台大李宏毅PPT:什么是 Lifelong learning, Continual Learning, Never Ending Learning, Incremental Learning,CL
文章目录
-
- 视频链接:
- 台大 李宏毅 PPT_lifelong learning / continual learning
-
- PPT中提及的论文:
- 1. 什么是灾难性遗忘?
- 2. 解决方法:
-
- 为什么不使用 multi-task training
- EWC (Elastic Weight Consolidation)
- Generation Datas
- Knowledge transfer
- 3. evaluation 评价方式
-
- Model Expansion 模型扩张/增大
- 4. Curriculum Learning 课程学习(任务排序, 如何排序?)
- END
视频链接:
https://www.youtube.com/watch?v=7qT5P9KJnWo&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=25
台大 李宏毅 PPT_lifelong learning / continual learning
PPT中提及的论文:
2017 EWC: Elastic-Weight-Consolidation https://arxiv.org/pdf/1612.00796.pdf
- github: https://github.com/yashkant/Elastic-Weight-Consolidation
2017 Continual Learning with Deep Generative Replay https://arxiv.org/abs/1705.08690
2017 FearNet: Brain-Inspired Model for Incremental Learning https://arxiv.org/abs/1711.10563
Learning without Forgetting https://arxiv.org/abs/1606.09282
iCaRL: Incremental Classifier and Representation Learning https://arxiv.org/pdf/1611.07725.pdf
GEM: Gradient Episodic Memory for Continual Learning https://arxiv.org/abs/1706.08840
- https://github.com/facebookresearch/GradientEpisodicMemory
A-GEM: Efficient Lifelong Learning with A-GEM https://arxiv.org/abs/1812.00420
2016 Progressive Neural Networks https://arxiv.org/abs/1606.04671
Expert Gate: Lifelong Learning with a Network of Experts https://arxiv.org/abs/1611.06194
2016 Net2Net: Accelerating Learning via Knowledge Transfer https://arxiv.org/abs/1511.05641
2019 Towards Training Recurrent Neural Networks for Lifelong Learning https://arxiv.org/pdf/1811.07017.pdf
2018 Disentangling Task Transfer Learning CVPR18 beat paper : http://taskonomy.stanford.edu/#abstract
1. 什么是灾难性遗忘?




下面是一个图像分类任务存在遗忘的例子:
训练任务顺序的不同会影响,最后训练的结果。

同时训练两个任务数据时,能学习很好,说明不是模型容量小的原因。

下面是语音识别的例子,也存在遗忘问题。

顺序学习(训练)任务之后,模型只能记住当前任务,会忘记之前的任务。
同时训练所有任务时,模型能同时学会所有的任务,说明不是模型容量小的原因。

这种现象称为 灾难遗忘问题

2. 解决方法:
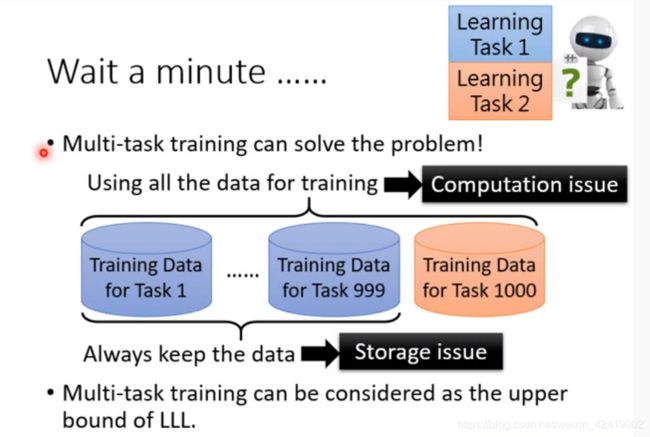
为什么不使用 multi-task training
multi-task training 就是我们平时将所有的数据集进行混合之后,随机抽取样本进行训练的方法。
multi-task training 通常作为 continual learning 的上限。
- 只是回避了灾难遗忘问题,但没有解决灾难遗忘问题;
- 存储上,耗费空间:在学习第1000个任务时,必须与前面的999个任务的数据集一起混合,所以需要保存前面999个任务的数据集。如果能实现continual learning,那么我们就不需要存储前面999个任务的数据集。
- 计算上,耗费时间:在学习第1000个任务时,一共需要训练1000个数据集,训练时间是训练1个数据集时间的1000倍。如果能实现 continual learning, 那么我们就只需要训练新的一个训练数据集。
EWC (Elastic Weight Consolidation)
弹性权重巩固, 下面两个PPT是算法思想
算法的思想:在之前的任务上训练好任务之后,权重就确定了,之后训练新的任务的话,就需要 修改/调整 这些已经训练好的权重,所以只修改那些如果修改之后对先前任务影响小的权重,不修改那些如果修改之后对先前任务影响大的权重。
具体实现: 在标准loss 后面加一项
修改之后是否对先前任务影响用 b_i 表示。找这个b 是关键。

b_i = 0。 表示 不进行约束,那个参数的改变对原任务没有影响,可以随意修改;
b_i = 正无穷, 表示 进行最强的约束,那个参数的改变对原任务特别大的影响,一点都不能修改。

