Linux阅码场 - Linux内核月报(2020年08月)
关于Linux内核月报
Linux阅码场
Linux阅码场内核月报栏目,是汇总当月Linux内核社区最重要的一线开发动态,方便读者们更容易跟踪Linux内核的最前沿发展动向。
限于篇幅,只会对最新技术做些粗略概括,技术细节敬请期待后续文章,也欢迎广大读者踊跃投稿为阅码场社区添砖加瓦。
本期月报主要贡献人员:
张健、廖威雄、chenwei、柱子、王立辰、M.J、转角遇到猫、冥王、李帅
第一期链接:
Linux阅码场 - Linux内核月报(2020年06月)
Linux阅码场 - Linux内核月报(2020年07月)
目录:
1. 体系结构相关
1.1 Add UEFI support for RISC-V
1.2 Control-flow Enforcement
1.3 Unify NUMA implementation between ARM64& RISC-V
1.4 x86/uaccess: Use pointer masking to limit uaccess speculation
2. Core Kernel
2.1 Generalizing bpflocalstorage
2.2 tailcalls in BPF subprograms
2.3 io_uring: add restrictions to support untrusted applications and guests
2.4 Core-sched v6+: kernel protection and hotplug fixes
3. 设备驱动相关
3.1 Intel Platform Monitoring Technology
3.2 Net: add support for threaded NAPI polling
4. 内存管理
4.1 memcg: Enable fine-grained per process memory control
4.2 huge vmalloc mappings
4.3 Support high-order page bulk allocation
5.文件系统和Block IO
5.1 ext4: add free-space extent based allocator
5.2 virtiofs: Add DAX support
5.3 xfs:解决2038年时间戳上限
5.4 block/bpf:用eBPF实现IO请求的过滤
5.5 fs:新增支持读写的Linux NTFS
6.网络
6.1 在MPTCP中引入SYN Cookie功能
6.2 BPF
7.虚拟化和容器
7.1 Enable Linux guests on Hyper-V on ARM64
7.2 Remove 32-bit Xen PV guest support
7.3 HSM driver for ACRN hypervisor
7.4 mm/virtio-mem: support ZONEMOVABLE
7.5 Support virtio cross-device resources
7.6 KVM:Add virtualization support of split lock dection
7.7 KVM: PKS Virtualization support
当前内核版本:
- Linux 5.8 (August 2, 2020)
- 开发版本Linux 5.9-rc2 (August 23, 2020)
1. 体系结构相关
本月x86,ARM64,RISC-V三大架构都有更新,有之前提到过的
MTE补丁(由ARM64的maintainer Catalin继续更新)
RISC-V的UEFI支持
Intel的硬件控制流完整性(CFI: Control Flow Integrity )技术(CET: Control-flow Enforcement)
还有tglx发起的超大(38个)补丁集“x86, PCI, XEN, genirq …: Prepare for device MSI”
1.1 Add UEFI support for RISC-V
更新最频繁的是Atish Patra的Add UEFI support for RISC-V [1],一个月内更新了三次。和七月相比,目前的工作已经支持了Linux启动和runtime services。其中runtime services已经通过Linux启动和fwts( FirmwareTestSuite [2])测试。RISC-V的EFI支持同时复用了部分ARM64runtime的代码。
[1] Add UEFI support for RISC-V https://lwn.net/Articles/829130/
[2] FirmwareTestSuite https://wiki.ubuntu.com/FirmwareTestSuite
1.2 Control-flow Enforcement
CET技术(控制流强制技术)是英特尔推出的一项用于阻止ROP和JOP攻击JOP的安全技术。CET技术的原理是使用影子寄存器,追踪线程堆栈中的调用及返回地址,在程序返回或调用时做校验匹配,若有问题则抛出异常。详细细节可参考"Intel 64 and IA-32 Architectures Software Developer'sManual"。目前Yu-cheng新增了shadow stack 部分和 indirect branch tracking, ptrace,并测试运行稳定。
