叉过多,容易出错。大多数循环并不需要用到break和continue语句。有时代码有问题,会让程序陷入“死循环”,也就是永远循环下去。这时可以用Ctrl+C退出程序,或者强制结束Python进程。
(8)dict {} 和 set ( [ 1,2,3 ] )
(1)dictionary字典,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。每组一对数据,查找快速。其中“索引”责任的值称“Key”,注意dict内部存放的顺序和key放入的顺序是没有关系的。
d = {'Michael': 95,'Tracy': 85} //直接赋值
和list比较,dict有以下几个特点:
查找和插入的速度极快,不会随着key的增加而变慢;
需要占用大量的内存,内存浪费多。
而list相反:
查找和插入的时间随着元素的增加而增加;
占用空间小,浪费内存很少。
使用dict非常重要,牢记dict的key必须是不可变对象。这是因为dict根据key来计算value的存储位置,这个通过key计算位置的算法称为哈希算法(Hash)。要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key。
(2)set 和dict类似,也是一组key的集合,但不存储value。
要创建一个set,需要提供一个list作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3} //注意用的是什么括号,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的
使用dict和set https://www.liaoxuefeng.com/wiki/1016959663602400/1017104324028448
五、函数
(1)自行命名函数名
>>> a = max(1,2,3)
>>> a
3
(2)定义函数 def
(1)格式(定义一个绝对值函数)
│>>> def my_abs(x): │
│... if x >= 0: │
│... return x │
│... else: │
│... return -x │
│... │
│>>> my_abs(-9) │
│9
(2)一个空函数
def nop():
pass
pass语句什么都不做,那有什么用?实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
pass还可以用在其他语句里,比如:
if age >= 18:
pass
缺少了pass,代码运行就会有语法错误。
(3)参数检查、函数返回多个值
https://www.liaoxuefeng.com/wiki/1016959663602400/1017106984190464
(4)默认参数(有一个空值的坑回看教程)
https://www.liaoxuefeng.com/wiki/1016959663602400/1017261630425888
默认参数如 sum(x,n=2),第二个位置的数字默认是2,只需要输入一个值即可。
默认函数的意义?
举个例子,我们写个一年级小学生注册的函数,需要传入name,gender,age,city四个参数:大多数人age,city相同,则设为默认值,只有与默认值不符的学生才需要手动填写,大大减轻工作量√(注意参数顺序)
(5)* 可变参数、** 关键字参数、命名关键字参数、参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
>>> f1(1, 2)
a = 1 b = 2 c = 0 args = () kw = {}
>>> f1(1, 2, c=3)
a = 1 b = 2 c = 3 args = () kw = {}
>>> f1(1, 2, 3, 'a', 'b')
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
>>> f1(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
>>> f2(1, 2, d=99, ext=None)
a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
总结
*args是可变参数,args接收的是一个tuple;
** kw是关键字参数,kw接收的是一个dict。
以及调用函数时如何传入可变参数和关键字参数的语法:
可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过*args传入:func(*(1, 2, 3));
关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过 ** kw传入:func(**{‘a’: 1, ‘b’: 2})。
使用*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符*,否则定义的将是位置参数。
(6)递归函数
如果一个函数在内部调用自身本身,这个函数就是递归函数。
使用递归函数注意防止栈溢出。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
解决递归调用栈溢出的方法是通过尾递归优化,实际上和循环效果一样。尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。
六、高级特性
(1)切片:取指定索引范围的元素
适用于list、tuple、str
(2)迭代
给定一个list或tuple,通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration),(事实上str也适用)
(3)列表生成式
用来创建很大的list,快捷简单,比如要生成[1x1, 2x2, 3x3, …, 10x10]怎么做?
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
还可以使用两层循环,可以生成全排列:
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
注:在一个列表生成式中,for前面的if … else是表达式,而for后面的if是过滤条件,不能带else。
(4)生成器 generator
https://www.liaoxuefeng.com/wiki/1016959663602400/1017318207388128
generator是非常强大的工具,在Python中,可以简单地把列表生成式改成generator,也可以通过函数实现复杂逻辑的generator。
创建一个generator的方法:
(1)只要把一个列表生成式的[]改成(),就创建了一个generator:区别仅在于最外层的 [ ] 和()
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
at 0x1022ef630>
那么如何打印出来呢?正确做法是使用for循环:
>>> g = (x * x for x in range(10))
>>> for n in g:
... print(n)
...
