redis Cluster集群(3.2.10版本)三主三从,五主五从集群搭建
Redis Cluster高可用支持root用户安装,也支持非root用户安装,安装和启动方法一致
redis-cluster-3.2.10版本百度云链接:https://pan.baidu.com/s/1tncis5ZsqihtGmeyfaN7CQ
提取码:0njl
Redis非root用户安装,home目录下创建一个用户test01
[root@localhost home]# useradd test01
[root@localhost home]# passwd test01
将redis_cluster.zip包传到/home/test01/redis目录下,并且解压安装包
unzip reddis_cluster.zip
然后修改你所有的redis-xxx.conf文件
内容主要有bind,port,dir ,如下图,下图修改的是redis-9000.conf,如果还有9001,9002,9003就依次在每个conf文件中修改即可
| #redis-9000.conf pidfile /home/test01/redis/data/redis-9000.pid port 9000 bind 172.31.223.35 unixsocket /home/test01/redis/data/redis-9000.sock logfile /home/test01/redis/log/redis-9000.log dbfilename dump-9000.rdb dir /home/test01/redis/data masterauth test --test是密码,有就写没有就空着不写 requirepass test --test是密码,有就写没有就空着不写 appendfilename "appendonly-9000.aof" cluster-config-file /home/test01/redis/data/nodes-9000.conf |
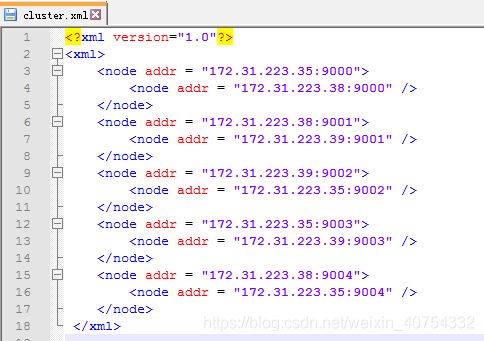
- cluster.xml文件nodepad打开,配置好主节点和从节点及端口号,上传到/home/test01/redis/bin目录下
,注意每个redis-xxx.conf中配置都需要修改,修改成自己对应的配置端口和统一路径和密码
- 按照下面的方法启动redis,进入/home/test01/redis/bin目录下
注意把每个redis-xxx.conf都上传到指定的服务器上然后还需要在自己对应ip服务器上进行重新重启
chmod +x *
./redis-server ../cfg/redis-9000.conf
./redis-server ../cfg/redis-9001.conf
./redis-server ../cfg/redis-9002.conf
./redis-server ../cfg/redis-9003.conf
./redis-server ../cfg/redis-9004.conf
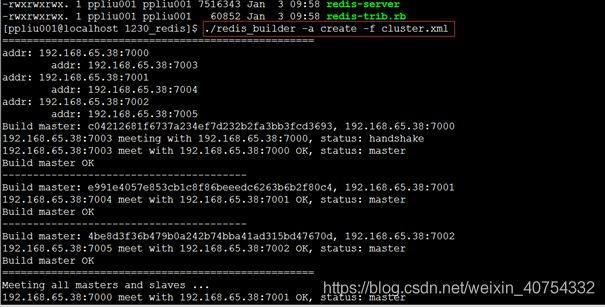
建立集群,进入/home/test01/redis/bin目录下
./redis_builder -a create -f cluster.xml -p test 在某一台redis服务器上执行就行test是密码,如果没有密码可不写
免编译redis 非root用户安装启动方法与root用户安装启动方法一样。
- Redis高可用部署参考
Redis的高可用部署方式比较灵活,redis集群主从节点可以是一对一的方式,也可以是1个主节点对应多个从节点,这里以五主五从部署在3台服务器上为例,可以实现一台服务器挂掉或者 由于redis的主从节点是相对应的 测试场景设置redis集群主节点:A、B、C、D、E,从节点:A1、B1、C1、D1、E1,测试机器3台,节点5主5从,具体分配如下 机器A A1 C D E1 机器B B1 E D1 机器C A B C1 高可用方案部署 1、由于redis集群主从节点是相对应的,一对对应的主从节点挂掉,整个redis集群服务即不可用,所以部署建议redis主从节点部署,主节点和其对应的从节点不要部署在同一台服务器上(防止1台机器挂掉导致整个redis集群不能使用) 2、当一台机器的主节点小于N/2(N为redis主节点个数),这台机器挂掉,这台机器主节点对应在另一台机器上的从节点会变成主节点;这台挂掉的机器的redis服务重启后,这台机器上原来的主节点变为从节点,原来的从节点还是从节点,主从节点对并不会还原重机器挂掉前的样子 3、当一台机器的主节点大于N/2(N为redis主节点个数),这台机器挂掉,整个redis集群状态显示failed,所以部署在一台服务器上的主节点尽量小于N/2 4、redis集群的主从节点对是不变的,所谓的漂移只是主节点对中主节点变为从节点,从节点变为主节点,节点对和节点对之间不会有漂移 根据cluster info和cluster nodes指令查询redis集群是否正常 使用命令,查看集群信息: ./redis_builder -s 172.31.223.35:9000 -a nodes -p test 集群测试: 使用redis客户端redis-cli进行添加数据操作。