下图是不加EWC的训练结果,训练完任务2 之后就忘记任务1 了。
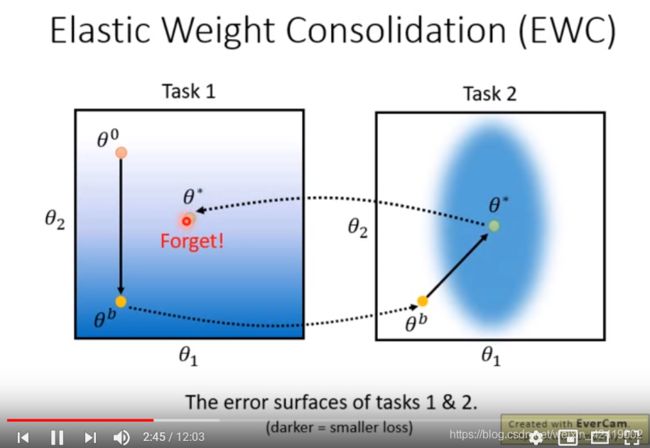
添加EWC只会,这里使用权重的二次微分来表示权重修改对结果的影响。
下图是假设训练模型只有两个参数,训练完第一个任务之后,从右侧的图可以看出,参数2对 loss 的二次微分(变化率)很大,相当于b很大。所以这里不能修改参数2,只能修改参数1。
颜色越深,loss越小。
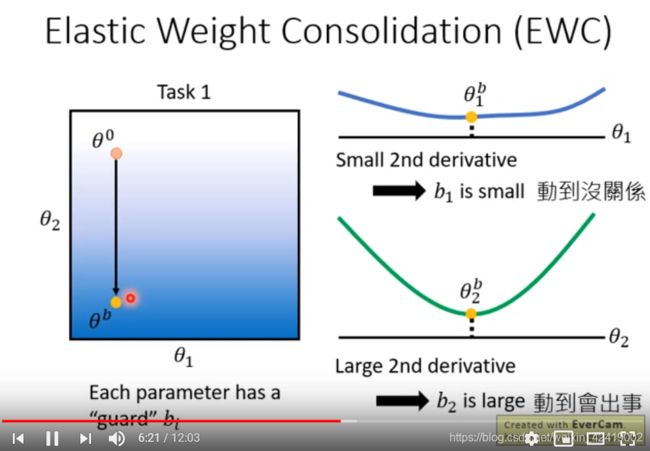
这样就会出现参数2不动,参数1右移的结果。整体也会落在最优解(颜色深的地方)之中。
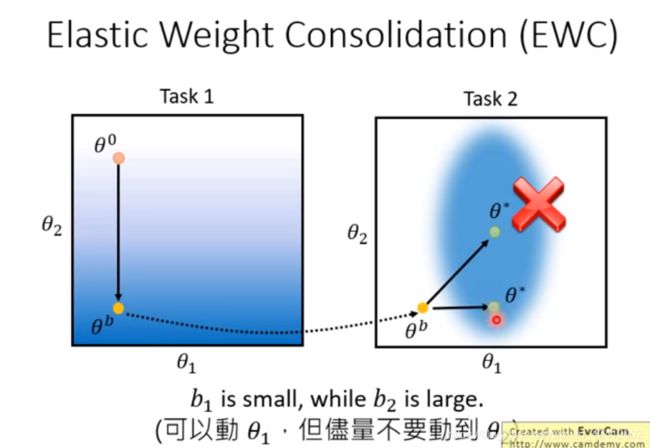
EWC 不会出现遗忘现象;
SGD会出现遗忘现象;
L2学不会新得任务。
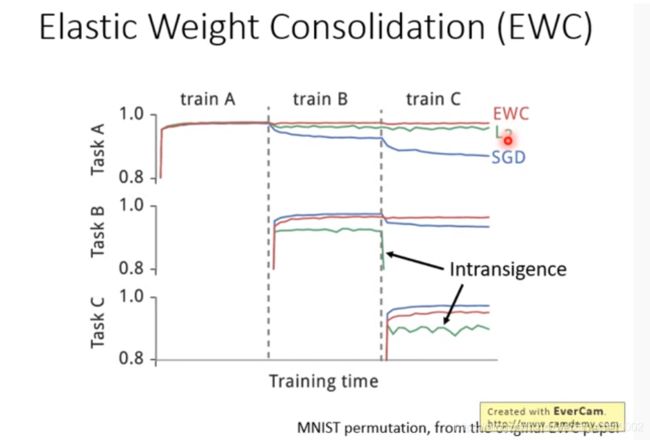
EWC :http://www.citeulike.org/group/15400/article/14311063