(2)如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:注意的是generator和函数的执行流程不一样,它在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
————————————————————————
总结:
要理解generator的工作原理,它是在for循环的过程中不断计算出下一个元素,并在适当的条件结束for循环。对于函数改成的generator来说,遇到return语句或者执行到函数体最后一行语句,就是结束generator的指令,for循环随之结束。
注意区分普通函数和generator函数,普通函数调用直接返回结果:
>>> r = abs(6)
>>> r
6
generator函数的“调用”实际返回一个generator对象:
>>> g = fib(6)
>>> g
(5)迭代器 Iterator(可迭代对象:Iterable)
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列(惰性可理解为:我们不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,只有在需要返回下一个数据时它才会计算);
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
(Python的for循环本质上就是通过不断调用next()函数实现的)
使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
七、函数式编程
函数式编程区别于函数编程——虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
(1)高阶函数
指一个函数接收另一个函数作为参数。
def add(x, y, f):
return f(x) + f(y)
print(add(-5, 6, abs)) //以另一个函数作为参数传进去
(1)map/reduce
map( ) 函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
reduce() 函数接收两个参数,一个 {接收两个参数}的函数,一个序列,reduce把函数作用在序列的第一个元素上,结果继续和序列的下一个元素做累积计算,即得到一个综合作用的结果。比方说对一个整数13579的各位求和:
(2)filter (过滤序列)
filter() 也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
(3)sorted (排序list算法)
直接进行数字排序:
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
此外,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']
(2)返回函数(返回值是一个函数)、闭包
没听懂
https://www.liaoxuefeng.com/wiki/1016959663602400/1017434209254976
(3)匿名函数
格式:lambda x: …
关键字lambda表示匿名函数,冒号前面的x表示函数参数,…是函数内容。
匿名函数的限制:只能有一个表达式,不用写return,返回值就是该表达式的结果。
匿名函数的意义?
(1)因为函数没有名字,不必担心函数名冲突。
(2)匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
>>> f = lambda x: x * x
>>> f
at 0x101c6ef28>
>>> f(5)
25
同样,也可以把匿名函数作为返回值返回。
(4)装饰器
函数对象有一个__name__属性,可以拿到函数的名字。假设我们要增强now()函数的功能,,但又不去修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为**“装饰器”(Decorator)**。
本质上,decorator就是一个返回函数的高阶函数。
(5)偏函数
Python的functools模块内的,意义是把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
即当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017454145929440
八、模块(Module)
(1)介绍
在Python中,一个.py文件就称之为一个模块(Module)。
(一)使易于维护。在开发程序的过程中,为了简洁与可维护,通常将很多函数分组,分别放到不同的文件里,这样,不至于一打开所有代码直接罗列下来一长串特别多。
(二)编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
(三)使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量可以分别存在不同的模块中。另外,为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package),比如如下的目录结构:
mycompany
├─ web
│ ├─ init.py
│ ├─ utils.py
│ └─ www.py
├─ init.py
├─ abc.py
└─ utils.py
文件www.py的模块名就是mycompany.web.www,两个文件utils.py的模块名分别是mycompany.utils和mycompany.web.utils。 引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。
注:模块名不要和系统模块名冲突,最好先查看系统是否已存在该模块,检查方法是在Python交互环境执行import abc,若成功则说明系统存在此模块。
(2)使用模块的写法
************ //标准化段落
import sys //导入模块
************ //通过sys这个变量,来访问sys模块的所有功能
if __name__=='__main__': //最后两行:这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
test()
(3)作用域
有的函数和变量我们希望给别人使用,有的函数和变量我们希望仅仅在模块内部使用。在Python中,是通过 _ 前缀来实现的。
(1)正常的函数和变量名是公开的(public),可以被直接引用;
