憨批的语义分割9——语义分割评价指标mIOU的计算
憨批的语义分割9——语义分割评价指标mIOU的计算
- 注意事项
- 学习前言
- 什么是mIOU
- mIOU的计算
-
- 1、计算混淆矩阵:
- 2、计算IOU:
- 3、计算mIOU:
- 计算miou
注意事项
这是针对重构了的语义分割网络,而不是之前的那个,所以不要询问原来的网络计算miou要怎么做,因为整个文件构架差距过大,建议使用新构架。
新版的PSPnet:https://blog.csdn.net/weixin_44791964/article/details/106933112
学习前言
算一下语义分割的mIOU,做好生态链。

什么是mIOU
Mean Intersection over Union(MIoU,均交并比):其是语义分割的标准度量。
在了解mIOU之前,首先先了解一下IOU是什么,IOU的英文全称为Intersection over Union,中文简称为交并比,也就是交和并的比值。
在语义分割的问题中,单类的交并比就是该类的真实标签和预测值的交和并的比值。示意图如下:
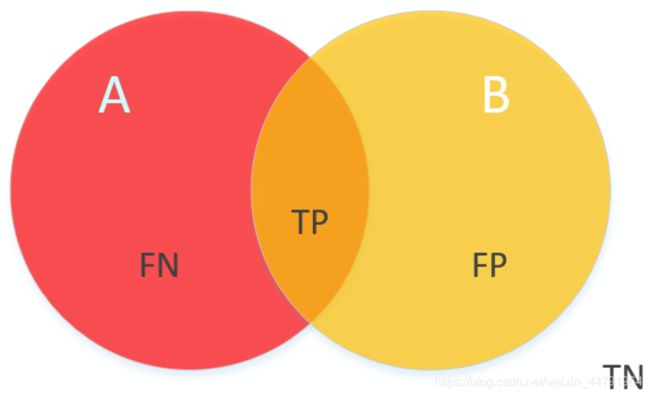
在图中,A为真实标签,占据了图像的一定区域;B为预测结果,占据了图像的一定区域。中间的TP部分就是真实标签和预测值的交,图像整个有颜色的部分就是真实标签和预测值的并。
而mIOU就是该数据集中的每一个类的交并比的平均。
计算公式如下:
i表示真实值,j表示预测值 , p i j p_{ij} pij表示将i预测为j
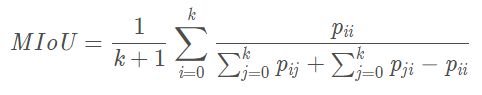
mIOU的计算
1、计算混淆矩阵:
混淆矩阵听起来很牛逼,其实实际上的实现非常简单。
假设我们现在有一百个样本,分别属于1、2、3、4类,每个类都有二十五个样本。
我们利用网络去进行分类,此时我们可以通过一个矩阵去表现出最终的预测效果,就是混淆矩阵。
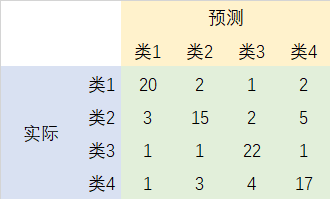
每一行之和是该类的真实样本数量,每一列之和是预测为该类的样本数量。
我们来看第一行,第一行意味着,有20个实际为类1的样本被分为类1,有2个实际为类1的样本被分为类2,有1个实际为类1的样本被分为类3,有1个实际为类1的样本被分为类4。
2、计算IOU:
混淆矩阵的对角线上的值是该类的交。
混淆矩阵的每一行再加上每一列,最后减去对角线上的值就是该类的并。
比如对于类1而言,一行一列是True Positive也就是,一行二列、三列、四列都是False Negative,二行一列、三行一列、四行一列都是False Positive。
按照IOU的示意图与公式,可以算出来
I O U 类 1 = 20 / ( ( 20 + 2 + 1 + 2 ) + ( 20 + 3 + 1 + 1 ) − 20 ) = 2 / 3 IOU_{类1} = 20 / ((20+2+1+2) + (20 + 3 + 1+ 1) - 20) = 2/3 IOU类1=20/((20+2+1+2)+(20+3+1+1)−20)=2/3
计算代码如下:
# 设标签宽W,长H
def fast_hist(a, b, n):
# a是转化成一维数组的标签,形状(H×W,);b是转化成一维数组的标签,形状(H×W,)
k = (a >= 0) & (a < n)
# np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
# 返回中,写对角线上的为分类正确的像素点
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
def per_class_iu(hist):
# 矩阵的对角线上的值组成的一维数组/矩阵的所有元素之和,返回值形状(n,)
return np.diag(hist) / (hist.sum(1) + hist.sum(0) - np.diag(hist))
3、计算mIOU:
mIOU就是每一个类的IOU的平均,所以只需要对每一个类都按照第二步的公式计算IOU,再求平均获得mIOU就行了。
np.mean(per_class_iu(hist)
计算miou
注意哈!!!
