对抗生成网络学习(三)——cycleGAN实现Van Gogh风格的图像转换(tensorflow实现)
一、背景
CycleGAN是Jun-Yan Zhu等人[1]于17年3月份提出的对抗神经网络模型,模型理论与pix2pix非常相似。CycleGAN的主要应用是具有不同风格图像之间的相互转换,相较于pix2pix模型,其最大的贡献在于能够利用非成对数据(unpaired data)进行训练,可扩展性及应用更广。该实验的目的是利用CycleGAN对一批Van Gogh油画图像和现实风景图像进行训练,利用现实风景图像生成具有Van Gogh风格的影像。
本实验用vangogh2photo数据集为例,尽可能用较少的代码实现。
[1]文章链接:https://arxiv.org/abs/1703.10593
二、cycleGAN原理
CycleGAN的原理网上已经有非常完善的介绍,这里只做简单介绍。
关于CycleGAN的原理介绍,推荐几个比较好的介绍,具体参见下面的链接:
[2]提高驾驶技术:用GAN去除(爱情)动作片中的马赛克和衣服
[3]可能是近期最好玩的深度学习模型:CycleGAN的原理与实验详解
[4]干货 | 孪生三兄弟 CycleGAN, DiscoGAN, DualGAN 还有哪些散落天涯的远亲
CycleGAN是对抗神经网络GAN的一种,与CycleGAN同时提出的相似模型还包括DiscoGAN,DualGAN,以及pix2pix。其中与DiscoGAN和DualGAN的区别在上面的链接中有说明。之前也说到了,与pix2pix模型的最大区别在于CycleGAN能够利用非成对数据进行模型的训练,这就使得该模型的扩展性更好,应用范围更广。

在论文中,作者给出了几个该模型应用的例子,比如将马和斑马相互转化,苹果和橘子相互转化,冬季和夏季相互转化,油画和风景相互转化等。
CycleGAN的网络结构为:

其生成器可以认为有两个,即从![]() 和从
和从![]() 的生成器,同理判别器也有两个,同时定义其相应的Loss函数。由此构成一个循环,即CycleGAN的网络结构。
的生成器,同理判别器也有两个,同时定义其相应的Loss函数。由此构成一个循环,即CycleGAN的网络结构。
同时,网上也有一些比较好理解的代码,下面给出链接供参考,其中[5]仅用了一个文件,实现斑马和马的转换,[6]仅用一个文件,实现河网和遥感图像的转换,[7]用少量文件实现图像风格的转换:
[5]https://github.com/floft/cyclegan
[6]https://github.com/tmquan/CycleGAN
[7]https://github.com/nnUyi/CycleGAN/blob/master/CycleGAN.py
本实验参考的代码链接为:https://github.com/architrathore/CycleGAN,并在原代码的基础上进行一定的修改,用尽可能少的代码实现CycleGAN。
三、cycleGAN实现
1.数据准备
此次实验所选择数据集为vangogh2photo,该数据集的下载地址为:
[8]https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/
在该网址的最下面可以找到vangogh2photo数据集,其大小为292MB,下载好解压即可使用。
解压好数据之后,将其放在程序的根目录下,其结构为:
-- *.py
-- *.py
-- *.py
-- vangogh2photo(数据集文件夹)
|------ testA
|------ image01.jpg
|------ image02.jpg
|------ ...
|------ testB
|------ image01.jpg
|------ image02.jpg
|------ ...
|------ trainA(Van Gogh的油画数据集)
|------ image01.jpg
|------ image02.jpg
|------ ...
