Udacity机器人软件工程师课程笔记(三十) - 语义分割与实例实现 - 使用keras实现语义分割
语义分割
1.语义分割介绍
计算机视觉与机器学习研究者对图像语义分割问题越来越感兴趣。越来越多的应用场景需要精确且高效的分割技术,如自动驾驶、室内导航、甚至虚拟现实与增强现实等。这个需求与视觉相关的各个领域及应用场景下的深度学习技术的发展相符合,包括语义分割及场景理解等…
更多可以参考语义分割概述.
在这个项目中,我们将训练一个深度神经网络,以从Quadcoptor模拟器生成的图像中识别目标人。拥有训练完成的网络后,我们可以通过推理使用它在新图像中找到目标。

在最终的Follow Me项目中,推理步骤必须在仿真中连续运行,就像直升机向其提供图像一样快。在本项目中引入了一些额外的代码抽象和性能增强,这些在进行仿真时是必需的,
- 环境设置
- TensorFlow中的Keras层
- 具有可分离卷积的编码器
- 批量归一化
- 具有双线性上采样的解码器
- 层级联
本实验使用来自模拟器的实际数据,最后,我们将拥有一个理论上可以正常运行的网络,可以将其整合到Follow Me项目中。我们将需要通过附加层,参数调整甚至收集更多数据来最大化网络性能。
(1)环境设置
在本实验中, 课程还是以jupternotebook的形式提供,为了方便我以后使用,我会再将来的内容更改成.py格式。
运行以下命令以克隆实验室存储库:
git clone https://github.com/udacity/RoboND-Segmentation-Lab.git
# Make sure your conda environment is activated!
jupyter notebook
或者进入https://github.com/udacity/RoboND-Segmentation-Lab.git去下载相应的压缩包解压到相应的路径中。其中包括储存库,训练数据和验证数据。
(2)Keras
Keras 是目前使用最为广泛的深度学习工具之一,它的底层可以支持Tensor Flow 、
MXNet、CNTK 和Theano 。如今, Keras 更是被直接引入了TensorFlow 的核心代码库,成为TensorFlow 官方提供的高层封装之一。
选择Keras的优点:
- 训练例程已简化,并通过标准接口提供。
- 不必自己管理tensorflow会话。
- 数据生成器具有标准接口。
- 这些层是具有语法层()(prev_layer)的类,而不是具有layer(prev_layer)的功能接口,层的命名约定在它们之间是相当标准的。
- Keras有额外的层来处理诸如上采样和其他小的特性,而在tensorflow中这些是分散的。
- 若想要向网络添加新功能,那么需要将功能包装在一个自定义层中,或者编写为lambda层。
(3)编码器
FCN是由编码器和解码器组成的。编码器部分是一个卷积网络,可简化为更深的1x1卷积层,而不是用于图像基本分类的平面全连接层。这种差异具有从图像中保留空间信息的效果。
这里介绍的可分离卷积是一种减少所需参数数量的技术,从而提高了编码器网络的效率。
可分离卷积
可分离卷积,也称为深度可分离卷积,由一个在输入层的每个通道上执行的卷积和一个1x1卷积组成,1x1卷积将前一步的输出通道合并成输出层。
这与我们之前介绍的常规卷积不同,主要是因为减少了参数的数量。让我们考虑一个简单的例子。
设输入形状是32x32x3。需要9个输出通道和形状为3x3x3的过滤器(内核)。在常规卷积中,9个内核遍历3个输入通道。这将导致总共933*3个特征(忽略偏置)。总共243个参数。
在可分卷积的情况下,通过3个输入通道,每个通道有一个内核。这给了我们27个参数(333)和3个特征图。在下一步中,这3个特征映射将被9个1x1卷积遍历。结果总共有27(9*3)个参数。总共有54(27 + 27)个参数!比我们上面得到的243个参数少得多。随着层或通道的大小的增加,这种差异将会更加明显。
参数的减少使得可分卷积在提高运行时性能的同时非常高效,因此对于移动应用程序也非常有用。由于参数较少,它们还具有在一定程度上减少过拟合的额外好处。
可分离卷积相关代码
在utils所提供的仓库的模块中提供了可分离卷积的优化版本。它基于tf.contrib.keras函数定义,可以实现如下:
output = SeparableConv2DKeras(filters, kernel_size, strides, padding, activation)(input)
其中,
input是输入层,
filters 是输出滤波器的数量(深度),
kernel_size是一个数字,指定内核的(宽度,高度),
padding 是“SAME”或“VALID”
activation是激活函数,例如“ relu”。
以下是如何使用上述功能的示例:
output = SeparableConv2DKeras(filters=32, kernel_size=3, strides=2,padding='same', activation='relu')(input)
(4)批处理归一化
批处理归一化是优化网络训练的另一种方法。