1.3 Unify NUMA implementation between ARM64& RISC-V
这个系列patch通过复用ARM64的NUMA实现让RISC-V也能支持NUMA系统。
1.4 x86/uaccess: Use pointer masking to limit uaccess speculation
2018年的Spectre变种1(bounds-check bypass),借助边界检查时cpu会投机访问(speculate access),实现攻击。之前x86在 copy_from_user中使用LFENCE减缓这种攻击。但是LFENCE有点重了。
来自Redhat的Josh把LFENCE替换为 array_index_nospec,后者原本的用途是数组访问越界时,把index被钳位为0,从而避免攻击者访问原本不允许访问的超过数组范围的地址。由于64位内核中,用户空间地址为低地址(以一串0开头),内核为高地址(以一串1开头)。如果给 array_index_nospec传入0和用户地址的最大范围( user_addr_max()),当攻击者试图从用户空间传入内核地址(即大于 user_addr_max()的地址时,该地址会被 array_index_nospec设为0。从而避免了攻击者从用户空间“偷到”内核的数据。
2. Core Kernel
Core Kernel主要是bpf相关的更新比较多。
2.1 Generalizing bpflocalstorage
该补丁意在使一些BPF程序类型使用bpfskstorage来抽象套接字对象。这些抽象是通过对象的生命周期来管理的,目的是使BPF程序更加简单,并且不容易出错和泄漏。本补丁主要实现:
概括了bpfskstorage基础结构,以使其易于实现其他对象的本地存储
为inode实现本地存储
使bpf_ {sk,inode} _storage都可用于LSM程序
2.2 tailcalls in BPF subprograms
目前BPF对BPF程序本身的调用和尾部调用是互斥的,但是该补丁成功让他们可以同时工作,即让尾部调用可以和BPF子程序同时工作。该补丁通过在开始和结束阶段丢弃未使用的被调者保存的push/pop寄存器数值,从而提升AF-XDP的运行速度。其最终结果是提升了15%左右的性能。该补丁的缺陷在于它将会对利用尾部调用的BPF程序产生负面影响,但是影响不大。总而言之,从长远来看:利大于弊。
2.3 io_uring: add restrictions to support untrusted applications and guests
该补丁添加了一些限制条件,从而使不受信任的应用程序和用户能够访问iouring。其想法是在操作中添加一些限制(sqe操作码和标志位,注册操作码),这样能够允许不受信任的应用和用户安全的使用iouring队列。
2.4 Core-sched v6+: kernel protection and hotplug fixes
该补丁增加系统的安全性,是V6核心调度逻辑的延续。它增加了用户模式进程和访客之间系统调用和中断的隔离。而这是当其他用户或者访客使用HT,在HT下安全进入内核模式的关健。该系列补丁还解决了当选择下一个task的时候,cpusmtmask改变导致的CPU热插拔问题。
该问题的根本原因在于:虽然内核调度避免了用户模式下的超线程之间的攻击,但是当某个超线程进入内核时,内核调度逻辑并没有做任何追踪处理。这就导致了MDS和L1TF攻击在超线程并发执行时有机可乘。该系列补丁实现了跟踪进入及退出内核的线程。从而增加了对保护所有syscall和IRQ内核模式条目的支持。
性能测试:sysbench用于测试该补丁的性能。使用4核8线程的虚拟机并同时运行2个sysbench测试程序。每个sysbench运行4个任务:sysbench --test = cpu --cpu-max-prime = 100000 --num-threads = 4运行。比较以下各种组合的性能结果。以下指标是“每秒事件数”:
| 条件 | 结果 |
|---|---|
| Coresched已禁用 | sysbench-1 / sysbench-2 => 175.7 / 175.6 |
| 启用Coreched,两个sysbench都标记追踪 | sysbench-1 / sysbench-2 => 168.8 / 165.6 |
| 已启用Coresched,已标记追踪sysbench-1,未标记追踪sysbench-2 | sysbench-1 / sysbench-2 => 96.4 / 176.9 |
| 关闭 | sysbench-1 / sysbench-2 => 97.9 / 98.8 |
同时标记追踪两个sysbench时,性能下降约4%。对于带标记/未标记的情况,带标记的情况会受到影响,因为当它进入内核时,它总是会停顿。但这并不比smtoff差。
3. 设备驱动相关
3.1 Intel Platform Monitoring Technology
英特尔平台监控技术(Intel Platform Monitoring Technology,简称PMT),是一种枚举和访问 硬件监控功能的架构.随着用户对硬件的遥测技术越来越感兴趣,这就要求工程师不仅要弄清楚硬件是如何 测量和收集数据的,还要清楚数据如何传输并且可视.这些通常都需要特殊工具来实现,这也就要求用户 管理多套不同的工具,以便在其系统上收集不同种类的监视数据.如果在内核驱动里实现这些功能,就要 经常维护,并随着硬件更新而时刻改变.