|------ trainB(现实风景图像数据集)
|------ image01.jpg
|------ image02.jpg
|------ ...实验过程中主要用到trainA和trainB文件夹,其中,trainA一共有400张彩色影像,trainB一共有6287张彩色影像,所有影像的尺寸大小均为256*256,实验的数据集示例如下:

这里由于电脑内存只有8G,如果全部将trainB中的数据直接读入到内存当中,则会造成内存溢出,因此实验时暂时先将trainB中的影像删除至400张左右,以便实验能够正常进行。
编写能够将原始图像读取到内存中的函数,此函数参考了之前编写DCGAN的读取数据函数,并做了一定的修改:
# 读取数据到内存当中
def get_data(input_dir, floderA, floderB):
'''
函数功能:输入根路径,和不同数据的文件夹,读取数据
:param input_dir:根目录的参数
:param floderA: 数据集A所在的文件夹名
:param floderB: 数据集B所在的文件夹名
:return: 返回读取好的数据,train_set_A即A文件夹的数据, train_set_B即B文件夹的数据
'''
# 读取路径,并判断路径下有多少张影像
imagesA = os.listdir(input_dir + floderA)
imagesB = os.listdir(input_dir + floderB)
imageA_len = len(imagesA)
imageB_len = len(imagesB)
# 定义用于存放读取影像的变量
dataA = np.empty((imageA_len, image_width, image_height, image_channel), dtype="float32")
dataB = np.empty((imageB_len, image_width, image_height, image_channel), dtype="float32")
# 读取文件夹A中的数据
for i in range(imageA_len):
# 逐个影像读取
img = Image.open(input_dir + floderA + "/" + imagesA[i])
img = img.resize((image_width, image_height))
arr = np.asarray(img, dtype="float32")
# 对影像数据进行归一化[-1, 1],并将结果保存到变量中
dataA[i, :, :, :] = arr * 1.0 / 127.5 - 1.0
# 读取文件夹B中的数据
for i in range(imageB_len):
# 逐个影像读取
img = Image.open(input_dir + floderB + "/" + imagesB[i])
img = img.resize((image_width, image_height))
arr = np.asarray(img, dtype="float32")
# 对影像数据进行归一化[-1, 1],并将结果保存到变量中
dataB[i, :, :, :] = arr * 1.0 / 127.5 - 1.0
# 随机打乱图像的顺序,当然也可以选择不打乱
np.random.shuffle(dataA)
np.random.shuffle(dataB)
# 执行tensor
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
# 如果输入图像不是 256 * 256, 最好执行reshape
dataA = tf.reshape(dataA, [-1, image_width, image_height, image_channel])
dataB = tf.reshape(dataB, [-1, image_width, image_height, image_channel])
train_set_A = sess.run(dataA)
train_set_B = sess.run(dataB)
return train_set_A, train_set_B
2.编写layer层文件
首先是关于layer层文件的编写,文件名为layer.py,文件的位置在根目录下。layer文件的主要作用是预定义一些层的函数,方便模型的构建,layer层的主要内容包括:
# 导入需要的包
import tensorflow as tf
import random
# 定义leaky_relu层
def lrelu(x, leak=0.2, name="lrelu", alt_relu_impl=False):
with tf.variable_scope(name):
if alt_relu_impl:
f1 = 0.5 * (1 + leak)
f2 = 0.5 * (1 - leak)
# lrelu = 1/2 * (1 + leak) * x + 1/2 * (1 - leak) * |x|
return f1 * x + f2 * abs(x)
else:
return tf.maximum(x, leak * x)
# 定义instance_norm层
def instance_norm(x):
with tf.variable_scope("instance_norm"):
epsilon = 1e-5
mean, var = tf.nn.moments(x, [1, 2], keep_dims=True)
scale = tf.get_variable('scale', [x.get_shape()[-1]],
initializer=tf.truncated_normal_initializer(mean=1.0, stddev=0.02))
offset = tf.get_variable('offset', [x.get_shape()[-1]], initializer=tf.constant_initializer(0.0))