(2)类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的__author__,__name__就是特殊变量,hello模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名;
(3)类似_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;(注:不应该 ≠ 不能,出于编程习惯 默认不这么用而已)
如:
def _private_1(name):
return 'Hello, %s' % name
def _private_2(name):
return 'Hi, %s' % name
def greeting(name):
if len(name) > 3:
return _private_1(name)
else:
return _private_2(name)
我们在模块里公开greeting()函数,而把内部逻辑用private函数隐藏起来了,这样,调用greeting()函数不用关心内部的private函数细节,这也是一种非常有用的代码封装和抽象的方法,即:
外部不需要引用的函数全部定义成private,只有外部需要引用的函数才定义为public。
(4)安装第三方模块
pip是Python官方建议的包安装工具,可以使用pip快速安装python支持的大部分模块,不过一个一个安装模块费时费力,推荐直接使用Anaconda,可以从Anaconda官网下载GUI安装包,下载后直接安装。这是一个基于Python的数据处理和科学计算平台,它已经内置了许多非常有用的第三方库,我们装上Anaconda,就相当于把数十个第三方模块自动安装好了,非常简单易用。
九、面向对象编程Object Oriented Programming(数据封装、继承和多态)
OOP是一种程序设计思想,把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
面向对象与面向过程
(1)面向过程 的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。
(2)而面向对象 的程序设计把计算机程序视为一组对象集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017495723838528
数据封装、继承和多态是面向对象的三大特点,后面详细讲解。
(1)类(Class)和实例(Instance)——面向对象最重要的概念
类是抽象的模板,比如Student类;而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据互相独立,互不影响;
方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;
通过在实例上调用方法,我们就直接操作了对象内部的数据,但无需知道方法内部的实现细节。
(1)定义Student类:
class Student(object):
pass
(2)创建Student的实例: 实例名字 = 类名( )
>>> bart = Student( )
>>> bart
<__main__.Student object at 0x10a67a590>
>>> Student
————————————————————————————————————————
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self,并且,调用时,不用传递该参数。
python中的__init__()方法相当于java中的构造函数,我们可以使用__init__()方法来传递参数,比如赋值给对象属性等。
(复习:类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,我们自己定义变量一般不用这格式)
数据封装
这样一来,我们从外部看Student类,只需要知道,传入什么参数,而如何打印,print…都不需要写,这都是在Student类的内部定义的,这些数据和逻辑被“封装”起来了,调用很容易,但不用知道内部实现的细节。
(2)访问限制——private、public
访问限制 - 廖雪峰的官方网站
https://www.liaoxuefeng.com/wiki/1016959663602400/1017496679217440
(3)继承和多态
继承可以把父类的所有功能都直接拿过来,这样就不必重零做起,子类只需要新增自己特有的方法,也可以把父类不适合的方法覆盖重写,此时在运行中,总是会调用子类的方法。这样,我们就获得了继承的另一个好处:多态,即:
对于一个变量,我们只需要知道它是Animal类型,无需确切地知道它的子类型,就可以放心地调用run()方法,而具体调用的run()方法是作用在Animal、Dog、Cat还是Tortoise对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:
对扩展开放:允许新增Animal子类;
对修改封闭:不需要修改依赖Animal类型的run_twice()等函数。
(4)静态语言 vs 动态语言
静态语言(强类型语言)是在编译时变量的数据类型即可确定的语言,多数静态类型语言要求在使用变量之前必须声明数据类型。 例如:C++、Java、Delphi、C#等。
动态语言(弱类型语言)是在运行时确定数据类型的语言。变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型。
例如PHP/ASP/Ruby/Python/Perl/ABAP/SQL/JavaScript/Unix Shell等等。
特性:
强类型语言是一旦变量的类型被确定,就不能转化的语言。
弱类型语言则反之,一个变量的类型是由其应用上下文确定的。
换言之
对于静态语言(例如Java)来说,如果需要传入Animal类型,则传入的对象必须是Animal类型或者它的子类,否则,将无法调用run()方法。
对于Python这样的动态语言来说,则不一定需要传入Animal类型。我们只需要保证传入的对象有一个run()方法就可以了:这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。(只要有这个关键方法,而不是这个类的严格继承什么的无所谓)
(5)获取对象信息
优先使用isinstance()判断类型,可以将指定类型及其子类“一网打尽”。
使用type()函数:判断对象类型,它返回对应的Class类型。
使用types模块中定义的常量:判断一个对象是否是函数?