到/home/test01/redis/bin下 $ ./redis-cli -c -h 172.31.223.35 -p 9000 -a 密码 --raw 172.31.223.14:9000> set zs 张三 OK 192.168.77.127:9002> get zs "\xd3\xba\xcd\xf2\xd2\xf8" $ ./redis-cli -c -h 172.31.223.38 -p 9000 -a test --raw #--raw参数可get出keys的文本不会出现乱码 192.168.77.127:9000> get zs "\xd3\xba\xcd\xf2\xd2\xf8" --加raw能显示具体文本 1、手动配置shell脚本stat_redis.sh #!/bin/sh ### BEGIN INIT INFO # Provides: test.sh # Required-Start: $local_fs $remote_fs $network $syslog # Required-Stop: $local_fs $remote_fs $network $syslog # Default-Start: 2 3 4 5 # Default-Stop: 0 1 6 # Short-Description: starts the php_fastcgi daemon # Description: starts php_fastcgi using start-stop-daemon ### END INIT INFO /home/test01/redis/bin/redis-server /home/test01/redis/cfg/redis-9000.conf //配置redis绝对路径 /home/test01/redis/bin/redis-server /home/test01/redis/cfg/redis-9001.conf //配置redis绝对路径 /home/test01/redis/bin/redis-server /home/test01/redis/cfg/redis-9002.conf //配置redis绝对路径 /home/test01/redis/bin/redis-server /home/test01/redis/cfg/redis-9003.conf //配置redis绝对路径 /home/test01/redis/bin/redis-server /home/test01/redis/cfg/redis-9004.conf //配置redis绝对路径 /home/test01/redis/bin/redis-server /home/test01/redis/cfg/redis-9005.conf //配置redis绝对路径 将stat_redis.sh脚本上传到/etc/init.d下面,设置开机自启动 chkconfig --list start_redis.sh chkconfig start_redis.sh on 执行上面命令遇到以下报错,执行下一条命令即可解决 insserv -v -d /etc/init.d/start_redis.sh 注意事项: 1、Redis集群节点异常重启或者所在服务器重启后,redis被自动拉起后,最好清一下redis中脏数据 登录redis客户端,然后用flushdb,flushall命令清除redis中的数据 ./redis-cli -c -h 172.31.3.82 -p 7000 --raw #用--raw参数get时能查看文本内容 flushdb flushall 2、对于redis若操作flushdb、flushall和重启redis操作的有以下的约束条件: (1)、在操作前,保证没有用户使用鉴权,等待3分钟,确保所有的用户心跳都被处理,实时授权量回到初值; (2)、在操作后的5分钟内,鉴权功能同样不能使用,并且不能通过页面修改授权量上限,确保授权量恢复 Redis Cluster设计要点: 架构:无中心 Redis Cluster采用无中心结构,每个节点都保存数据和整个集群的状态 数据分布:预分桶 预分好16384个桶,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中 可用性:Master-Slave 为了保证服务的可用性,Redis Cluster采取的方案是的Master-Slave 写操作 Redis Cluster使用异步复制 数据迁移 Redis Cluster支持在线增/减节点。 