批量归一化基于以下思想:我们不仅将输入归一化到网络中,还将输入归一化到网络中的各个层。之所以称为“批处理”归一化,是因为在训练期间,我们使用当前迷你批处理中的值的均值和方差来归一化每一层的输入。
网络是一系列的层,其中一层的输出成为另一层的输入。这意味着我们可以把神经网络中的任何一层想象成更小网络的第一层。
例如,设想一个3层的网络。不要把它看作是一个具有输入、网络的层和输出的单一网络,而是把第1层的输出看作是一个两层网络的输入。这两层网络将由我们原来的网络中的第2层和第3层组成。
同样地,第2层的输出可以被认为是一个单层网络的输入,该网络只包含第3层。
当我们把它看作是一系列相互作用的神经网络时,就很容易想象把每一层的输入归一化会有多大帮助。这就像对任何其他神经网络的输入进行归一化一样,但是在每一层(子网络)都在这么做。
批归一化代码
在中tf.contrib.keras,可以使用以下函数定义来实现批量标准化:
from tensorflow.contrib.keras.python.keras import layers
output = layers.BatchNormalization()(input)
该separable_conv2d_batchnorm()函数在可分离卷积层之后添加批处理归一化层。引入批处理规范化层为我们提供了很多优势。
例如:
- 网络训练速度更快 – 由于前向传递期间的额外计算,每个训练迭代实际上会更慢。但是,它的收敛速度应该快得多,所以总体上训练应该更快。
- 允许更高的学习率 – 梯度下降法通常需要较小的学习速率才能使网络收敛。当网络越深,它们的梯度在反向传播时就越小,因此它们需要更多的迭代。使用批处理规范化允许我们使用更高的学习率,这进一步提高了网络训练的速度。
- 简化了更深层网络的创建 – 由于上述原因,在使用批处理规范化时,更容易构建并且更快地训练更深层的神经网络。
- 提供一些正则化 – 批处理归一化会给网络增加一些干扰。在某些情况下,例如在Inception模块中,批处理归一化已经被证明与dropout一样有效。
(5)解码器
在前面讲过转置卷积,作为将层向上采样到更高维度或分辨率的一种方法。实际上,有几种方法可以实现向上采样。在本节中,将介绍另一种方法,称为双线性上采样或双线性插值。
双线性上采样
双线性上采样是一种重采样技术,该技术利用与给定像素对角线的四个最接近的已知像素的加权平均值来估计新的像素强度值。加权平均值通常取决于距离。
让我们考虑这样一种情况:有4个已知像素值,因此本质上是2x2灰度图像。需要将此图像上采样为4x4图像。下图更好地说明了此过程。
 上面4x4插图中未标记的像素实际上是空白。双线性上采样方法将尝试通过插值来填充所有剩余的像素值。考虑 P 5 P_5 P5的情况来理解这个算法。
上面4x4插图中未标记的像素实际上是空白。双线性上采样方法将尝试通过插值来填充所有剩余的像素值。考虑 P 5 P_5 P5的情况来理解这个算法。
我们首先使用线性插值计算 P 12 P_{12} P12和 P 34 P_{34} P34的像素值。
P 12 = P 1 + W 1 ∗ ( P 2 − P 1 ) / W 2 P_{12}= P_1 + W_1*(P_2 - P_1)/W_2 P12=P1+W1∗(P2−P1)/W2
P 34 = P 3 + W 1 ∗ ( P 4 − P 3 ) / W 2 P_{34}= P_3 + W_1*(P_4 - P_3)/W_2 P34=P3+W1∗(P4−P3)/W2
使用P12和P34,我们可以得到P5:
P 5 = P 12 + H 1 ∗ ( P 34 − P 12 ) / H 2 P_5 = P_{12}+ H_1*(P_{34}- P_{12})/H_2 P5=P12+H1∗(P34−P12)/H2
为了简单起见,我们假设H_2 = W_2 = 1
将P34和P12代入后,P5像素值的最终方程为:
P 5 = P 1 ∗ ( 1 − W 1 ) ∗ ( 1 − H 1 ) + P 2 ∗ W 1 ∗ ( 1 − H 1 ) + P 3 ∗ H 1 ∗ ( 1 − W 1 ) + P 4 ∗ W 1 ∗ H 1 P_5 = P_1 * (1 - W_1) * (1 - H_1) + P_2 * W_1 * (1 - H_1) + P_3 * H_1 * (1 - W_1) + P_4 * W_1* H_1 P5=P1∗(1−W1)∗(1−H1)+P2∗W1∗(1−H1)+P3∗H1∗(1−W1)+P4∗W1∗H1
虽然数学变得更加复杂,上面的技术也可以扩展到RGB图像。
双线性上采样器代码
已在utils所提供的repo 的模块中提供了双线性上采样器的优化版本,可以按以下方式实现:
output = BilinearUpSampling2D(row, col)(input)
其中,
input是输入层,
row 是输出层各行的上采样系数,
col 是输出层各列的上采样系数,并且
output 是输出层。
以下是如何使用上述功能的示例:
output = BilinearUpSampling2D((2,2))(input)
双线性升采样方法没有像体系结构中的转置卷积那样有助于学习,并且容易丢失一些更详细的细节,但有助于提高性能。
(6)层级联