isinstance()判断的是一个对象是否是该类型本身,或者位于该类型的父继承链上。
使用dir()函数:它返回一个包含字符串的list,目的是获得一个对象的所有属性和方法。
(6)实例属性和类属性
实例属性属于各个实例所有,互不干扰;
class Student(object):
def __init__(self, name):
self.name = name
类属性属于类所有,所有实例共享一个属性;
class Student(object):
name = 'Student'
不要对实例属性和类属性使用相同的名字,否则将产生难以发现的错误。
十、面向对象高级编程(多重继承、定制类、元类)
(1)使用 _slots_(限制实例可添加的属性)
Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性:
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称,即Student的实例不再允许添加除name,age之外的属性
注:slots 定义的属性仅对当前类实例起作用,对继承的子类是不起作用的。除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。
(2)使用@property 装饰器
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
使用@property - 廖雪峰的官方网站
https://www.liaoxuefeng.com/wiki/1016959663602400/1017502538658208
(3)多重继承——直接继承多个类——MixIn
比如,让Ostrich除了继承自Bird外,再同时继承Runnable。这种设计通常称之为MixIn,MixIn的目的就是给一个类增加多个功能。
由于Python允许使用多重继承,因此,MixIn就是一种常见的设计。
只允许单一继承的语言(如Java)不能使用MixIn的设计。
(4)定制类
形如__xxx__的变量或者函数名要注意,在Python中是有特殊用途的。
Python的class允许定义许多定制方法,可以让我们非常方便地生成特定的类,以下介绍几个最常用的:
slots
len()方法我们也知道是为了能让class作用于len()函数。
str
iter
getitem
getattr
call
https://www.liaoxuefeng.com/wiki/1016959663602400/1017590712115904
(5)使用枚举类
Enum可以把一组相关常量定义在一个class中,且class不可变,而且成员可以直接比较。
(6)使用元类 metaclass,type( )
(1)type( )
动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的,而创建class的方法就是使用type()函数。
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
>>> print(type(h))
要创建一个class对象,type()函数依次传入3个参数:
class的名称;
继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上。
(2)元类 metaclass 是Python中非常具有魔术性的对象,它可以改变类创建时的行为。这种强大的功能使用起来务必小心。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017592449371072
十一、 错误、调试与测试
(1)有一类错误是在程序运行过程中完全无法预测的,比如写入文件的时候,磁盘满了,写不进去了,或者从网络抓取数据,网络突然断掉了。这类错误也称为异常,是必须处理的,否则,程序会因为各种问题终止并退出。
Python内置了一套异常处理机制,来帮助我们进行错误处理。
(2)此外,我们也需要跟踪程序的执行,查看变量的值是否正确,这个过程称为调试。Python的pdb可以让我们以单步方式执行代码。
(3)最后,编写测试也很重要。有了良好的测试,就可以在程序修改后反复运行,确保得到预期结果。
(1)错误处理
(1)try
单独为错误情况指定错误返回码太繁琐了,于是高级语言通常都内置了一套try…except…finally…的错误处理机制,Python也不例外。
try:
print('try...')
r = 10 / 0
print('result:', r)
except ZeroDivisionError as e:
print('except:', e)
finally:
print('finally...')
print('END')
注意:
1、可以没有finally语句
2、如果发生了不同类型的错误,应该由不同的except语句块处理。常见的错误类型和继承关系看这里:
https://docs.python.org/3/library/exceptions.html#exception-hierarchy
3、使用try…except捕获错误还有一个巨大的好处,就是可以跨越多层调用,比如函数main()调用foo(),foo()调用bar(),结果bar()出错了,这时,只要main()捕获到了,就可以处理。也就是说,不需要在每个可能出错的地方去捕获错误,只要在合适的层次去捕获错误就可以了。
(2) 调用栈
如果错误没有被捕获,它就会一直往上抛,最后被Python解释器捕获,打印一个错误信息,然后程序退出。这时候,一定要分析错误的调用栈信息,才能定位错误的位置。
(3) 记录错误
内置的logging模块可以用来记录错误信息,使程序在打印完错误信息后,继续执行,并正常退出。
只需导入
import logging
通过配置,logging还可以把错误记录到日志文件里,方便事后排查。
(4) 抛出错误
首先根据需要,定义一个错误的class,选择好继承关系,然后,用raise语句抛出一个错误的实例。最后执行,可以最后跟踪到我们自己定义的错误。
只有在必要的时候才定义我们自己的错误类型。如果可以选择Python已有的内置的错误类型(比如ValueError,TypeError),尽量使用Python内置的错误类型。
**(5)**层层提交的错误处理方式
https://www.liaoxuefeng.com/wiki/1016959663602400/1017598873256736
(2)调试
(1)简单直接粗暴有效:用print()把可能有问题的变量打印出来看看。用print()最大的坏处是将来还得删掉它,属于多余的垃圾信息。
(2)断言:
凡是用print()来辅助查看的地方,都可以用断言(assert)来替代,如果断言失败(False),assert语句本身就会抛出AssertionError。
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
def main():
foo('0')
程序中的大量assert相比print()也属于是垃圾信息,不过,启动Python解释器时可以用 -O参数来关闭assert,然后你将所有的assert语句视为pass即可。
$ python -O err.py
Traceback (most recent call last):
...
