【ACL2019论文解读】Self-Supervised Learning for Contextualized Extractive Summarization
论文:https://arxiv.org/pdf/1906.04466.pdf
源码:https://github.com/hongwang600/Summarization
摘要:
现存摘要抽取模型大都用交叉熵损失(刻画两个概率分布的距离)从零训起,难以捕获文档级别的全局上下文特征。本文引入三个预训练任务,用自监督(self-supervised)方法捕获文档全局特征。使用CNN/DailyMail数据集证明预训练的模型即使接上简单模块也比以前SOTA表现好。
1.Introduction
抽最重要的句子,得对文档有全局观(如主题和文章结构),但之前end-to-end模型的都没有明确的文档级别编码,指望着模型自己学出来,他认为不大可能,毕竟从头开始训练。近几年也是仅限于词编码和句编码,于是提出了一种新的预训练方法,这种方法使用自监督(self-supervised)对文档编码。
自监督(2007-2015)目的是学习原始数据的内在结构。其使用结构化的原始数据构造训练信号来训练模型。文章本来就是精心布局谋篇的结构化数据,所以自监督能派上用场。
本文提出了Mask、Replace、Switch三个需要学习文档级别结构和上下文的自监督任务,然后把预训练得到的模型迁移到摘要任务。Mask任务随机mask一些句子,然后从候选句子集中预测被mask的句子。Replace任务随机从其他文档里替换过几个句子来,然后预测某句是否被替换了。Switch任务用同一文档的句子进行交换,然后预测某句是否被交换过。下图是Mask任务的一个例子。

从CNN/DM数据集实验后发现这三个预训练任务都很好,其中一个超过了sota模型NeuSum(ACL2018)。本文贡献有三:
一是,首次用全局文档信息进行非人工标注式自监督句子表征。
二是,提出是三个方法,其中一个超过了sota。
三是,使用预训练的模型,收敛快,效率高。
2. Model and Pre-training Methods
2.1 Basic Model

模型如上,分为“句子编码器模块”和“文档自注意力模块”。句子encoder是双向LSTM。Xi是词向量,Si是普通句向量,Di是考虑文档信息的句向量,最后通过一个线性层预测是否选为摘要。
2.2 自监督的预训练模型(三个方法)
Mask
和预测被mask的词类似,首先以![]() 的概率mask一些句子
的概率mask一些句子![]() ,放入候选集合
,放入候选集合![]() 中。模型对每个被mask的位置i,从候选集合里挑正确句子。本文把mask的句子用
中。模型对每个被mask的位置i,从候选集合里挑正确句子。本文把mask的句子用![]() 。用同样的句子encoder获取候选集合中句子的embedding
。用同样的句子encoder获取候选集合中句子的embedding![]() 。
。![]() 是候选句子 j ,用cos给句子 j 打分。
是候选句子 j ,用cos给句子 j 打分。
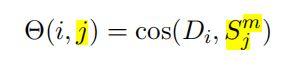
训练时,使用ranking loss(排序误差)做为损失函数最大化标准句和其他句之间的差异。i是第i个位置,j是黄金句,k是其他候选句。γ是超参数。

Replace
首先以概率![]() 随机替换掉一些句子(来源为其他文档),然后预测这句是不是被替换了。具体来说,本文从1万篇随机选取的文档里抽句子形成候选集
随机替换掉一些句子(来源为其他文档),然后预测这句是不是被替换了。具体来说,本文从1万篇随机选取的文档里抽句子形成候选集![]() ,
,![]() 表示被替换的句子们的位置集合。本文使用一个线性层
表示被替换的句子们的位置集合。本文使用一个线性层![]() 来根据文档编码D来预测句子是否被替换,最小化MSE损失函数。
来根据文档编码D来预测句子是否被替换,最小化MSE损失函数。