前面介绍了跳跃连接,这是一种很好的方法,可以在我们解码或将层提升到原始大小时保留前一层的一些更精细的细节。在前面,我们讨论了实现此目的的一种方法,即使用元素添加操作添加两个层。我们现在将学习另一个简单的技术,我们将连接两个层,而不是添加它们。
连接两个层,上采样层和一个比上采样层具有更多空间信息的层,向我们展示了相同的功能。实现此功能也非常简单。
使用tf.contrib.keras函数定义,它可以实现如下:
from tensorflow.contrib.keras.python.keras import layers
output = layers.concatenate(inputs)
其中,
inputs 是要连接的图层的列表。
可以使用类似的格式在decoder_block()函数中实现上述操作:
output = layers.concatenate([input_layer_1, input_layer_2])
层级联的另一个好处是,它提供了一定的灵活性,因为与必须添加它们时不同,输入层的深度不需要匹配。这也有助于简化实施。
虽然层级联本身对模型有帮助,但通常最好在此步骤之后添加一些常规或可分离的卷积层,以使模型能够更好地从之前的图层中学习那些更精细的空间细节。
3. 交并比(IoU)
交并比(IoU)是一个重要的指标,该指标可以帮助评估语义分割网络的性能。
IoU函数的定义为:预测边界和实际边界 交集的面积 比 并集的面积。
I n t e r s e c t i o n S e t ( A N D ) U n i o n S e t ( O R ) ≤ 1 \frac{Intersection \ Set(AND)}{Union\ Set(OR)} \le 1 Union Set(OR)Intersection Set(AND)≤1
TensorFlow IoU
让我们看一下tf.metrics.mean_iou函数。与所有其他TensorFlow度量函数一样,它返回度量结果的Tensor和Tensor Operation来生成结果。在这种情况下,它将返回mean_iou结果和update_op更新操作。确保update_op从获得结果之前运行mean_iou。
sess.run(update_op)
sess.run(mean_iou)
TensorFlow度量函数的另一个特征 是使用本地TensorFlow变量。这些是临时TensorFlow变量,必须通过运行进行初始化 tf.local_variables_initializer()。这类似于tf.global_variables_initializer(),但针对不同的TensorFlow变量。
程序如下:
import tensorflow as tf
def mean_iou(ground_truth, prediction, num_classes):
iou, iou_op = tf.metrics.mean_iou(ground_truth, prediction, num_classes)
return iou, iou_op
ground_truth = tf.constant([
[0, 0, 0, 0],
[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]], dtype=tf.float32)
prediction = tf.constant([
[0, 0, 0, 0],
[1, 0, 0, 1],
[1, 2, 2, 1],
[3, 3, 0, 3]], dtype=tf.float32)
iou, iou_op = mean_iou(ground_truth, prediction, 4)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 需要初始化本地变量来运行' tf.metrics.mean_iou '
sess.run(tf.local_variables_initializer())
sess.run(iou_op)
# should be 0.53869
print("Mean IoU =", sess.run(iou))
程序注释:
tf.metrics.mean_iou(
labels,
predictions,
num_classes,
weights=None,
metrics_collections=None,
updates_collections=None,
name=None
)
labels:一个Tensor地面实况的具有形状[批量大小]和类型的标签int32或int64。如果张量等级> 1,则张量将被展平。predictions:Tensor语义标签的预测结果A ,其形状为[批量大小]且类型为int32或int64。如果张量等级> 1,则张量将被展平。num_classes:预测任务可以具有的标签数量。必须提供此值,因为将分配维度= [num_classes,num_classes]的混淆矩阵。weights:Tensor等级为0或与等级相同的 可选labels,并且必须向广播labels(即,所有尺寸必须为1,或与相应labels尺寸相同)。metrics_collections:mean_iou 应添加到集合的可选列表。updates_collections:update_op应该添加可选的收藏列表。name:可选的variable_scope名称。