out = scale * tf.div(x - mean, tf.sqrt(var + epsilon)) + offset
return out
# 定义卷积层conv2d
def general_conv2d(inputconv, o_d=64, f_h=7, f_w=7, s_h=1, s_w=1, stddev=0.02, padding="VALID", name="conv2d",
do_norm=True, do_relu=True, relufactor=0):
with tf.variable_scope(name):
conv = tf.contrib.layers.conv2d(inputconv, o_d, f_w, s_w, padding, activation_fn=None,
weights_initializer=tf.truncated_normal_initializer(stddev=stddev),
biases_initializer=tf.constant_initializer(0.0))
if do_norm:
conv = instance_norm(conv)
# conv = tf.contrib.layers.batch_norm(conv, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True, scope="batch_norm")
if do_relu:
if (relufactor == 0):
conv = tf.nn.relu(conv, "relu")
else:
conv = lrelu(conv, relufactor, "lrelu")
return conv
# 定义反卷积层deconv2d
def general_deconv2d(inputconv, outshape, o_d=64, f_h=7, f_w=7, s_h=1, s_w=1, stddev=0.02, padding="VALID",
name="deconv2d", do_norm=True, do_relu=True, relufactor=0):
with tf.variable_scope(name):
conv = tf.contrib.layers.conv2d_transpose(inputconv, o_d, [f_h, f_w], [s_h, s_w], padding, activation_fn=None,
weights_initializer=tf.truncated_normal_initializer(stddev=stddev),
biases_initializer=tf.constant_initializer(0.0))
if do_norm:
conv = instance_norm(conv)
# conv = tf.contrib.layers.batch_norm(conv, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True, scope="batch_norm")
if do_relu:
if (relufactor == 0):
conv = tf.nn.relu(conv, "relu")
else:
conv = lrelu(conv, relufactor, "lrelu")
return conv
# 定义image_pool函数
def fake_image_pool(num_fakes, fake, fake_pool):
'''
函数功能:将num_fakes张生成器生成的影像,保存到fake_pool中
'''
if (num_fakes < pool_size):
fake_pool[num_fakes] = fake
return fake
else:
p = random.random()
if p > 0.5:
random_id = random.randint(0, pool_size - 1)
temp = fake_pool[random_id]
fake_pool[random_id] = fake
return temp
else:
return fake3.编写model文件
编写好layer层函数文件之后,需要编写model文件,该文件中主要是对generator和discriminator的定义,文件名为model.py,文件的位置同样在根目录下。
# 导入编写好的layer层函数文件
from layer import *
image_height = 256
image_width = 256
image_channel = 3
image_size = image_height * image_width
batch_size = 1
pool_size = 50
ngf = 32
ndf = 64
# 定义resnet层
def build_resnet_block(inputres, dim, name="resnet"):
with tf.variable_scope(name):
# 填充
out_res = tf.pad(inputres, [[0, 0], [1, 1], [1, 1], [0, 0]], "REFLECT")
out_res = general_conv2d(out_res, dim, 3, 3, 1, 1, 0.02, "VALID", "c1")
out_res = tf.pad(out_res, [[0, 0], [1, 1], [1, 1], [0, 0]], "REFLECT")
out_res = general_conv2d(out_res, dim, 3, 3, 1, 1, 0.02, "VALID", "c2", do_relu=False)
return tf.nn.relu(out_res + inputres)
# 定义generator
def build_generator_resnet_9blocks(inputgen, name="generator"):
with tf.variable_scope(name):
