5. 强化学习之——策略优化
课程大纲
基于策略的强化学习:前面讲的都是基于价值的强化学习,这次讲基于策略函数去优化的强化学习
蒙特卡罗策略梯度
如何降低策略梯度的方差
Actor-Critic:同时学习策略函数和价值函数
基于策略的强化学习基础知识
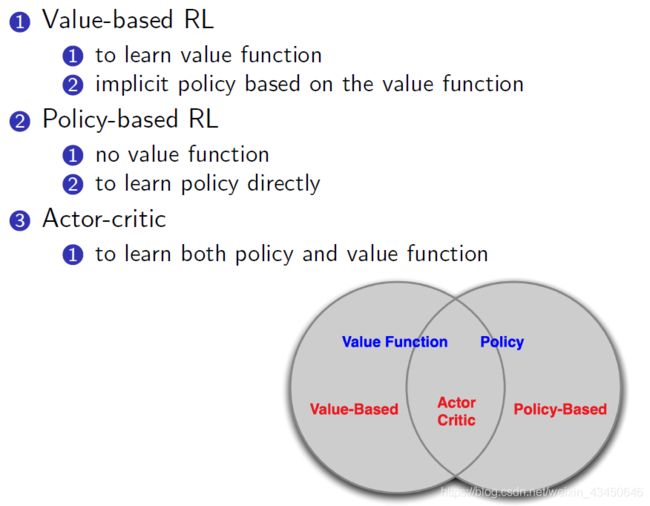
Value-based RL 与 Policy-based RL:
Policy-based RL 的优势与劣势:

策略的分类:
(1)确定性策略
(2)概率分布性策略
对策略进行优化的过程中,优化目标是什么?
给定一个带参数的策略逼近函数(类似于值函数逼近)![]() ,我们就是要找到最优的
,我们就是要找到最优的 
怎么去评价一个策略  呢?【废话,当然是用值函数啊】
呢?【废话,当然是用值函数啊】
从环境的角度去看:
(1)对于 episodic 的环境:可以用最开始的那个 value
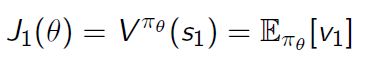
(2)对于 continuing 环境:可以用平均的 value;也可以用平均的 reward

从轨迹的角度去看:

怎么去优化我们的目标方程  呢?
呢?
(1)当目标方程 是可微的时候【我们更倾向于这样】

(2)当目标方程 是不可微的时候 (采用不用求微分的黑箱优化方法)

举例:
黑箱优化方法A:交叉熵方法 Cross Entropy Method

黑箱优化方法B:有限差分法 Finite Difference Method

策略函数的形式可以是怎么样的呢?
(1)Softmax Policy

(2)Gaussian Policy:适用于连续的动作变量

蒙特卡罗策略梯度方法
一步 MDP 的策略梯度(Policy Gradient for One-Step MDPs)

多步 MDP 的策略梯度(Policy Gradient for Multi-Step MDPs)——真实存在的MDP
优化目标是:

怎么去算梯度呢?—— 注意这里的 log 小技巧,把连乘变成加和的形式

算完梯度之后:(第二步中用 MC 去采样很多轨迹来近似导数)

那为什么把那个 τ 放到 log 里面呢?
答:分解那个 log 变成连加的形式,可以消掉无关项,最后只剩下那个 score function

之后我们就有了 likelihood ratio policy gradient:【整个过程我们并不需要知道状态转移函数】

整个推导过程就让求梯度变成加和的形式,例如10条轨迹,就把10条轨迹上的奖励加和加起来,对于每一步也有 score function(就是 likelihood function 取个梯度) 也是加和起来,然后就直接得到了客观函数的梯度,整个过程我们并不需要知道状态转移函数,这也是 policy gradient 的一个特殊之处
如何降低 policy gradient 的方差 variance【改进策略梯度】
Score Function Gradient Estimator:近似我们的客观函数的梯度,通过采样 S 个来求平均

Policy Gradient Estimator 和 Maximum Likelihood Estimator 的区别:
唯一的区别是那个 reward function,这样来看的话,策略梯度估计就类似于加权后的极大似然估计