PMT提供了一种通过硬件不可知框架从设备发现和读取遥测数据 的解决方案,该框架允许在不需要内核或软件工具补丁的情况下对系统进行更新.
PMT定义了几个功能来支持从硬件收集监控数据,所有这些都可以作为带有Intel厂商代码的PCIE指定厂 商扩展能力(DVSEC)的单独实例被发现.DVSEC ID唯一.并为每个ID提供BAR偏移,偏移内包括GUID、 特性类型、偏移量和长度,以及适用的配置设置,GUID唯一地标识了监视器数据的寄存器空间,同时通 过xml提供开放出来的寄存器列表.这允许供应商执行固件更新,可以改变映射(例如,添加新的指标), 而不需要对驱动程序或软件工具进行任何更改.
3.2 Net: add support for threaded NAPI polling
NAPI轮询(polling)工作方式已被大多数设备(尤其是 802.11设备)所支持,但轮询工作通常被某个cpu 绑定,非常容易引起一些非常繁忙的cpu将大部分时间花在软中断/软中断上,而一些cpu则是空闲的.
线程化的NAPI基于工作队列来实现,所有的API几乎相同,除了用netif_threaded_napi_add代替了原来的netif_napi_add.
使用MT7621进行的测试,同时使用线程化的NAPI + 一个用于tx调度的线程可以将LAN->WLAN吞吐量提高10-50%. 没有线程化的NAPI的吞吐量非常不一致,这取决于运行tx调度线程的CPU. 通过测试,线程化的NAPI工作更加稳定.
4. 内存管理
4.1 memcg: Enable fine-grained per process memory control
Memory Controller(cgroup内存控制器)可用于控制和限制任务使用的物理内存。如果使用的物理内存超过限制,Memory Controller会尝试回收内存。通常,Memory Controler可以将占用的物理内存限制在最大值以下。
有时,物理内存回收的速率赶不上分配的速率。在这种情况下,占用的物理内存会持续增加。当达到最大限制或者系统可用内存不足时,将调用OOM Killer杀死某些进程,以释放更多的内存。但是通常无法控制杀死哪个进程,OOM Killer会随机杀死进程。杀死一些拥有重要资源,且还没有释放资源的进程,可能会在之后引起其它的系统问题。
在内存不足时,不希望OOM Killer随机杀死进程的用户,可以通过prctl(2)使用本补丁提供的内存控制工具。本工具可以在超过内存限制时,执行一些缓解措施。
当前支持的缓解措施包括以下内容:
对于分配或处理内存的某些系统调用返回ENOMEM
减慢物理内存回收被消耗赶上的过程
向进程发送特定信号
杀死进程
4.2 huge vmalloc mappings
在定义了 HAVE_ARCH_HUGE_VMAP 和支持 PMD vmaps的平台,让vmalloc会先尝试分配PMD大小的页面,然后在fallback到小的页面,目前只支持带了PAGE_KERNEL参数的分配。
作者在POWER9用`git diff`做了测试,显示TLB misses下降了30倍(59,800 -> 2,100) CPU cycles也减少了0.54%。
当然这个会带来更多的内存浪费,因此加了一个启动参数nohugevmalloc禁止这个行为。
4.3 Support high-order page bulk allocation
有些特殊场景需要批量的分配特定大小的页,比如需要分配
4800 * order-4 pages。当有内存压力时是很难分配到order-4这样的连续
内存页的,一个办法是通过CMA的方式,但是CMA有可能会太慢了:
* 4800 of order-4 * cma_alloc is too slow
这个Patch引入了一个新的函数alloc_pages_bulk()来解决这个问题:
int alloc_pages_bulk(unsigned long start, unsigned long end, unsigned int migratetype, gfp_t gfp_mask, unsigned int order, unsigned int nr_elem, struct page **pages);
5. 文件系统和Block IO
5.1 ext4: add free-space extent based allocator
此patch为ext4文件系统引入了新的multiblock 分配器,即增强版本的空闲块管理策略,旨在加快系统运行速度和加强可拓展性,减少由于分配导致的瓶颈。此patch基于Kadekodi S. 和Jain S.的论文 "Taking Linux Filesystems to the Space Age: Space Maps in Ext4"。
5.2 virtiofs: Add DAX support
这个补丁系列给virtiofs文件系统添加了DAX(Direct Access)特性支持。该特性允许客户机在使用virtiofs文件系统时绕过客户机的页面缓存,同时允许客户机将主机上的页面缓存直接映射到客户机地址空间。
当需要访问一个文件的页面时,客户机会发送一个请求来映射该页面(在主机的页面缓存中)到QEMU地址空间中。从客户机内部看来,这就是一个由virtiofs设备控制的物理内存的一个区域。并且客户机可以使用DAX直接映射这个物理内存区域,从而获得对主机上的文件数据的访问。
在非常多的情况下,这样做可以大大加快访问速度。同时,这样做还可以节省大量内存,因为文件数据不再需要在客户机的页面缓存中保存备份,并且它可以从主机页面缓存中直接被访问。
