Storm集群是如何启动的,任务是如何执行的?
1.Storm集群是如何启动的,任务是如何执行的?
集群架构中的各个模块如何启动?
任务如何分配,如何执行?
storm启动nimbus服务的命令:
cd /export/servers/storm/bin/
nohup ./storm nimbus &
1.客户端运行storm nimbus时,会调用storm的脚本,生成一条java命令,命令格式如下:
java -server xxx.ClassName -agrs
实际的情况:
Running: /export/servers/jdk/bin/java -server backtype.storm.daemon.nimbus

2. nohup storm supervisor & -- 后台启动supervisor
Running: /export/servers/jdk/bin/java -server backtype.storm.daemon.supervisor
storm集群启动之后,可以在zookeeper中查看

在storm节点下有5个节点:[workerbeats, storms, supervisors, errors, assignments]
assignments: 里面有所有的分配的任务信息
我先启动storm吉安中自带的wordcount程序:
./storm jar ../examples/storm-starter/storm-starter-topologies-0.9.5.jar storm.starter.WordCountTopology wordcount

3.nimbus启动之后,接收到kehuduan客户端提交的任务
提交任务的命令:
storm jar xxx.jar xxx驱动类 参数
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
Running: /export/servers/jdk/bin/java -client -Dstorm.jar=/export/servers/storm/
examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
该命令会执行 storm-starter-topologies-0.9.6.jar 里的main方法,main方法会执行一下代码:
StormSubmitter.submitTopology("mywordcount",config,topologyBuilder.createTopology())
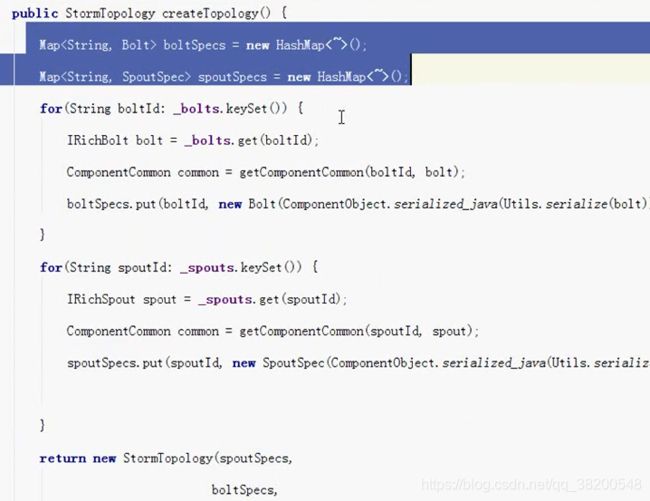
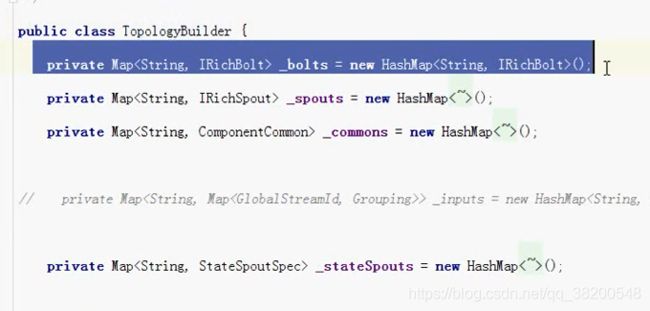

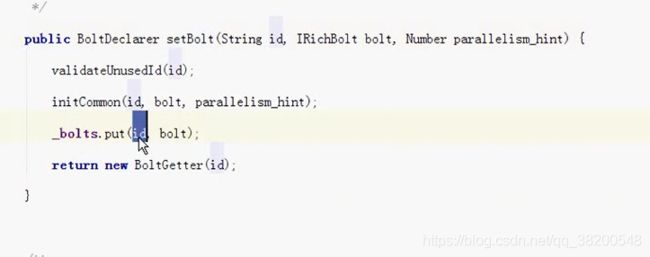
topologyBuilder.createTopology(),会将我们编写的spout对象和bolt对象进行序列化。
会将写的jar上传到nimbus物理节点的 /export/data/storm/workdir/nimbus/inbox目录下。并且改名,改名的规则是追加了一个UUID字符串
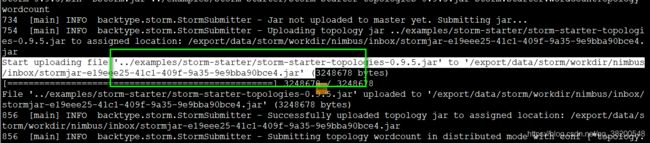

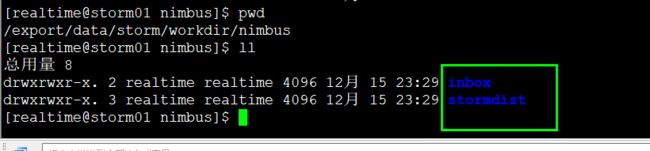
进入到stormdist这个目录:

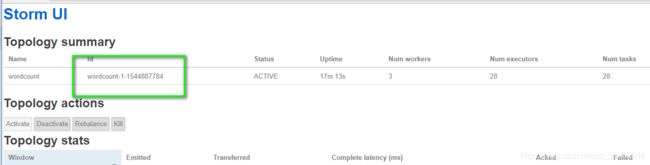
这个/export/data/storm/workdir/nimbus/stormdist/wordcount-1-1544887784下面有三个文件

有两个序列化文件:
stormcode.ser
stormconf.ser
在nimbus物理节点 /export/data/storm/workdir/nimbus/stormdist目录下,有当前正在运行的topology的jar包和配置文件。
4.接受到任务之后,会将任务分配,分配会产生一个assignment对象,该对象会保存到zookeeper中,
目录是/storm/assignments,该目录只保存正在运行的topology任务
这个assignments节点里面就会多一个任务:

如果你查看这个任务节点里面的内容,你会发现这个节点的内容全部是一些二进制的内容
get /storm/assignments/wordcount-1-1544887784
5. supervisor通过watch机制,感知到nimbus在zk上的任务分配信息,从zk上拉取任务信息,分辨出属于自己的任务。
![]()
6. 根据自己的任务信息,启动自己的worker,并分配一个端口。
![]()
7.worker启动之后,连接zk,拉取任务
![]()
任务是有类型的,假设任务信息:
1 —> spout-----type:spout
2 —> bolt ----- type:bolt
3 —> acker ---- type:bolt
worker通过反序列化,得到我们自己定义的spout和bolt对象。
8.worker根据任务类型分别执行spout任务或者bolt任务。
spout的生命周期是:open,nextTuple,outPutField
bolt的生命周期是:prepare,execute(tuple),outPutField
Storm本地目录树

Storm zookeeper目录树

2.集群是如何通信的?
集群架构中的各个模块是如何通信的?
拓扑程序中的各个Task是如何通信的?
sockt
3.如何保证消息的不丢失?
ack-fail机制是如何实现的?