ZeroDivisionError: division by zero
(3)logging
和assert比,logging不会抛出错误,而且可以输出到文件:
import logging
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
运行,logging.info() 就可以输出一段文本。
(4)pdb
启动Python的调试器pdb,让程序以单步方式运行,可以随时查看运行状态。缺点是代码长的话就太麻烦了。
于是,有另一种:pdb.set_trace()
这个方法也是用pdb,但是不需要单步执行,我们只需要import pdb,然后,在可能出错的地方放一个pdb.set_trace(),就可以设置一个断点。(比直接启动pdb单步调试的效率高,但也不太高)
(5)IDE
方便设置断点、单步执行。如VS Code、PyCharm等。
(3)单元测试
针对一个模块、一个函数或一个类,编写几个测试用例,并全部放到一个测试模块里,就是一个完整的单元测试。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017604210683936
(4)文档测试
Python内置的“文档测试”(doctest)模块可以直接提取注释中的代码并执行测试。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017605739507840
十二、IO编程
本章的IO编程都是同步模式,使用异步IO来编写程序性能会远远高于同步IO,但是异步IO的缺点是编程模型复杂,后续再讨论。
(1)从文件读写
读入文件,最后close()关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:利用with语句更简洁,比close和try … finally都简洁
with open('/path/to/file', 'r') as f:
print(f.read())
写入文件,最后也要关闭
with open('/Users/michael/test.txt', 'w') as f:
f.write('Hello, world!')
(2)从内存读写StringIO和ByteslO
StringIO顾名思义,在内存中读写str 、BytesIO操作二进制数据,如图片
(3)操作文件和目录(查看当前路径、查找目标文件、创建/删除目录…)
在命令行下有操作系统提供的各种命令可以用,在python里如何操作呢?内置os模块封装了操作系统的目录和文件操作,要注意这些函数有的在os模块中,有的在os.path模块中。

nt 说明该系统是Win系统。posix 说明系统是Linux、Unix或Mac OS X。注意有些函数和OS有关,不一定支持win/linux。
(4)序列化pickling 与 JSON
在程序运行的过程中,所有的变量都是在内存中,可以随时修改一个变量的赋值,但是一旦程序结束,变量所占用的内存就被操作系统全部回收。如果没有把修改后的内容存储到磁盘上,下次重新运行程序,变量又被初始化为第一次赋值的值。把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输走。反之,从序列化对象重新读入内存里称“反序列化”,unpickling。
内置 pickle 模块来实现序列化,而Pickle的问题是它只能用于python,且可能不兼容不同版本,因此只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。那么,在不同的编程语言之间传递对象怎么办?