4.语义分割实例
我们将建立一个深度学习网络,定位一个特定的人类目标在一个图像里。前提是一个四轴飞行器(模拟)正在寻找一个目标,然后一旦找到目标就会跟随。在这种情况下,仅仅说目标出现在图像中是不够的,而是要知道目标在图像中的位置,以便直升机可以调整其方向以便跟踪。
因此,一个图像分类网络不足以解决这个问题。相反,需要一个语义分割网络,以便目标可以被明确地定位在图像中。
猜测是tensorflow版本的问题,程序频繁报错,查了一天错之后也没有实质性的进展,因此将tensorflow版本更改到与推荐的版本一致。
pip install tensorflow==1.2.1
(1)引入函数
import os
import glob
import sys
import tensorflow as tf
from scipy import misc
import numpy as np
from tensorflow.contrib.keras.python import keras
from tensorflow.contrib.keras.python.keras import layers, models
from tensorflow import image
from utils import scoring_utils
# 引入可分卷积函数
from utils.separable_conv2d import SeparableConv2DKeras, BilinearUpSampling2D
from utils import data_iterator
from utils import plotting_tools
from utils import model_tools
来自utils的六个文件是课程自带的,之前使用tensorflow1.13.0的时候,程序不停的出错。个人猜测是因为升级后的tensorflow的各个函数的位置更改造成的。这个问题确实很遭人心,函数的位置的更改,导致了对以后程序的复现难度上升。而且出一些很玄学的bug。
(2)FCN层
可分卷积函数:
def separable_conv2d_batchnorm(input_layer, filters, strides=1):
output_layer = SeparableConv2DKeras(filters=filters,kernel_size=3, strides=strides,
padding='same', activation='relu')(input_layer)
output_layer = layers.BatchNormalization()(output_layer)
return output_layer
常规卷积函数:
def conv2d_batchnorm(input_layer, filters, kernel_size=3, strides=1):
output_layer = layers.Conv2D(filters=filters, kernel_size=kernel_size, strides=strides,
padding='same', activation='relu')(input_layer)
output_layer = layers.BatchNormalization()(output_layer)
return output_layer
这两种卷积都可以使用,正如之前提到的,但是可分卷积函数在训练的时候速度较快。在tensorflow==1.13.0中,separable_conv2d_batchnorm函数一直会报错如下:
TypeError: __call__() got an unexpected keyword argument 'partition_info'
大量的尝试后,这个错误还是不能规避掉。个人猜测是因为tensorflow的版本冲突。果然在退回了版本和引入keras的位置后,程序正常运行。
def bilinear_upsample(input_layer):
output_layer = BilinearUpSampling2D((2,2))(input_layer)
return output_layer
双线性上采样也是另一个bug出现的地方,这个bug的原因是在后面的layerc.concatenate函数中,两层的shape不匹配。但是比较玄学的是,当我将它们print出来之后,两者的shape完全一样,但是根据报的错误来显示,双线性上采样完全没有起作用,输出维度和采样之前完全一样。
这个错误最终我也没有解决掉,猜测和上面的可分卷积函数出现的错误一样。因为这两者都采用了utils中的辅助函数SeparableConv2DKeras,这也很好的提醒了我,对于函数的使用,尤其是在tensorflow中,一定要注意版本的问题。
# 编码器模块
def encoder_block(input_layer, filters, strides):