f = 7
ks = 3
pad_input = tf.pad(inputgen, [[0, 0], [ks, ks], [ks, ks], [0, 0]], "REFLECT")
o_c1 = general_conv2d(pad_input, ngf, f, f, 1, 1, 0.02, name="c1")
o_c2 = general_conv2d(o_c1, ngf * 2, ks, ks, 2, 2, 0.02, "SAME", "c2")
o_c3 = general_conv2d(o_c2, ngf * 4, ks, ks, 2, 2, 0.02, "SAME", "c3")
o_r1 = build_resnet_block(o_c3, ngf * 4, "r1")
o_r2 = build_resnet_block(o_r1, ngf * 4, "r2")
o_r3 = build_resnet_block(o_r2, ngf * 4, "r3")
o_r4 = build_resnet_block(o_r3, ngf * 4, "r4")
o_r5 = build_resnet_block(o_r4, ngf * 4, "r5")
o_r6 = build_resnet_block(o_r5, ngf * 4, "r6")
o_r7 = build_resnet_block(o_r6, ngf * 4, "r7")
o_r8 = build_resnet_block(o_r7, ngf * 4, "r8")
o_r9 = build_resnet_block(o_r8, ngf * 4, "r9")
o_c4 = general_deconv2d(o_r9, [batch_size, 128, 128, ngf * 2], ngf * 2, ks, ks, 2, 2, 0.02, "SAME", "c4")
o_c5 = general_deconv2d(o_c4, [batch_size, 256, 256, ngf], ngf, ks, ks, 2, 2, 0.02, "SAME", "c5")
o_c6 = general_conv2d(o_c5, image_channel, f, f, 1, 1, 0.02, "SAME", "c6", do_relu=False)
# Adding the tanh layer
out_gen = tf.nn.tanh(o_c6, "t1")
return out_gen
# 定义discriminator
def build_gen_discriminator(inputdisc, name="discriminator"):
with tf.variable_scope(name):
f = 4
o_c1 = general_conv2d(inputdisc, ndf, f, f, 2, 2, 0.02, "SAME", "c1", do_norm=False, relufactor=0.2)
o_c2 = general_conv2d(o_c1, ndf * 2, f, f, 2, 2, 0.02, "SAME", "c2", relufactor=0.2)
o_c3 = general_conv2d(o_c2, ndf * 4, f, f, 2, 2, 0.02, "SAME", "c3", relufactor=0.2)
o_c4 = general_conv2d(o_c3, ndf * 8, f, f, 1, 1, 0.02, "SAME", "c4", relufactor=0.2)
o_c5 = general_conv2d(o_c4, 1, f, f, 1, 1, 0.02, "SAME", "c5", do_norm=False, do_relu=False)
return o_c5
4.编写训练文件
编写好model文件之后,需要编写训练文件,该文件中主要是构建模型,实现训练过程,该文件名为main.py,文件的位置同样在根目录下。
# 导入需要的库
from PIL import Image
import time
# 导入model中的函数
from model_new import *
to_train = True # 设置为true进行训练
to_test = False # 不进行test
to_restore = False # 不存储
output_path = "./output" # 设置输出文件路径
check_dir = "./output/checkpoints/" # 输出模型参数的文件路径
data_dir = "./vangogh2photo" # 数据的根目录
temp_check = 0
max_epoch = 1
max_images = 100
h1_size = 150
h2_size = 300
z_size = 100
sample_size = 10
save_training_images = True
# 定义训练过程
def train():
# 读取数据
data_A, data_B = get_data(data_dir, "/trainA", "/tryB")
# CycleGAN的模型构建 ----------------------------------------------------------
# 输入数据的占位符
input_A = tf.placeholder(tf.float32, [batch_size, image_width, image_height, image_channel], name="input_A")
input_B = tf.placeholder(tf.float32, [batch_size, image_width, image_height, image_channel], name="input_B")
fake_pool_A = tf.placeholder(tf.float32, [None, image_width, image_height, image_channel], name="fake_pool_A")