把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,可以方便地存储到磁盘或者通过网络传输,且比XML快。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
JSON类型 Python类型
{} dict
[] list
“string” str
123.45 int或float
true/false True/False
null None
python内置 json 模块提供了非常完善的Python对象到JSON格式的转换。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017624706151424
十三、进程(Process)和线程(Thread)
现在,多核CPU已经非常普及了,过去的单核CPU执行多任务的意思是OS让各个任务交替执行,由于CPU执行速度极快因此我们感觉不到切换而像是同时。真正的并行多任务只能在多核CPU上实现。
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个Word就启动了一个Word进程,打开两个word就启动了两个word进程。有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
由于每个进程至少要干一件事,所以,一个进程至少有一个线程。多线程的执行方式同前,也是OS在多个线程之间快速切换,看起来像同时执行一样。真正地同时执行需要多核CPU。
如果我们要同时执行多个任务怎么办?3个方式
多进程模式;(每个进程有一个线程,多个进程一起执行多个任务)
多线程模式;(启动一个进程,里的多个线程一起执行多个任务)
多进程+多线程模式。(多个进程,每个进程启动多个线程,最为复杂,实际很少采用)
注意:并行不是简单的并行,而需要相互通信和协调,有时,任务1必须暂停等任务2完成之后才能继续,有时,任务3与4又不能同时执行,所以多进程和多线程的复杂度远高于单进程单线程的程序。很多时候,多任务是不得不的,比如在电脑上看电影,必须由一个线程播放视频,一个线程播放音频,而单线程只能一次做一个。
(1)多进程
创建子进程的fork调用适用Linux/MAC,而windows没有,只能用python提供的另一个跨平台版本的多进程支持模块:multiprocessing模块来创建子进程,subprocess模块来启动一个子进程,然后控制其输入和输出。
进程间通信用multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
注:在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所以,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
(2)多线程
内置两个模块_thread和 threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行。
主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
Lock
多线程和多进程最大的不同:多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响。而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。
锁的原理:把锁给某一个线程的一段程序执行时,其他线程不能同时执行锁住的这部分内容,直到锁被释放,获得该锁才能改,即同一时间只有一个线程能改。通过 threading.Lock() 创建一个锁。获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用 try…finally 来确保锁一定会被释放。
死锁:由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并发在Python中就是一个美丽的梦。
(3)ThreadLocal
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。而局部变量也有问题,就是在函数调用的时候,传递起来很麻烦,于是出现了ThreadLocal:一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。解决了参数在一个线程中各个函数之间互相传递的问题。
(4)进程 vs 线程
多进程和多线程,是实现多任务最常用的两种方式。以下讨论优缺点。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017631469467456
(5)分布式进程
在Thread和Process中,应当优选Process,因为Process更稳定,且Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
Python的分布式进程接口简单,封装良好,适合需要把繁重任务分布到多台机器的环境下。
注意Queue的作用是用来传递任务和接收结果,每个任务的描述数据量要尽量小。比如发送一个处理日志文件的任务,就不要发送几百兆的日志文件本身,而是发送日志文件存放的完整路径,由Worker进程再去共享的磁盘上读取文件
https://www.liaoxuefeng.com/wiki/1016959663602400/1017631559645600
十四、正则表达式
字符串是编程时涉及到的最多的一种数据结构,正则表达式是一种用来匹配字符串的强有力的武器。