该补丁系列的大部分修改都局限于fuse/virtiofs两个模块。但是为了能够访问共享内存区域,对通用DAX基础架构和virtio也进行一些修改。
5.3 xfs:解决2038年时间戳上限
在xfs的原先设计中,inode timestamps 是一个 signed 32-bit 的秒计数器,quota timers 是 unsigned 32-bit 的秒计数器,0 都表示 Unix 的纪元 1970年1月1日。
在这样的定义下,inode timestamps 可以表示范围:
-(2^31-1) (13Dec1901) through (2^31-1) (19Jan2038)
quata timers 可以表示时间范围:
0(1Jan1970) through (2^32-1) (7Feb2106).
在2038年,xfs 的 inode 时间戳就没法记录时间了。为了解决这个问题,补丁重新设计了时间戳的定义,加宽了计数范围。补丁把 inode timestamps 调整为 unsigned 64-bit 类型的纳秒计数器,从1901年开始。quota timers 则是 a34-bitunsignedsecond counter right shifted two bits,且 capped at the maximum inode timestamp value。
因此,新的 inode 时间戳范围是:
0(13Dec1901) through (2^64-1/ 1e9) (2Jul2486)
理论上 quota timers 可以达到
0 (1 Jan 1970) through (((2^34-1) + (2^31-1)) & ~3) (16 Jun 2582)
考虑到 quota 最大不超过 inode 时间戳,因此 quota timer最大是:
max((2^64-1 / 1e9) - (2^31-1), (((2^34-1) + (2^31-1)) & ~3) (2 Jul 2486).
5.4 block/bpf:用eBPF实现IO请求的过滤原始的BPF(Berkeley Packet Filter)可用于网络包的过滤,全新的 eBPF(externed BPF)提供了更多的功能,一方面,它已经为内核追踪(Kernel Tracing)、应用性能调优/监控、流控(Traffic Control)等领域带来了激动人心的变革;另一方面,在接口的设计以及易用性上,eBPF 也有了较大的改进。
此补丁的作者利用eBPF实现了IO请求的过滤,在作者提供的的实例中 /samples/bpf/protect_gpt*.c 通过使用IO过滤器阻止写前34个扇区的形式保护GUID分区表。
过滤 IO 的 eBPF 的实例代码如下:
SEC("io_filter")int run_filter(struct bpf_io_request *io_req){ if (io_req->sector_start < GPT_SECTORS && (io_req->opf & REQ_OP_MASK) != REQ_OP_READ) return IO_BLOCK; else return IO_ALLOW;}
为了实现这功能,补丁新增了 eBPF program type BPFPROGTYPEIOFILTER 和 attach type BPFBIOSUBMIT。这功能通过 submit_bio() 的 make_generic_requests_check() 检查 eBPF 程序的返回来判断 IO请求是丢弃( IO_BLOCK)还是接纳( IO_ALLOC)。
5.5 fs:新增支持读写的Linux NTFSWindow有几个广为流传的文件系统,分别是Fat32、NTFS、exFAT,但因为种种原因,在Linux平台上长期以来都没做到完美支持。Linux在很早之前就支持vfat(fat32)的读写了,在前段时间也开源了exFAT的源码,唯独Linux上NTFS只能读不能完美支持写数据。终于,支持读写的 Linux NTFS 要来了。
如补丁作者表述的, Thisisfully functional NTFSRead-Writedriver. 这是一个全功能的NTFS。
6. 网络
本月更新两个方面:
MPTCP中引入SYN Cookie功能,增强网路安全性。
使BPF可以区分MPTCP的字节流,并在tcp的header option中引入BPF功能。
6.1 在MPTCP中引入SYN Cookie功能
MPTCP(MultiPathTCP)是一个还比较年轻的技术,其目的是允许传输控制协议(TCP)连接使用多个路径(比如:主机多地址)来最大化信道资源使用。其核心思想是定义一种在两个主机之间建立连接的方式,而不是在两个接口之间(例如标准TCP)
SYN Cookie是对TCP服务器端的三次握手协议作一些修改,专门用来防范SYN Flood攻击的一种手段。大概原理是在TCP服务器收到TCP SYN包并返回TCP SYN+ACK包时,不分配一个专门的数据区,而是根据这个SYN包计算出一个cookie值。在收到TCP ACK包时,TCP服务器在根据那个cookie值检查这个TCP ACK包的合法性。如果合法,再分配专门的数据区进行处理未来的TCP连接。 在引入中面临着key如何存储来验证他正确的问题,本次采用b方案解决:将nonces存储在某地struct joinentry,用来验证MPJOIN ACK和对应的socket请求。
6.2 BPF
BPF区分TCP sockets and MPTCP subflow sockets.