# TODO Create a separable convolution layer using the separable_conv2d_batchnorm() function.
output_layer = separable_conv2d_batchnorm(input_layer, filters, strides)
return output_layer
# 解码器模块
def decoder_block(small_ip_layer, large_ip_layer, filters):
# TODO Upsample the small input layer using the bilinear_upsample() function.
upsampled = bilinear_upsample(small_ip_layer)
print('upsampled_shape:', upsampled.shape)
print('large_input_shape:', large_ip_layer.shape)
# TODO Concatenate the upsampled and large input layers using layers.concatenate
concat_layer = layers.concatenate([upsampled, large_ip_layer])
print('concat_layer_shape:', concat_layer.shape)
# TODO Add some number of separable convolution layers
output_layer = separable_conv2d_batchnorm(concat_layer, filters)
return output_layer
之后我们就可以将上采样和可分卷积整合到编码器和解码器之中了。
(3)建立模型
# 构建FCN模型
def fcn_model(inputs, num_classes):
# TODO Add Encoder Blocks.
# Remember that with each encoder layer, the depth of your model (the number of filters) increases.
# TODO 添加编码器模块。
# 请记住,对于每个编码器层,模型的深度(过滤器的数量)都会增加。
mid_layer_0 = encoder_block(inputs, filters=32, strides=2)
print('mid_layer_0:', mid_layer_0)
# TODO 使用conv2d_batchnorm()添加1x1卷积层。
mid_layer_1 = conv2d_batchnorm(mid_layer_0, 32, 3, 1)
print('mid_layer_1:', mid_layer_1)
# TODO: 添加与编码器块数量相同的解码器块数量
x = decoder_block(mid_layer_1, inputs, 32)
# 该函数返回模型的输出层。“x”是从最后一个decoder_block()中获得的最后一层
return layers.Conv2D(num_classes, 3, activation='softmax', padding='same')(x)
再有了上采样和可分卷积之后,我们就可以搭建我们的FCN模型

(4)训练
# 输入图片宽度
image_hw = 128
# 输入图片shape
image_shape = (image_hw, image_hw, 3)
inputs = layers.Input(image_shape)
num_classes = 3
# Call fcn_model()
output_layer = fcn_model(inputs, num_classes)
建立完整的模型,有了模型之后我们就可以使用keras进行训练了。
learning_rate = 0.001 # 学习率
batch_size = 32 # 批大小
num_epochs = 5 # 训练轮数
steps_per_epoch = 200 # 每轮训练步数
validation_steps = 50 # 验证部署
workers = 2 # 最多启动的进程数
定义一些超参数,解释如上。
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
# Define the Keras model and compile it for training
model = models.Model(inputs=inputs, outputs=output_layer)
model.compile(optimizer=keras.optimizers.Adam(learning_rate), loss='categorical_crossentropy')
# Data iterators for loading the training and validation data
train_iter = data_iterator.BatchIteratorSimple(batch_size=batch_size,
data_folder=os.path.join('..', 'data', 'train'),
image_shape=image_shape,
shift_aug=True)
val_iter = data_iterator.BatchIteratorSimple(batch_size=batch_size,
data_folder=os.path.join('..', 'data', 'validation'),
image_shape=image_shape)
logger_cb = plotting_tools.LoggerPlotter()
callbacks = [logger_cb]
model.fit_generator(train_iter,
steps_per_epoch = steps_per_epoch, # the number of batches per epoch,
epochs = num_epochs, # the number of epochs to train for,
validation_data = val_iter, # validation iterator
validation_steps = validation_steps, # the number of batches to validate on
callbacks=callbacks,
workers = workers)
使用keras训练自定义的模型。
完整程序如下,其中还包括了验证和预测部分:
import os
import glob
import sys
import tensorflow as tf
from scipy import misc
import numpy as np
from tensorflow.contrib.keras.python import keras
from tensorflow.contrib.keras.python.keras import layers, models
from tensorflow import image
from utils import scoring_utils
# 引入可分卷积函数
from utils.separable_conv2d import SeparableConv2DKeras, BilinearUpSampling2D
from utils import data_iterator
from utils import plotting_tools
from utils import model_tools
# # 两种方法构建编码器
# 使用可分卷积构建编码器
def separable_conv2d_batchnorm(input_layer, filters, strides=1):
output_layer = SeparableConv2DKeras(filters=filters, kernel_size=3, strides=strides,
padding='same', activation='relu')(input_layer)
output_layer = layers.BatchNormalization()(output_layer)
return output_layer
# 使用常规卷积构建编码器
def conv2d_batchnorm(input_layer, filters, kernel_size=3, strides=1):
output_layer = layers.Conv2D(filters=filters, kernel_size=kernel_size, strides=strides,
padding='same', activation='relu')(input_layer)
output_layer = layers.BatchNormalization()(output_layer)
return output_layer
# # 构建上采样函数
# 使用双线性上采样
def bilinear_upsample(input_layer):
output_layer = BilinearUpSampling2D((2,2))(input_layer)
return output_layer
# # 建立模型
# 使用separable_conv2d_batchnorm()函数创建一个可分离的卷积层。
# 该filters参数定义输出层的大小或深度。例如32或64。
def encoder_block(input_layer, filters, strides):