多key操作 当系统从单节点向多节点扩展时,多key的操作总是一个非常难解决的问题,Redis Cluster方案如下: 2. 如果一定要使用多key操作,请确保所有的key都在一个node上,具体方法是使用“hash tag”方案 Redis主从配置(Master-Slave) 三、 redis 主从同步配置 下面是我使用的配置,使用主从模式,在master上关掉所有持久化,在slave上使用dba持久化: ###Master config ###General 配置 daemonize yes #使用daemon 方式运行程序,默认为非daemon方式运行 pidfile /tmp/redis.pid #pid文件位置 port 6379 #使用默认端口 timeout 300 # client 端空闲断开连接的时间 loglevel warning #日志记录级别,默认是notice,我这边使用warning,是为了监控日志方便。使用warning后,只有发生告警才会产生日志,这对于通过判断日志文件是否为空来监控报警非常方便。 logfile /opt/logs/redis/redis.log #日志产生的位置 databases 16 #默认是0,也就是只用1 个db,我这边设置成16,方便多个应用使用同一个redis server。使用select n 命令可以确认使用的redis db ,这样不同的应用即使使用相同的key也不会有问题。 ###下面是SNAPSHOTTING持久化方式的策略。为了保证数据相对安全,在下面的设置中,更改越频繁,SNAPSHOTTING越频繁,也就是说,压力越大,反而花在持久化上的资源会越多。所以我选择了master-slave模式,并在master关掉了SNAPSHOTTING。 #save 900 1 #在900秒之内,redis至少发生1次修改则redis抓快照到磁盘 #save 300 100 #在300秒之内,redis至少发生100次修改则redis抓快照到磁盘 #save 60 10000 #在60秒之内,redis至少发生10000次修改则redis抓快照到磁盘 rdbcompression yes #使用压缩 dbfilename dump.rdb #SNAPSHOTTING的文件名 dir /opt/data/redis/ #SNAPSHOTTING文件的路径 ###REPLICATION 设置, #slaveof #slave-serve-stale-data yes #如果slave 无法与master 同步,是否还可以读 ### SECURITY 设置 #requirepass iflytek #redis性能太好,用个passwd 意义不大 #rename-command FLUSHALL "" #可以用这种方式关掉非常危险的命令,如FLUSHALL这个命令,它清空整个 Redis 服务器的数据,而且不用确认且从不会失败 ###LIMIT 设置 maxclients 0 #无client连接数量限制 maxmemory 15032385536 #redis最大可使用的内存量,我的服务器内存是16G,如果使用redis SNAPSHOTTING的copy-on-write的持久会写方式,会额外的使用内存,为了使持久会操作不会使用系统VM,使redis服务器性能下降,建议保留redis最大使用内存的一半8G来留给持久化使用,我个人觉得非常浪费。我没有在master上不做持久化,使用主从方式 maxmemory-policy volatile-lru #使用LRU算法删除设置了过期时间的key,但如果程序写的时间没有写key的过期时间,建议使用allkeys-lru,这样至少保证redis不会不可写入。 ###APPEND ONLY MODE 设置 appendonly no #不使用AOF,AOF是另一种持久化方式,我没有使用的原因是这种方式并不能在服务器或磁盘损坏的情况下,保证数据可用性。 appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb ###SLOW LOG 设置 slowlog-log-slower-than 10000 #如果操作时间大于0.001秒,记录slow log,这个log是记录在内存中的,可以用redis-cli slowlog get 命令查看 slowlog-max-len 1024 #slow log 的最大长度 ###VIRTUAL MEMORY 设置 vm-enabled no #不使用虚拟内存,在redis 2.4版本,作者已经非常不建议使用VM。 vm-swap-file /tmp/redis.swap vm-max-memory 0 vm-page-size 32 vm-pages 134217728 vm-max-threads 4 ###ADVANCED CONFIG 设置,下面的设置主要是用来节省内存的,我没有对它们做修改 hash-max-zipmap-entries 512 hash-max-zipmap-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 activerehashing yes ###INCLUDES 设置 ,使用下面的配置,可以配置一些个另其它的设置,如slave的配置 #include /path/to/local.conf #include /path/to/other.conf #include /opt/redis/etc/slave.conf 如果是slave server,把这个注释打开 slave 配置: ###slave config ###REPLICATION 设置, slaveof 192.168.xx.xx 6397 # 打开这个设置,修改成master的ip和端口。如果使用master-slave模式,我就会在master上把SNAPSHOTTING关了,这样可以不用在master上做持久化,而是在slave上做,这样可以大大提高master 内存使用率和系统性能。 slave-serve-stale-data no #如果slave 无法与master 同步,设置成slave不可读,方便监控脚本发现问题。 ###下面是SNAPSHOTTING持久化方式的策略。为了保证数据相对安全,在下面的设置中,更改越频繁,SNAPSHOTTING越频繁,也就是说,压力越大,反而花在持久化上的资源会越多。所以我选择了master-slave模式,并在master关掉了SNAPSHOTTING。只需在slave上开启。 save 900 1 #在900秒之内,redis至少发生1次修改则redis抓快照到磁盘 save 300 100 #在300秒之内,redis至少发生100次修改则redis抓快照到磁盘 save 60 10000 #在60秒之内,redis至少发生10000次修改则redis抓快照到磁盘 rdbcompression yes #使用压缩 dbfilename dump.rdb #SNAPSHOTTING的文件名 dir /opt/data/redis/ #SNAPSHOTTING文件的路径 四、测试: 2:数据测试
insserv: warning: script 'start_redis.sh' missing LSB tags and overrides
insserv: warning: script 'start_redis.sh ' missing LSB tags and overrides
insserv: warning: script ' start_redis.sh ' missing LSB tags and overrides
insserv: warning: current start runlevel(s) (empty) of script `start_redis.sh ' overwrites defaults (2 3 4 5).
insserv: warning: current stop runlevel(s) (0) of script ` start_redis.sh ' overwrites defaults (0 1 6).
insserv: dryrun, not creating .depend.boot, .depend.start, and .depend.stop
每个节点都和其他所有节点连接,这些连接保持活跃
使用gossip协议传播信息以及发现新节点
node不作为client请求的代理,client根据node返回的错误信息重定向请求
每个Redis物理结点负责一部分桶的管理,当发生Redis节点的增减时,调整桶的分布即可
例如,假设Redis Cluster三个节点A/B/C,则
Node A 包含桶的编号可以为: 0 到 5500.
Node B 包含桶的编号可以为: 5500 到 11000.
Node C包含桶的编号可以为: 11001 到 16384.