bpf(Berkeley Packet Filter)伯克利包过滤器,其虽然叫伯克利但针对的却是网络,目的是为了提供一种过滤包的方法,可以通过用户空间经过BPF解析后传给内核。不太熟悉小伙伴可以粗的类比为Thunderbird中的Filter过滤器,去筛选处理邮件。只是BPF要过滤的不是邮件而是网路字节流。后来2013年升级后的版本叫做ebpf主要用于两个领域,一个是内核跟踪和事件监控,另外一个应用领域是网络编程。由于之前BPFPROGTYPESOCKOPS钩子上无法区分普通TCP套接字(TCP sockets)和MPTCP子流套接字(MPTCP subflow sockets),这次提交三个补丁后,可以对子流(subflow)套接字进行精细控制。区分它允许使用BPF程序在来自同一MPTCP连接(套接字标记、TCP拥塞算法等)by BPF programs.bpf-tcp-header-opts: 在之前成功将TCP拥塞控制算法写入BPF一样,可以节约时间去测试/发布新的四种拥塞算法(congestion control algorithm)。现在要把tcp header option引入到BPF中: 增加了新的BPF的API并用BPFPROGTYPESOCKOPS去分析TCP hearder.搞了一个结构体来包含saved_syn,其中0813a84156 ("bpf: tcp: Allow bpf prog to write and parse TCP header option")是核心patch.
7. 虚拟化和容器
7.1 Enable Linux guests on Hyper-V on ARM64
该补丁系列支持将Linux客户操作系统运行在Arm64架构Hyper-V创建的虚拟机里。在arch/arm64/hyperv中新增的arm64特定代码用于Hyper-V虚拟硬件的初始化,包括它的中断和hypercall机制。现有的用于Hyper-V的VMbus和虚拟设备的架构无关驱动程序也可以为Arm64平台进行编译,但也仅仅是可以工作的阶段。Hyper-V的相关代码,只有在CONFIGHYPERV内核配置选项被打开时,才会被编译并包含到内核映像和模块中去。
在Arm64架构的Hyper-V虚拟机中运行Linux客户机需要的工作还有一些地方还在进行中:
Arm64架构的Hyper-V目前运行时的页面大小为4K字节,但允许客户机使用16K或者64K字节大小的页面。然而,在Hyper-V虚拟设备的Linux驱动程序中,客户机系统使用的页面大小被假设为4K字节。这个补丁集为客户机系统使用更大的页面先做一些基础工作,后续会有跟多的补丁来更新这些驱动程序。
Hyper-V vPCI驱动程序(drivers/pci/host/pci-hyperv.c)因为包含有x86/x64特定的代码,并不能在Arm64平台上编译。这个驱动将在晚些时候被修复用以使能Arm64上的vPCI设备。*在一些情况下,来自x86/x64的术语也被带到了Arm64的代码中(“MSR”、“TSC”)。Hyper-V没有使用更通用的术语来替代它们,还是保留使用x86/x64中的术语。这个问题将在Hyper-V 更新TLFS用法时得到解决。
7.2 Remove 32-bit Xen PV guest support
这个计划的长期目标是将Xen PV客户机替换为PVH客户机。现在该计划的第一个受害者出现了,是x86_32位PV客户机,因为这种类型的客户机现在已经很少使用了。目前Xen在x86上需要64位CPU支持,并且从官方版本2.04开始的Grub2已经能正式支持PVH客户机。因此已经没有必要在Linux中继续支持32位的PV客户机。另外,Meltdown的缓解措施在32位的PV客户机上并不可用,因此从安全的角度来看,放弃这种类型的客户机也是有意义的。(译注:不同于Arm,Xen在x86上支持以下3种类型的客户机:PV Guest,HVM和PVH。下图是这三种类型的客户机推出时间线。