Generation Datas
使用一个生成器 来替代存储大量的数据集。 需要数据集来训练任务时,直接使用生成器来生成数据即可。
2017 Continual Learning with Deep Generative Replay https://arxiv.org/abs/1705.08690
2017 FearNet: Brain-Inspired Model for Incremental Learning https://arxiv.org/abs/1711.10563

当不同的任务需要使用不同的网络结构时,该如何更改网络结构呢?
Learning without Forgetting https://arxiv.org/abs/1606.09282
iCaRL: Incremental Classifier and Representation Learning https://arxiv.org/pdf/1611.07725.pdf

Knowledge transfer
不使用不同的model 来训练不同的任务的原因:
- 一个模型学习一个任务。会出现不同的任务之间是相互独立的,我们希望 模型/任务之间是有关联的,知识的学习应该是存在递进关系的,不同任务之间的学习应该能互相促进。
- 存储空间与任务数量是线性的,我们希望更小的模型学习更多的东西。

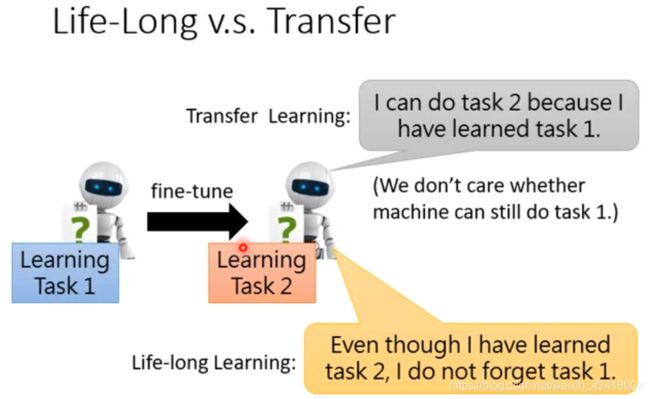
迁移学习 与 LLL的区别:迁移学习只关注当前的任务,LLL要求不能忘记之前的任务。
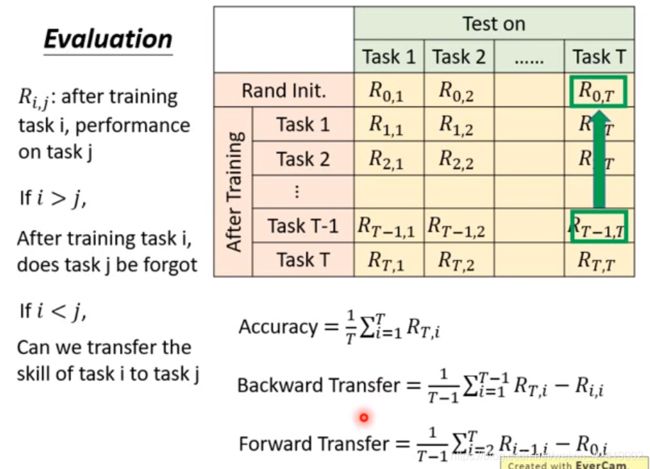
3. evaluation 评价方式
在不同的训练任务(每一行)结束之后,都会得到一个模型,使用这个模型来测试所有(各列)的任务(包含没有训练过的任务),就可以得到下表。
红色的 accuracy
蓝色的 backward BWT