fake_pool_B = tf.placeholder(tf.float32, [None, image_width, image_height, image_channel], name="fake_pool_B")
global_step = tf.Variable(0, name="global_step", trainable=False)
num_fake_inputs = 0
lr = tf.placeholder(tf.float32, shape=[], name="lr")
# 建立生成器和判别器
with tf.variable_scope("Model") as scope:
fake_B = build_generator_resnet_9blocks(input_A, name="g_A")
fake_A = build_generator_resnet_9blocks(input_B, name="g_B")
rec_A = build_gen_discriminator(input_A, "d_A")
rec_B = build_gen_discriminator(input_B, "d_B")
scope.reuse_variables()
fake_rec_A = build_gen_discriminator(fake_A, "d_A")
fake_rec_B = build_gen_discriminator(fake_B, "d_B")
cyc_A = build_generator_resnet_9blocks(fake_B, "g_B")
cyc_B = build_generator_resnet_9blocks(fake_A, "g_A")
scope.reuse_variables()
fake_pool_rec_A = build_gen_discriminator(fake_pool_A, "d_A")
fake_pool_rec_B = build_gen_discriminator(fake_pool_B, "d_B")
# 定义损失函数
cyc_loss = tf.reduce_mean(tf.abs(input_A - cyc_A)) + tf.reduce_mean(tf.abs(input_B - cyc_B))
disc_loss_A = tf.reduce_mean(tf.squared_difference(fake_rec_A, 1))
disc_loss_B = tf.reduce_mean(tf.squared_difference(fake_rec_B, 1))
g_loss_A = cyc_loss * 10 + disc_loss_B
g_loss_B = cyc_loss * 10 + disc_loss_A
d_loss_A = (tf.reduce_mean(tf.square(fake_pool_rec_A)) + tf.reduce_mean(
tf.squared_difference(rec_A, 1))) / 2.0
d_loss_B = (tf.reduce_mean(tf.square(fake_pool_rec_B)) + tf.reduce_mean(
tf.squared_difference(rec_B, 1))) / 2.0
# 定义优化器
optimizer = tf.train.AdamOptimizer(lr, beta1=0.5)
model_vars = tf.trainable_variables()
d_A_vars = [var for var in model_vars if 'd_A' in var.name]
g_A_vars = [var for var in model_vars if 'g_A' in var.name]
d_B_vars = [var for var in model_vars if 'd_B' in var.name]
g_B_vars = [var for var in model_vars if 'g_B' in var.name]
d_A_trainer = optimizer.minimize(d_loss_A, var_list=d_A_vars)
d_B_trainer = optimizer.minimize(d_loss_B, var_list=d_B_vars)
g_A_trainer = optimizer.minimize(g_loss_A, var_list=g_A_vars)
g_B_trainer = optimizer.minimize(g_loss_B, var_list=g_B_vars)
for var in model_vars: print(var.name)
# Summary variables for tensorboard
g_A_loss_summ = tf.summary.scalar("g_A_loss", g_loss_A)
g_B_loss_summ = tf.summary.scalar("g_B_loss", g_loss_B)
d_A_loss_summ = tf.summary.scalar("d_A_loss", d_loss_A)
d_B_loss_summ = tf.summary.scalar("d_B_loss", d_loss_B)
# 模型构建完毕-------------------------------------------------------------------
# 生成结果的存储器
fake_images_A = np.zeros((pool_size, 1, image_height, image_width, image_channel))
fake_images_B = np.zeros((pool_size, 1, image_height, image_width, image_channel))
# 全局变量初始化
init = tf.global_variables_initializer()
