行人检测论文阅读(2)
一、基于深度学习的行人检测-王斌-北京交通大学-2015
行人检测的应用背景:视频监控、车辆辅助驾驶、智能机器人等领域。
1、论文特点
(1)通常深度学习网络的层次较深,需要学习参数非常多,只有在训练样本充足时才能有效地避免网络训练过拟合。对此本文采用基于内容的图像检索方法进行数据扩充,该方法在进行数据库扩充时充分考虑到原数据库的行人分辨率,背景分布等因素,使扩充后的数据库仍然保持INRIA数据库原有的数据分布,从而有利于训练对INIRIA数据库检测效果更佳的深度学习网络。
(2)针对行人检测窗口选择过程中使用滑动窗口产生冗余窗口较多且质量不高的问题,本文提出了一种多策略窗口选择的方法,该方法先利用选择性搜索算法提取质量高的预选区域,然后结合图像中行人特性和二值规范化梯度算法对预选区域进行过滤去除大量冗余窗口。最终产生了数目少、质量高的窗口,为后续的特征提取及分类提供了很好的保障。
实验结果表明:
利用基于内容的图像检索方法进行数据扩充后训练的基于深度学习的行人检测系统,在保持误检率为10%的情况下,漏检率仅为38%,比传统HOG特征的46%降低8%;
在此基础上结合本文提出的窗口选择策略,漏检率降为23%,比使用HOG特征大幅降低了23%。
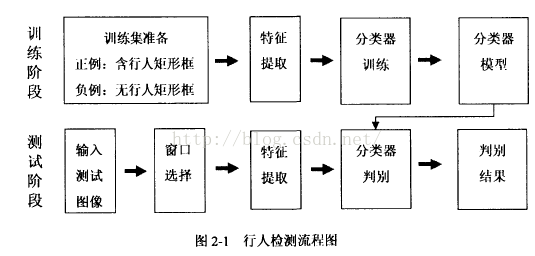
行人检测包括两个阶段,一个是目标窗口的选取,进而使对选取的目标窗口进行分类。深度学习对于第二个阶段—图像分类任务的效果己经很好,但是对于目标窗口的选取,还是存在着很多的问题。本文将通用目标检侧( General Object Detection)两个主流方法选择性搜索(Selective Search SEL )和二值规范化梯度(Hinarized Nonmed Gradients BING )的方法巧妙的融合提取预选区域,再次提升了行人检测效果。
2、行人检测综述
(1)滑动窗口选择:一般来说先固定待检测图像,然后用不同尺度的滑动窗口遍历整幅图像(也可以固定滑动窗口,对输入图像进行缩放后遍历搜索)。
(2)梯度方向直方图(HOG)优点:
首先,由于梯度方向直方图是在图像的局部方格单元上进行操作,使得它对图像几何和光学的形变都能保持很好的不变性,因为这两种形变只会出现在更大的空间领域上;
其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿态,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。
梯度方向直方图(HOG)的核心:是在一幅图像中,局部目标的表象和形状可以用梯度或边缘的方向密度分布很好地进行描述。
(3)支持向量机(SVM,2000年):是基于统计学习理论的机器学习方法,属于监督学习算法。由于在样本数量较少的情况下支持向量机能比较快速的学习出一个不错的分类决策。
支持向量机通过构建一个或多个高维(可以推广到无限维)的超平面划分不同的类别,这个超平面就是分类边界。一般来说,分界边界距离其最近的不同样木点越远越好,这样可以降低分类器的泛化误差。在支持向量机中,分类边界与样本点之间的矩离称为间隔( margin ),支持向量机的目标就是找到个间隔最大的超平面作为分类界面。
(4)行人数据库:
目前行人检测的数据库已经有很多,包括静态图像数据库(MIT行人数据库、INRIA行人数据库)和视频数据库(Caltech行人数据库、ETH行人数据库、KITTI
行人数据库等),本文主要介绍INRIA, Caltech和ETH行人数据库。
INRIA行人数据库的图像背景复杂多变,都是实际生活中的存在的各种场景,图像都是高清图像,行人的分辨率高;
Caltech行人数据库是车载摄像机拍摄的,所以背景虽然多变,但主要是公路或者街道,行人的分辨率比较低,同时标记文件有Person(单个行人)和People(人群)的区分;
ETH行人数据库图像质量较好,行人分辨率较高,但背景大体就是几个街道,太过单一。
(5)基于HOG和SVM的行人检测
上文介绍了传统行人检测的王个主要部分:窗口选择(滑动窗口)、特征提取(梯度直方图特征)、分类器设计(支持向量机)。对传统的基于HOG+S V M的行人检测方法:
OpenCV2.4.8自带HOG+SVM行人检测效果,可以看出基于HOG和SVM的行人检测方法对于背景简单,光照情况好的图像检测效果还是不错的,但是对于光照不足、形态变化大、复杂背景等情况效果不是很好,漏检和误检率都比较高。出现这种情况的主要原因是因为提取的HOG特征对于各种情形的鲁棒性并不是很高。为了设计更好的能够适应各种情况的行人检测系统,就必须找到一种更加鲁棒的特征。
3、基于深度学习的行人检测
(1)一些概念知识
比如经典的AlexNet有8层,VGG模型有16层,GoogLeNet网络有22层之多。深度学习网络通过逐层特征变换,将样本在原始空间的特征映射到一个新的特征空间。
激活函数一般采用:sigmoid函数或者tanh函数
卷积神经网络几个比较重要的概念:局部感受野、权值共享、池化
局部感受野,每个隐含层的神经元只跟输入图像10x10的局部感受野连接,
权值共享:卷积神经网络中提取同一种特征时的每个隐含层神经元与对应的局部感受野区域之间的权值是相同的
池化:
与传统用于分类的CNN方法的区别是,R-CNN是先提取目标区域,然后对目标区域提取特征进行分类,而传统分类任务是对整幅图像提取特征并分类。下面
具体介绍基于深度学习的行人检测系统。
(2)基于深度学习的行人检测系统整体流程为:
1.输入图像;
2.利用选择性搜索的快速模型(Fast Model)提取预选区域;
3.对提取到的区域调整为227 x 227的大小;
4.提取3中区域图像的CNN特征;
5.利用linear SVMs对CNN特征分类,判断是否为行人。
(3)图像检索扩充
针对这个问题,本文利用颜色矩(Color Moments)进行图像检索扩充,利用颜色矩的原因是其速度快而且能找到外部数据库中跟目标数据库颜色特征更相似的图像。
4、多策略融合窗口
滑动窗口提取过程相当耗时,而且产生过多冗余的窗口会对后续的分类任务产生影响。
选择性搜索方法:结合图像的颜色信息、纹理信息和包含关系进行分割从而划分不同的区域。
二值规范化梯度:利用图像的边缘信息,将物体与背景分开。
5、其他
AdaBoost方法从大量的简单Haar特征中选取判别能力强的特征进行分类(2001年,Viola等人)
梯度方向直方图(HOG特征,2005年,Dalal等人)
局部二值模式(Local Binary Pattern ,LBP)两种变形:semantie-LBP和Fourier-LBP。
变形部件模型DPM:考虑到目标内部的结构,能够很好的检测不同姿态的行人并且能很好的区分目标和背景。