它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
所以我们判断一个字符串是否是合法的Email的方法是:
1、创建一个匹配Email的正则表达式;
2、用该正则表达式去匹配用户的输入——来判断是否合法。
(一)关于前缀符号
内置 re 模块,包含所有正则表达式的功能,为了解决转义问题,建议使用 r 前缀而不是 \ ,即
s = 'ABC\\-001' # Python的字符串 尽量不用
s = r ' ABC\-001' # Python的字符串 推荐用
match()方法判断正则是否匹配。如果匹配成功,返回一个Match对象,否则返回None。
(二)关于切分字符串:用正则表达式切分字符串比用固定的字符更灵活。
(三)分组:正则拥有提取子串的强大功能,用()表示要提取的分组(Group)。
(四)贪婪匹配:这是正则默认规则,也就是匹配尽可能多的字符。加个 ? 使之变为采用非贪婪匹配。
(五)编译:如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配。编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。
十五、常用内建模块
datetime是Python处理日期和时间的标准库,包括获取时间,转换时区等。
collections是Python内建的一个集合模块,提供了许多有用的集合类。
Base64是一种用64个字符来表示任意二进制数据的方法。
struct模块来解决bytes和其他二进制数据类型的转换。
hashlib提供了常见的摘要算法,如MD5,SHA1等等。什么是摘要算法呢?摘要算法又称哈希算法、散列算法。
Hmac算法:Keyed-Hashing for Message Authentication。它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中。和我们自定义的加salt算法不同,Hmac算法针对所有哈希算法都通用,无论是MD5还是SHA-1。采用Hmac替代我们自己的salt算法,可以使程序算法更标准化,也更安全。
itertools模块提供了非常有用的用于操作迭代对象的函数。
contextlib包含了一些使代码更简洁的方法,比如写很多try…finally比较繁琐,可以被代替。
urllib提供了一系列用于操作URL的功能。
XML虽然比JSON复杂,在Web中应用也不如以前多了,不过仍有很多地方在用,所以,有必要了解如何操作XML。
https://www.liaoxuefeng.com/wiki/1016959663602400/1017784095418144
HTMLParser来非常方便地解析HTML。
十六、常用第三方模块 virtualenv
PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用。
requests:处理URL资源特别方便。相比Python内置的urllib模块也是用于访问网络资源,但它用起来麻烦,且缺少很多实用的高级功能。
chardet:检测编码,简单易用。字符串编码一直是令人非常头疼的问题,尤其在处理一些不规范的第三方网页的时候。虽然Python提供了Unicode表示的str和bytes两种数据类型,并且可以通过encode()和decode()方法转换,但是,在不知道编码的情况下,对bytes做decode()不好做。
psutil = process and system utilities,获取系统信息,它不仅可以通过一两行代码实现系统监控,还可以跨平台使用,运维必备。
在开发一个Python应用程序的时候,所有第三方的包都会被pip安装到Python3的site-packages目录下。
如果我们要同时开发多个应用程序,那这些应用程序都会共用一个Python,就是安装在系统的Python 3。如果应用A需要jinja 2.7,而应用B需要jinja 2.6怎么办?这种情况下,每个应用可能需要各自拥有一套“独立”的Python运行环境。virtualenv就是用来为一个应用创建一套“隔离”的Python运行环境。
十七、图形界面
Python内置的Tkinter可以满足基本的GUI程序的要求,如果是非常复杂的GUI程序,建议用操作系统原生支持的语言和库来编写。
十八、网络编程
研究如何在程序中实现两台计算机上的两个进程之间的通信,比如,浏览器进程和新浪服务器上的某个Web服务进程在通信,而QQ进程是和腾讯的某个服务器上的某个进程在通信。
用Python进行网络编程,就是在Python程序本身这个进程内,连接别的服务器进程的通信端口进行通信。
(1)TCP/IP简介
起初各厂商自己规定一套协议,为了把全世界的所有不同类型的计算机都连接起来,必须规定一套全球通用的协议,互联网协议簇(Internet Protocol Suite)就是通用协议标准。有了Internet,任何私有网络,只要支持这个协议,就可以联入互联网。
互联网协议包含了上百种协议标准,但是最重要的两个协议是TCP和IP协议,所以,大家把互联网的协议简称TCP/IP协议。
IP地址:互联网上每个计算机的唯一标识就是IP地址。如果一台计算机同时接入到两个或更多的网络,比如路由器,它就会有两个或多个IP地址,所以,IP地址对应的实际上是计算机的网络接口,通常是网卡。
端口:在两台计算机通信时,只发IP地址是不够的,因为同一台计算机上跑着多个网络程序。一个TCP报文来了之后,到底是交给浏览器还是QQ,就需要端口号来区分。每个网络程序都向操作系统申请唯一的端口号,这样,两个进程在两台计算机之间建立网络连接就需要各自的IP地址和各自的端口号。