当发生Redis节点的增减时,调整桶的分布即可。
预分桶的方案介于“硬Hash”和“一致性Hash”之间,牺牲了一定的灵活性,但相比“一致性Hash“,数据的管理成本大大降低。
每个Redis Node可以有一个或者多个Slave。当Master挂掉时,选举一个Slave形成新的Master
一个Redis Node包含一定量的桶,当这些桶对应的Master和Slave都挂掉时,这部分桶对应的数据不可用。
一个完整的写操作步骤:
1.client写数据到master
2.master告诉client "ok"
3.master传播更新到slave
存在数据丢失的风险:
1. 上述写步骤1)和2)成功后,master crash,而此时数据还没有传播到slave
2. 由于分区导致同时存在两个master,client向旧的master写入了数据。
当然,由于Redis Cluster存在超时及故障恢复机制,第2个风险基本上不可能发生
基于桶的数据分布方式大大降低了迁移成本,只需将数据桶从一个Redis Node迁移到另一个Redis Node即可完成迁移。
当桶从一个Node A向另一个Node B迁移时,Node A和Node B都会有这个桶,Node A上桶的状态设置为MIGRATING,Node B上桶的状态被设置为IMPORTING
当客户端请求时:
所有在Node A上的请求都将由A来处理,所有不在A上的key都由Node B来处理。同时,Node A上将不会创建新的key
1. 不支持多key操作
hash tag方案是一种数据分布的例外情况
一、 Redis Replication的特点:
1):一个Master可以同步多个Slave
2):不仅Master可以同步多个Slave,Slave也可以同步其它Slave,可以构成一个图形结构,同时还能分担Master的同步压力
3):Redis Replication使用的是异步复制。从2.8开始,Slave会周期性发起一个Ack确认replication stream被处理进度
4):复制在Master Server是以非阻塞模式完成数据同步。即使多个Master-Slave同时同步,Master Server仍然可以提供查询或修改
5):复制在Slave Server也是以非阻塞的方式完成数据同步。在同步期间,Slave Server可以提供数据查询,但返回的是同步之前的数据,同时还能配置当Master与Slave失去联系时,让Slave返回客户端一个错误提示
6):Slave Server可以为客户端提供只读操作的服务,但写服务仍然必须由Master来完成,这样可以分载Master的读操作压力,在分压的同时还供了数据冗余,同时还可以通过增加Slave进行只读操作来提升扩展性
7):可以通过修改Master Server的redis.config配置文件来将持久化操作交给Slave Server去操作
注:Slave是只读的,只可以读取数据,而不能写入数据
二、Redis Replication工作原理:
1):Slave启动后,无论是第一次连接还是重连到Master,它都会主动发出一个SYNC命令
2):当Master收到SYNC命令之后,将会执行BGSAVE(后台存盘进程),即在后台保存数据到磁盘(rdb快照文件),同时收集所有新收到的写入和修改数据集的命令存入缓冲区(非查询类)
3):Master在后台把数据保存到快照文件完成后,会传送整个数据库文件到Slave
4):Slave接收到数据库文件后,会把内存清空,然后加载该文件到内存中以完成一次完全同步
5):然后Master会把之前收集到缓冲区中的命令和新的修改命令依次传送给Slave
6):Slave接受到之后在本地执行这些数据修改命令,从而达到最终的数据同步
7):之后Master与Slave之间将会不断的通过异步方式进行命令的同步,从而保证数据的时时同步
8):如果Master和Slave之间的链接出现断连,Slave可以自动重连Master。根据版本的不同,断连后同步的方式也不同:
2.8之前:重连成功之后,一次全量同步操作将被自动执行
2.8之后:重连成功之后,进行部分同步操作
$cat /opt/redis/etc/redis.conf
$cat /opt/redis/etc/slave.conf
1:在命令行界面进行查看(以上两个节点):
# /main/redis/src/redis-cli
127.0.0.1:6379> info replication
节点1显示如下(master):
# Replication
role:master //主节点
connected_slaves:1
slave0:ip=192.168.xx.xx,port=6379,state=online,offset=41663,lag=1
master_repl_offset:41963
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:41962
节点2显示如下(slave1):
# Replication
role:slave //从节点
master_host:192.168.xx.xx
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:41520
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
Master
# /main/redis/src/redis-cli set hello doiido
Slave
# /main/redis/src/redis-cli get hello
"doiido"