注意哈!!!
注意哈!!!
由于voc数据集的测试集并没有公开标签,我们以验证集为例,进行演示。
由于现在只出了新版的PSPnet的库,所以以PSPnet的库为例,进行演示。
首先把数据集按照voc格式摆好。
由于我现在使用的是官方的voc验证集,所以val.txt是官方提供好的。
如果大家想要验证自己的数据集,可以在voc2pspnet.py中修改train_percent改变验证集的比例(train_percent=0.9表示验证集为10%)。
修改完成后运行voc2pspnet.py。
在完成val.txt的生成后,修改pspnet.py中的num_classes为自己分的类的个数、model_path为权值文件路径。
class PSPNet(object):
#-----------------------------------------#
# 注意修改model_path和num_classes
# 使其符合自己的模型
#-----------------------------------------#
_defaults = {
"model_path" : 'model_data/pspnet_mobilenetv2.pth',
"model_image_size" : (473, 473, 3),
"downsample_factor" : 16,
"num_classes" : 21,
"backbone" : "mobilenet",
"cuda" : True,
"blend" : True,
}
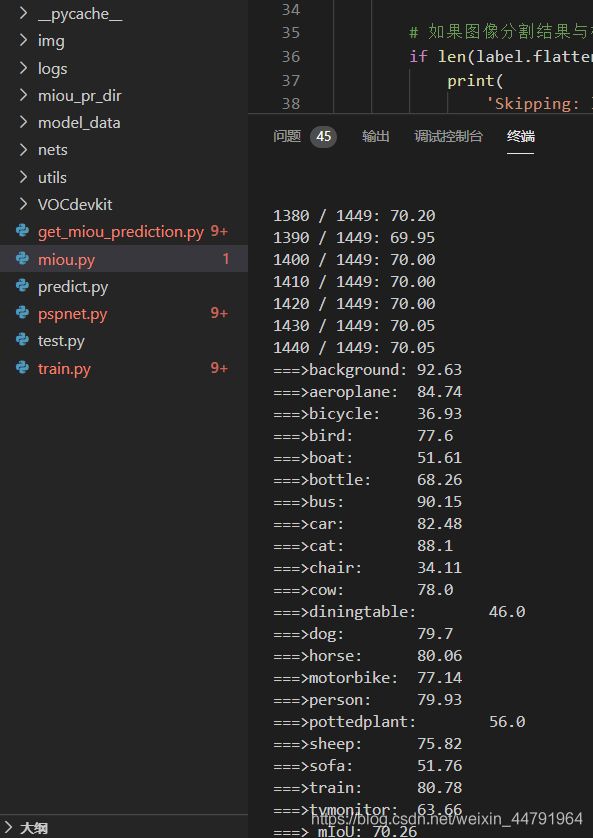
运行根目录的get_miou_prediction.py。
此时会生成预测灰度图。
然后运行根目录下的miou.py就会开始计算miou了。