# TODO Create a separable convolution layer using the separable_conv2d_batchnorm() function.
output_layer = separable_conv2d_batchnorm(input_layer, filters, strides)
return output_layer
# 解码器模块
def decoder_block(small_ip_layer, large_ip_layer, filters):
# TODO Upsample the small input layer using the bilinear_upsample() function.
upsampled = bilinear_upsample(small_ip_layer)
print('upsampled_shape:', upsampled.shape)
print('large_input_shape:', large_ip_layer.shape)
# TODO Concatenate the upsampled and large input layers using layers.concatenate
concat_layer = layers.concatenate([upsampled, large_ip_layer])
print('concat_layer_shape:', concat_layer.shape)
# TODO Add some number of separable convolution layers
output_layer = separable_conv2d_batchnorm(concat_layer, filters)
return output_layer
# 构建FCN模型
def fcn_model(inputs, num_classes):
# TODO Add Encoder Blocks.
# Remember that with each encoder layer, the depth of your model (the number of filters) increases.
# TODO 添加编码器模块。
# 请记住,对于每个编码器层,模型的深度(过滤器的数量)都会增加。
mid_layer_0 = encoder_block(inputs, filters=32, strides=2)
print('mid_layer_0:', mid_layer_0)
# TODO 使用conv2d_batchnorm()添加1x1卷积层。
mid_layer_1 = conv2d_batchnorm(mid_layer_0, 32, 3, 1)
print('mid_layer_1:', mid_layer_1)
# TODO: 添加与编码器块数量相同的解码器块数量
x = decoder_block(mid_layer_1, inputs, 32)
# 该函数返回模型的输出层。“x”是从最后一个decoder_block()中获得的最后一层
return layers.Conv2D(num_classes, 3, activation='softmax', padding='same')(x)
# # 训练
# 以下单元格将利用您创建的模型并根据输入和类数定义输出层,随后将定义用于编译和训练模型的超参数
image_hw = 128
image_shape = (image_hw, image_hw, 3)
inputs = layers.Input(image_shape)
num_classes = 3
# Call fcn_model()
output_layer = fcn_model(inputs, num_classes)
# 定义超参数。
#
# batch_size:一次通过网络传播的训练样本/图像的数量。
# num_epochs:整个训练数据集通过网络传播的次数。
# steps_per_epoch:在1个时期内通过网络的训练图像的批次数。一种建议值是基于训练数据集中的图片总数除以batch_size。
# validation_steps:在1个时期内通过网络的验证图像的批数。这与steps_per_epoch相似,只不过validation_steps用于验证数据集。这里提供了默认值。
# worker:最多启动的进程数。这会影响训练速度,并取决于硬件配置。
learning_rate = 0.001
batch_size = 32
num_epochs = 2
steps_per_epoch = 200
validation_steps = 50
workers = 8
"""
DON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE
"""
# Define the Keras model and compile it for training
model = models.Model(inputs=inputs, outputs=output_layer)
model.compile(optimizer=keras.optimizers.Adam(learning_rate), loss='categorical_crossentropy')
# Data iterators for loading the training and validation data
train_iter = data_iterator.BatchIteratorSimple(batch_size=batch_size,
data_folder=os.path.join('..', 'data', 'train'),
