DataWhale数据挖掘任务一
1:导入数据:
观察一下数据的维度,
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def initData():
fr=open('E:\BaiduNetdiskDownload\data.csv')
data=pd.read_csv(fr)
print(data.head(),data.shape)
if __name__=='__main__':
initData()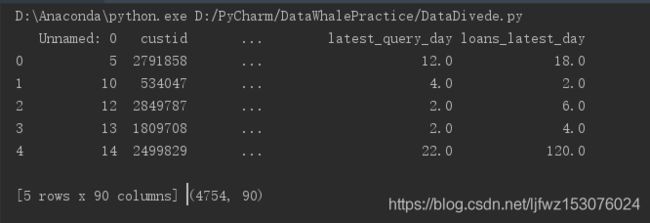
可以看到有4754个样本数据,每个样本有90列。
这份数据集是金融数据,我们要做的是预测贷款用户是否会逾期。表格中 "status" 是结果标签:0表示未逾期,1表示逾期。看一下正例和负例的分布情况。

未逾期:3561 逾期:1193
2.对数据的类型进行分析
print(data.dtypes.value_counts())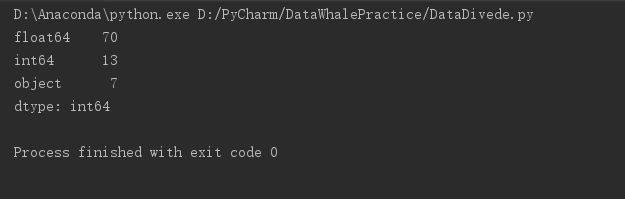
可以看到90列中70列为float,13列为int,7列object
看一下object类型的列名
print(data.select_dtypes(include='object').columns.values)
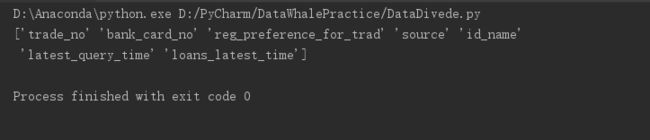
其实仔细观察中间有的列像first_transaction_time,它的值其实是日期的形式类似20130817这样,pandas把它认为是int型的,其实不是,也需要注意。
看一下这些object值的分布
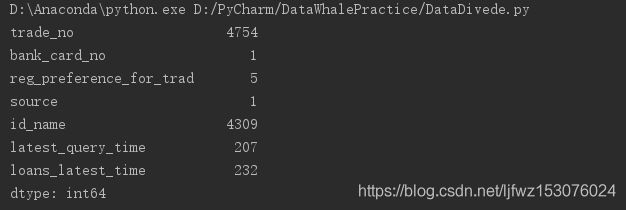
3.删除无关变量
data = data.drop(['id_name', 'latest_query_time','loans_latest_time',
'bank_card_no', 'source','custid','trade_no'], axis=1)4.缺失值处理
观察一下缺失值的情况:
def missValues(data):
mis_val = data.isnull().sum()
mis_val_percent = 100 * data.isnull().sum() / len(data)
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
mis_val_table_ren_columns = mis_val_table.rename(
columns={0: 'Missing Values', 1: '% of Total Values'})
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:, 1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
print("Your selected dataframe has " + str(data.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
return mis_val_table_ren_columns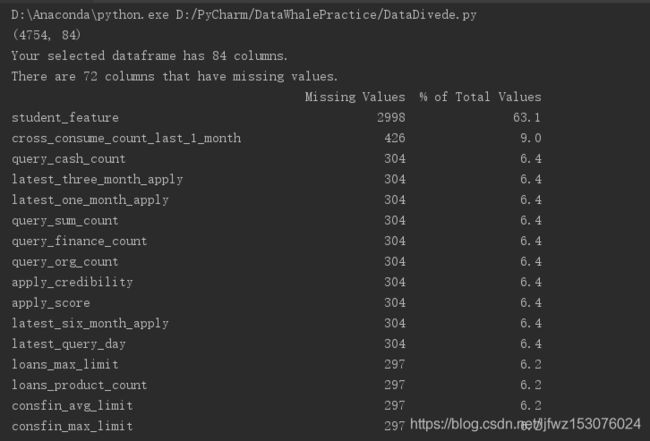
可以看到有72列有缺失值,其中student_feature特征有63.1%的样本缺失了,故而把这列删掉。
data = data.drop(['student_feature'], axis=1)找到有缺失值的列:
def find_na_column(df):
miss_columns = []
for column in df:
if sum(pd.isnull(df[column])) > 0:
miss_columns.append(column)
return miss_columns使用均值填充缺失值
for col in missColumns:
data[col]=data[col].fillna(data[col].mean())5.划分训练集和测试集:
label=data['status']
data = data.drop(['status'], axis=1)
X_train,X_test,y_train,y_test=train_test_split(data,label,test_size=0.3, random_state=2018)
参考链接:https://blog.csdn.net/chen19830/article/details/88068104