一个进程也可能同时与多个计算机建立链接,因此它会申请很多端口。
(2)TCP编程
(3)UDP编程
十九、电子邮件
(1)SMTP发送邮件
(2)POP3收取邮件
二十、访问数据库
数据库前导知识
如果你是数据库小白,请先看 廖雪峰零基础SQL教程
简单介绍:
(1)数据库模型分为层次模型、网状模型、关系模型三种。
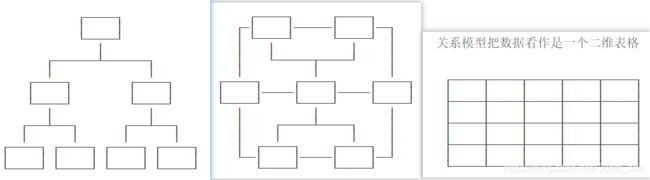
(2)数据库种类?当今互联网上最常见的是关系型数据库、非关系型数据库两种。
| 数据库模型 | 典型数据库 | |
|---|---|---|
| 关系型数据库 | 分类如下 | 几乎所有的数据库管理系统都配备了一个开放式数据库连接(ODBC)驱动程序,令各个数据库之间得以互相集成 |
| 付费的商用数据库:Oracle;DB2;Sybase;SQL Server 微软产品Windows定制专款… | 最大的好处是花了钱出了问题可以找厂家解决,不过在Web的世界里,常常需要部署成千上万的数据库服务器,如此开销巨大,于是Google、Facebook,国内的BAT,无一例外都选择了免费的开源数据库 | |
| 免费的开源数据库:MySQL用的最多,PostgreSQL偏学术气息;sqlite 嵌入式数据库,适合桌面和移动应用 | ||
| 非关系型数据库(NoSQL) | 4类如下 | Not Only SQL 是一项全新的数据库革命性运动,提倡运用非关系型的数据存储 |
| (1)键值存储数据库(key-value) | 典型产品:Memcached、Redis、MemcacheDB | |
| (2)列存储(Column-oriented)数据库 | 典型产品:Cassandra、HBase | |
| (3)面向文档(Document-Oriented)数据库 | 典型产品:MongoDB、CouchDB | |
| (4)图形数据库 | 典型产品:Neo4J、InforGrid |
(3)主流关系数据库 目前以下几类:
1、商用数据库,例如:Oracle,SQL Server,DB2等;
2、开源数据库,例如:MySQL,PostgreSQL等;
3、桌面数据库,以微软Access为代表,适合桌面应用程序使用;
4、嵌入式数据库,以Sqlite为代表,适合手机应用和桌面程序。
(4)什么是SQL?简单说,SQL就是访问和处理关系数据库的计算机标准语言。(也就是说,无论用什么语言编程,只要涉及到操纵关系数据库,都必须通过SQL来完成),不同的数据库,都支持SQL,这样,我们通过学习SQL这一种语言,就可以操作各种不同的数据库(注意,各个不同的数据库对标准的SQL支持不太一致,大部分数据库都在标准的SQL上做了扩展,扩展的这部分功能一般不支持其他数据库使用,称为“方言”)
(5)总之,SQL语言定义了以下操作数据库的能力:
DDL:Data Definition Language 允许用户定义数据,即创建表、删除表、修改表结构等,通常DDL由数据库管理员执行。
DML:Data Manipulation Language 为用户提供添加、删除、更新数据的能力,这些是应用程序对数据库的日常操作。
DQL:Data Query Language 允许用户查询数据,这也是通常最频繁的数据库日常操作。
(6)SQL语法特点:
SQL语言关键字不区分大小写!!!但是,针对不同的数据库,对于表名和列名,有的数据库区分大小写,有的数据库不区分大小写。同一个数据库,有的在Linux上区分大小写,有的在Windows上不区分大小写。
所以…本教程约定:SQL关键字总是大写,以示突出,表名和列名均使用小写。
(1)使用SQLite
(2)使用MySQL
(3)使用SQLAIchemy
二十一、Web开发
最早是CS架构:Client/Server模式,随着互联网的兴起,人们发现CS架构不适合Web,最大的原因是Web应用程序的修改和升级非常迅速,而CS架构需要每个客户端逐个升级桌面App,因此,Browser/Server模式开始流行,简称BS架构。在BS架构下,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web页面,并把Web页面展示给用户即可。比如,新浪提供的新闻、博客、微博等服务,均是Web应用。
Web应用开发可以说是目前软件开发中最重要的部分。Web开发也经历了好几个阶段:
1、静态Web页面
2、CGI
3、ASP/JSP/PHP
4、MVC
Web开发技术仍在快速发展,异步开发、新的MVVM前端技术层出不穷。
Python有上百种Web开发框架,有很多成熟的模板技术,选择Python开发Web应用,不但开发效率高,而且运行速度快。
二十二、异步IO
同步IO:如读写文件、发送网络数据时,需要等待IO操作完成,才能继续进行下一步操作。
因为一个IO操作就阻塞了当前线程,导致其他代码无法执行,所以我们必须使用多线程或者多进程来并发执行代码,为多个用户服务。
异步IO:当代码需要执行一个耗时的IO操作时,它只发出IO指令,并不等待IO结果,然后就去执行其他代码了。一段时间后,当IO返回结果时,再通知CPU进行处理。
消息模型是如何解决同步IO必须等待IO操作这一问题的呢?当遇到IO操作时,代码只负责发出IO请求,不等待IO结果,然后直接结束本轮消息处理,进入下一轮消息处理过程。当IO操作完成后,将收到一条“IO完成”的消息,处理该消息时就可以直接获取IO操作结果。在“发出IO请求”到收到“IO完成”的这段时间里,同步IO模型下,主线程只能挂起,但异步IO模型下,主线程并没有休息,而是在消息循环中继续处理其他消息。