绿色的 forward FWT
Gradient Episodic Memory for Continual Learning https://arxiv.org/abs/1706.08840
Efficient Lifelong Learning with A-GEM https://arxiv.org/abs/1812.00420
在当前任务上进行的每一次权重修改,都需要计算当前权重对先前任务的梯度方向,保证最终的权重修改方向与先前任务(即先前任务数据集,所以需要利用之前的数据集)在此时的权重修改方向的內积为正。目的是为了保证不对之前的任务产生负影响,甚至产生好的影响。
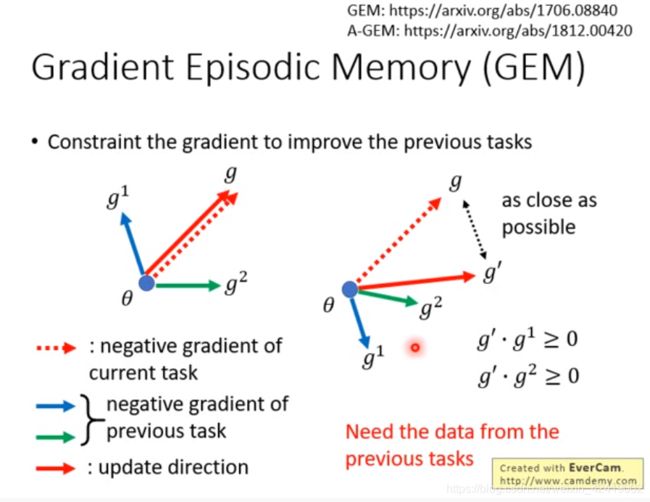
GEM的BWT是正的,说明学习新的任务提升了旧任务的表现。

Model Expansion 模型扩张/增大
我们希望模型的增长速度是低于任务的增长速度。

2016 Progressive Neural Networks https://arxiv.org/abs/1606.04671
训练新任务时,利用之前的模型参数。
多一个任务,多一个模型。

Expert Gate: Lifelong Learning with a Network of Experts https://arxiv.org/abs/1611.06194
多一个任务多一个模型;
利用之前的模型来建立新的模型。

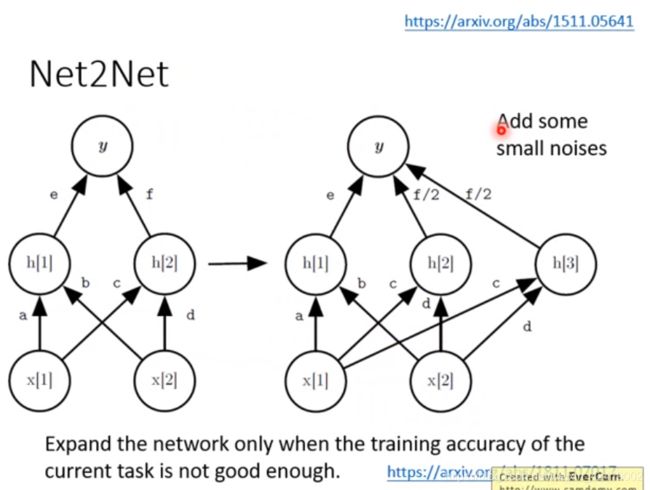
2016 Net2Net: Accelerating Learning via Knowledge Transfer https://arxiv.org/abs/1511.05641
2019 Towards Training Recurrent Neural Networks for Lifelong Learning https://arxiv.org/pdf/1811.07017.pdf
将原来的节点一分为二,之后加 noise 保证两个节点有点却别,能学习心得任务,但不忘记旧的任务。
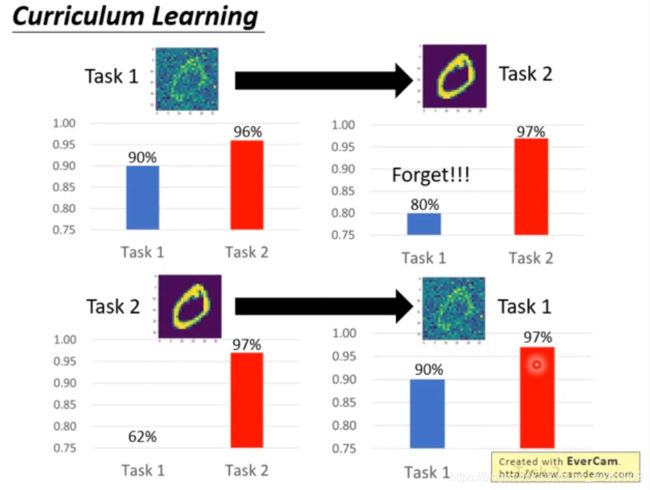
4. Curriculum Learning 课程学习(任务排序, 如何排序?)
如果LLL完全实现了,那如何排出一个最有效的学习顺序呢?Curriculum Learning
下图是说明,顺序不同,训练的结果不同。
2018 Disentangling Task Transfer Learning CVPR18 beat paper : http://taskonomy.stanford.edu/#abstract