问题来了:我们的策略梯度是依据于 MC 采样产生的,虽然是无偏的,但是说方差比较大

三种减小方差的解决方案:
(1)引入时序上的因果关系,去掉不必要的项来减小方差


上面的这种方法就叫 REINFORCE 方法【William 提出于1992年】

(2)包含一个 baseline 项来减小方差

下面是 baseline 的简单推导过程:(即引入 baseline 只会减少方差值而不会改变 policy gradient 的实际的值)

也可以用一个参数来拟合 baseline 这个项:

引入 baseline 的 policy gradient 方法:(1999年 sutton 的论文,是要估计两个参数的)

(3)引入 Critic 的方法来减小方差 —— 引出 Actor-Critic 方法

Actor-Critic 策略梯度方法
Actor 就是我们实际跟环境去交互产生训练数据的一个策略
Critic 就是实际的值函数去用于估计/评论

Critic 到底是在做什么事情呢?要怎样进行 Policy Evaluation 呢?

完整的 Actor-Critic 算法流程

在 Actor-Critic 中值函数和策略函数的逼近方法:
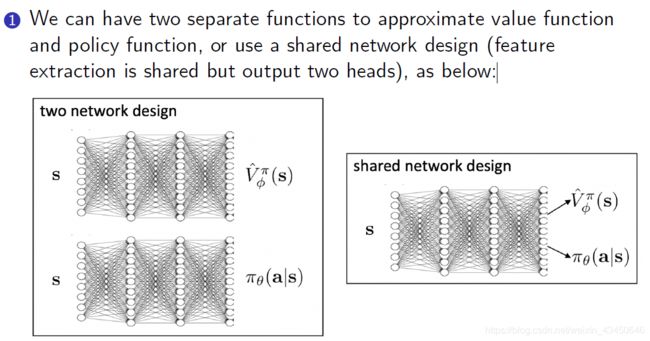
接下来的推导:
如何通过 baseline 方法来降低 Actor-Critic 的方差:中间取那个 Advantage Function 的原因是因为天生 V 函数就可以作为 Q 函数的 baseline 来使用

策略梯度的一些扩展知识
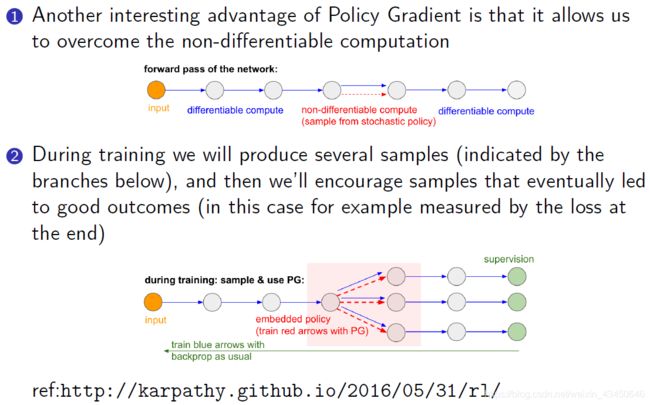
Policy Gradient 的一个很有意思的应用:解决不可微分的问题
Policy Gradient 的扩展发展脉络
最新的 RL 算法基本上都是 policy-based 的方法
比如:A2C、A3C、TRPO 和 PPO 以及2020年刚出来的 SAC[http://studyai.com/spinup/algorithms/sac.html] 等方法

RL 中基于价值和基于策略的两大学派
Value-based 的学派:应用主要是打游戏,主要采用 DP算法,bootstrapping方法等去优化价值函数,然后再从 Q 函数里采取行为;代表人物:Sutton 还有 DeepMind 的 Silver[AlphaGo 项目],他们属于控制背景的老派,哈哈哈
Policy-based 的学派:应用主要是机器人,他们更推崇基于策略函数的强化学习方法,大多是跟 OpenAI 和 Berkeley 有联系,机器学习背景来做强化学习
两家其实殊途同归:都回到了 Actor-Critic 方法

Policy Gradient 和 Q-Learning 的发展脉络

注:本文所有内容源自于B站周博磊老师更新完的强化学习纲要课程,听完之后获益很多,本文也是分享我的听课笔记。周老师Bilibili视频个人主页:https://space.bilibili.com/511221970?spm_id_from=333.788.b_765f7570696e666f.2
感谢周老师 :)