# 结果保存器
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter("./output/2")
if not os.path.exists(check_dir):
os.makedirs(check_dir)
# 开始训练
for epoch in range(sess.run(global_step), 100):
print("In the epoch ", epoch)
saver.save(sess, os.path.join(check_dir, "cyclegan"), global_step=epoch)
# 按照训练的epoch调整学习率。更高级的写法可参考:
# lr = lr if epoch < epoch_step else adjust_rate * ((epochs - epoch) / (epochs - epoch_step))
if (epoch < 100):
curr_lr = 0.0002
else:
curr_lr = 0.0002 - 0.0002 * (epoch - 100) / 100
# 保存图像-----------------------------------------------------------------
if (save_training_images):
# 检查路径是否存在
if not os.path.exists("./output/imgs"):
os.makedirs("./output/imgs")
# 保存10张影像
for i in range(0, 10):
fake_A_temp, fake_B_temp, cyc_A_temp, cyc_B_temp = sess.run(
[fake_A, fake_B, cyc_A, cyc_B],
feed_dict={input_A: np.reshape(data_A[i], [-1, 256, 256, 3]),
input_B: np.reshape(data_B[i], [-1, 256, 256, 3])})
# fake表示输入A,通过B的特征而变成B
imsave("./output/imgs/fakeB_" + str(epoch) + "_" + str(i) + ".jpg",
((fake_A_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/fakeA_" + str(epoch) + "_" + str(i) + ".jpg",
((fake_B_temp[0] + 1) * 127.5).astype(np.uint8))
# cyc表示输入A,通过B的特征变成B,再由A的特征变成A结果
imsave("./output/imgs/cycA_" + str(epoch) + "_" + str(i) + ".jpg",
((cyc_A_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/cycB_" + str(epoch) + "_" + str(i) + ".jpg",
((cyc_B_temp[0] + 1) * 127.5).astype(np.uint8))
# 保存图像结束------------------------------------------------------------
# 循环执行cycleGAN
for ptr in range(0, max_images):
print("In the iteration ", ptr)
# Optimizing the G_A network
_, fake_B_temp, summary_str = sess.run([g_A_trainer, fake_B, g_A_loss_summ],
feed_dict={input_A: np.reshape(data_A[ptr], [-1, 256, 256, 3]),
input_B: np.reshape(data_B[ptr], [-1, 256, 256, 3]),
lr: curr_lr})
writer.add_summary(summary_str, epoch * max_images + ptr)
fake_B_temp1 = fake_image_pool(num_fake_inputs, fake_B_temp, fake_images_B)
# Optimizing the D_B network
_, summary_str = sess.run([d_B_trainer, d_B_loss_summ],
feed_dict={input_A: np.reshape(data_A[ptr], [-1, 256, 256, 3]),
input_B: np.reshape(data_B[ptr], [-1, 256, 256, 3]),
lr: curr_lr,
fake_pool_B: fake_B_temp1})
writer.add_summary(summary_str, epoch * max_images + ptr)
# Optimizing the G_B network
_, fake_A_temp, summary_str = sess.run([g_B_trainer, fake_A, g_B_loss_summ],
feed_dict={input_A: np.reshape(data_A[ptr], [-1, 256, 256, 3]),
input_B: np.reshape(data_B[ptr], [-1, 256, 256, 3]),
lr: curr_lr})
writer.add_summary(summary_str, epoch * max_images + ptr)
fake_A_temp1 = fake_image_pool(num_fake_inputs, fake_A_temp, fake_images_A)
# Optimizing the D_A network
_, summary_str = sess.run([d_A_trainer, d_A_loss_summ],