其中, ![]() ,被替换的话y是1,否则y是0。
,被替换的话y是1,否则y是0。
Switch
和Replace任务类似,但不是从其他文档选句子,而是内部交换。![]() 表示被交换的句子们的位置集合。本文使用一个线性层
表示被交换的句子们的位置集合。本文使用一个线性层![]() 来根据文档编码D来预测句子是否被交换,最小化MSE损失函数。
来根据文档编码D来预测句子是否被交换,最小化MSE损失函数。
![]()
其中,![]()
3.Experiment
本文和两个baseline对比,一个是著名的Lead3(选前3句),一个是sota模型NeuSum(指针网络)。
3.1 CNN/DM数据集
模型和训练细节
本文使用是摘要标1,不是标2的方法标注。根据rouge代码和论文,本文评测了Rouge-1,Rouge-2,Rouge-L。本文使用100维的Glove初始化词向量权重。LSTM用作句子encoder,隐藏层size为200。文档编码模块使用了5层4头的Transformer encoder。最后是个线性分类层。
训练分两个阶段。首先,用无标签的原始数据预训练(三种方法);然后,用有标签的数据对摘要任务进行fine-tune。预训练阶段学习率为0.0001,fine-tune阶段学习率为0.00001。收敛或epoch达到上限30时训练停止。mask、replace、switch了1/4的句子。
结果
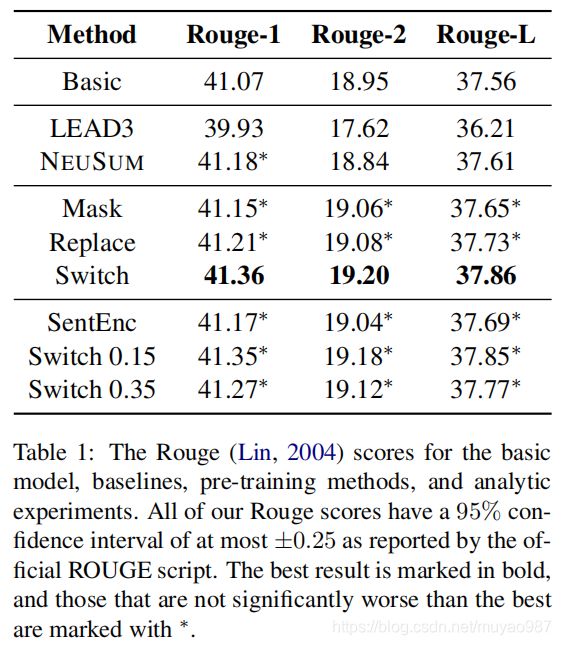
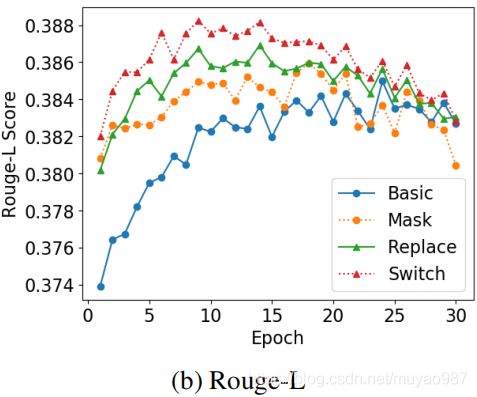
switch方法超过了sota的NeuSum。收敛速度方面,Mask、Replace、Switch分别用了21,24,17个epoch,并且在fine-tune阶段分别在第18,13,9个epoch到达最佳效果。而basic model训了24个epoch才达到最佳状态。


3.2 消融分析
关于模型结构
仅用句子encoder,而文档编码模块随机初始化,结果如上表最下面SentEnc。对于Switch,取0.25时效果最好。只使用句子encoder对模型也有帮助,说明了预训练的模型也能学习句子表示。
关于超参数
实验了Switch了百分之多少的句子,发现对模型影响不是很大,在0.15到0.25时最佳。
4.Conclusion
本文提出了三个自监督任务让模型学习文档级别的上下文信息,并应用于摘要抽取任务。其中Switch的预训练方法训出来的模型超过了sota。文档级别的编码有助于摘要任务,此外超参数对结果影响不是很大。