image_shape=image_shape,
shift_aug=True)
val_iter = data_iterator.BatchIteratorSimple(batch_size=batch_size,
data_folder=os.path.join('..', 'data', 'validation'),
image_shape=image_shape)
logger_cb = plotting_tools.LoggerPlotter()
callbacks = [logger_cb]
model.fit_generator(train_iter,
steps_per_epoch = steps_per_epoch, # the number of batches per epoch,
epochs = num_epochs, # the number of epochs to train for,
validation_data = val_iter, # validation iterator
validation_steps = validation_steps, # the number of batches to validate on
callbacks=callbacks,
workers = workers)
# Save your trained model weights
weight_file_name = 'model_weights'
model_tools.save_network(model, weight_file_name)
run_number = 'run1'
validation_path, output_path = model_tools.write_predictions_grade_set(model,run_number,'validation')
im_files = plotting_tools.get_im_file_sample(run_number,validation_path)
for i in range(3):
im_tuple = plotting_tools.load_images(im_files[i])
plotting_tools.show_images(im_tuple)
scoring_utils.score_run(validation_path, output_path)
input_shape: (?, 128, 128, 3)
encoder_shape: (?, 32, 32, 64)
1x1_shape: (?, 32, 32, 128)
upsampled_shape: (?, 64, 64, 128)
large_input_shape: (?, 64, 64, 32)
concat_layer_shape: (?, 64, 64, 160)
upsampled_shape: (?, 128, 128, 64)
large_input_shape: (?, 128, 128, 3)
concat_layer_shape: (?, 128, 128, 67)
output_shape: Tensor("batch_normalization_5/batchnorm/add_1:0", shape=(?, 128, 128, 32), dtype=float32)
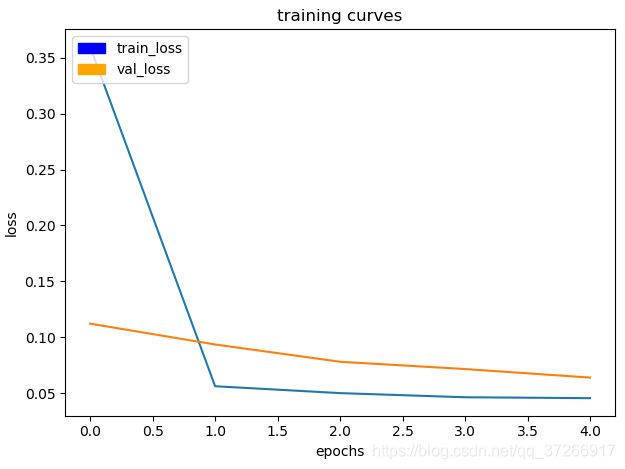
Epoch 1/2
200/200 [==============================] - 823s - loss: 0.3584 - val_loss: 0.1122
Epoch 2/5
200/200 [==============================] - 836s - loss: 0.0561 - val_loss: 0.0936
Epoch 3/5
200/200 [==============================] - 833s - loss: 0.0501 - val_loss: 0.0782
Epoch 4/5
200/200 [==============================] - 925s - loss: 0.0465 - val_loss: 0.0716
Epoch 5/5
200/200 [==============================] - 829s - loss: 0.0456 - val_loss: 0.0640
(5)预测
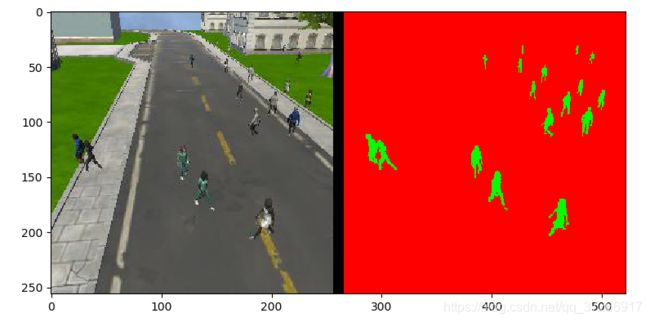
以上是给出的某张验证图像。

这张是经过训练后的模型的输出,可以看出模型大致可以分出轮廓。
(6)评价
number of validation samples intersection over the union evaulated on 1184
average intersection over union for background is 0.9858371822735106
average intersection over union for other people is 0.14932455085825228
average intersection over union for hero is 0.0684055264892006
global average intersection over union is 0.40118908654032115
综合来看,这个模型的正确率还是很低的,因为模型比较简单,可以选择增加模型深度来获取更好的输出,在这里我因为时间关系,只能简单的构建模型然后训练了。