feed_dict={input_A: np.reshape(data_A[ptr], [-1, 256, 256, 3]),
input_B: np.reshape(data_B[ptr], [-1, 256, 256, 3]),
lr: curr_lr,
fake_pool_A: fake_A_temp1})
writer.add_summary(summary_str, epoch * max_images + ptr)
num_fake_inputs += 1
sess.run(tf.assign(global_step, epoch + 1))
writer.add_graph(sess.graph)5.编写主函数
编写完上述文件之后,主函数非常简单,主函数位于main文件的最后:
if __name__ == '__main__':
if to_train:
train()四、实验结果
编写完所有文件之后,直接在main函数下运行即可执行程序,此程序设置100个epoch,训练的结果如下:
当训练第1个epoch时,训练结果基本是噪声:
当训练5个epoch时,已经能够生成具有简单色彩的影像:
当训练15个epoch时,已经可以看到一些纹理,比如45°的纹理线:
当训练30个epoch时,能够生成更加浓郁的色彩:
当训练60个epoch时,生成图像的效果更为细腻一些:
当训练100个epoch时候,图像已经具有了Van Gogh风格,但是Van Gogh风格到现实风格的转化较为失败,其结果的色调整体偏暗:
五、分析
1.生成结果来看,由于Van Gogh的油画图像色彩偏橙黄色,特点比较明显,所以由现实影像生成的Van Gogh风格图像的效果较好,具有明显的油画风格,但是现实世界的风景图往往五彩斑斓,没有非常明显的特点,因此利用Van Gogh的油画生成现实影像的结果较差,由于各种颜色作用的权重因子差距不大,因此如果这样一直训练下去,最终的结果可能是生成黑色的图像(纯属猜测~~~)。
2.实验只进行了100个epoch,可以看到训练了100个epoch的情况下,图像效果还有提升的空间,因此后续可以考虑设置更大的epoch进行训练。
3.关于生成结果为什么是四组图像,这里我做进一步的解释:
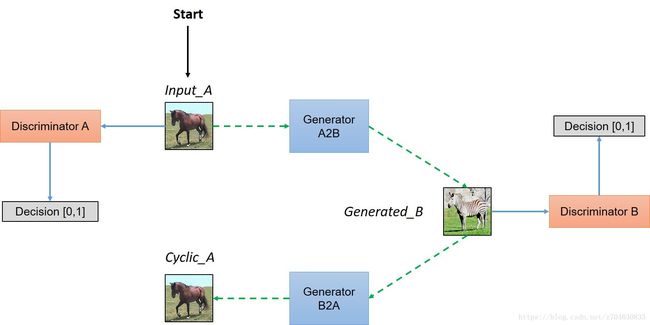
首先上图表示了cycleGAN的模型结构,其来源为:https://github.com/hardikbansal/CycleGAN
生成的图像有四组,分别为fakeA.img和fakeB.img,cycA.img和cycB.img。fakeA和fakeB图像类似于从上图的input_A图像通过Generator A2B生成Generated_B图像的过程,当分别输入A和B时就会产生两组图像。cycA和cycB是类似于从上图的Generated_b图像通过Generator B2A生成Cyclic_A图像的过程,当分别输入A和B,也会产生两组结果。这样最终则会有四组生成图像。
4.实验文件的结构为:
-- vangogh2photo(数据集文件夹)
|------ testA
|------ image01.jpg
|------ image02.jpg
|------ ...
|------ testB
|------ image01.jpg
|------ image02.jpg
|------ ...
|------ trainA(Van Gogh的油画数据集)
|------ image01.jpg
|------ image02.jpg
|------ ...
|------ trainB(现实风景图像数据集)
|------ image01.jpg
|------ image02.jpg
|------ ...
-- layer.py
{
import ...
def lrelu(x, leak=0.2, name="lrelu", alt_relu_impl=False):...
def instance_norm(x):...
def general_conv2d(inputconv, o_d=64, f_h=7, f_w=7, s_h=1, s_w=1, stddev=0.02, padding="VALID", name="conv2d",
do_norm=True, do_relu=True, relufactor=0):...
def general_deconv2d(inputconv, outshape, o_d=64, f_h=7, f_w=7, s_h=1, s_w=1, stddev=0.02, padding="VALID",
name="deconv2d", do_norm=True, do_relu=True, relufactor=0):...
def fake_image_pool(num_fakes, fake, fake_pool):...
}
-- model.py
{
import ...
image_height = ...
...
def build_resnet_block(inputres, dim, name="resnet"):...
def build_generator_resnet_6blocks(inputgen, name="generator"):...
def build_generator_resnet_9blocks(inputgen, name="generator"):...
def build_gen_discriminator(inputdisc, name="discriminator"):...
def patch_discriminator(inputdisc, name="discriminator"):...
}
-- main.py
{
import ...
to_train =...
...
def get_data(input_dir, floderA, floderB):...
def train():...
if __name__ == '__main__':...
}