PV Guest推出的时间最早,它不依赖于硬件的虚拟化支持,客户机OS通过Xen提供的PV接口完成OS特权操作。HVM伴随着硬件虚拟化技术诞生,客户机OS可以通过硬件提供的虚拟化支持,透明地完成OS特权操作。但是外设仍然需要依赖于QEMU等emulator进行模拟。PVH是最近几年推出的,它仍然需要硬件虚拟化技术支持,但不再依赖QEMU进行设备模拟,而是通过PV driver进行IO操作。PVH具有轻量化高性能的特点,缺点是对旧的OS支持基本没有。)
7.3 HSM driver for ACRN hypervisor
ACRN是一种Type-1类型的虚拟机管理器软件栈,它可以直接运行在裸硬件上,广泛适合于各种物联网和嵌入式设备解决方案。
通过一个特权Service VM,ACRN实现了一个混合虚拟机管理器架构。Service VM管理User VM的系统资源(如CPU、内存等)和I/O设备。它支持多个User VM,每个虚拟机都可以运行Linux、Android或Windows操作系统。Service VM和User VM都是ACRN的虚拟机。下图展示了ACRN的架构。
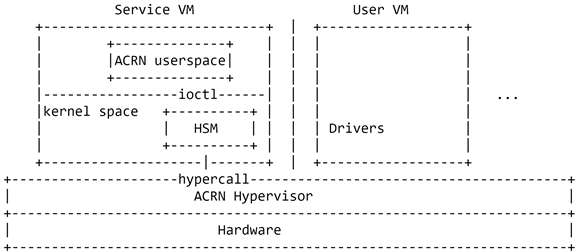
ACRN中只有一个Service VM,它可以运行Linux操作系统。在一个典型的场景,Service VM伴随着ACRN Hypervisor启动时自动启动。然后运行在Service VM中的ACRN userspace可以通过与ACRN Hypervisor服务模块 (HSM,Hypervisor Service Module )通信来启动/停止User VM。ACRN Hypervisor服务模块(HSM)类似一个中间件,它允许ACRN userspace和Service VM操作系统内核与ACRN Hypervisor通信并管理不同的User VM。这个中间件层提供以下功能:-向hypervisor发出hypercall来管理User VM:
VM /vCPU的管理
内存的管理
设备透传
中断注入 -处理User VM发出的I/O请求。-通过HSM 字符设备导出ioctl接口 -导出函数给内核其它模块调用 因为ACRN聚焦于嵌入式设备,所以它也不支持某些特性。比如
ACRN不支持虚拟机迁移
ACRN不支持CPU迁移 该补丁向内核添加ACRN Hypervisor服务模块 (HSM,Hypervisor Service Module )代码。
7.4 mm/virtio-mem: support ZONEMOVABLE
在之前引入virtio -mem的时候,ZONEMOVABLE的语义在当时是相当地不明确,这就是为什么我们需要特别处理ZONEMOVABLE,因为这样可以防止部分插入的内存块出现在ZONEMOVABLE中。
但是现在,ZONEMOVABLE的语义变得更清楚了(我们在patch#6中对它做了文档说明),所以我么可以开始在ZONEMOVABLE中支持部分插入的内存块,允许部分插入的内存块在ZONE_MOVABLE上线和断开。这样可以避免内存块的上线时突然失败的意外,因为virtio-mem还没有将它们完全填充完毕。
这对测试特别有用,但同时也为virtio-mem的优化铺平了道路,允许更多内存被可靠地断开。清理hasunmovablepages()和setmigratetypeseparation()两个函数。在文档中更好地描述了ZONEMOVABLE是如何与不同类型的不可移动页面交互的(memory offlining vs. alloccontig_range())。
7.5 Support virtio cross-device resources
这个补丁集是按照链接[1]中的提案实现了VIRTIO跨设备的资源共享。他将会被用于将VIRTIO资源导入到VIRTIO-VIDEO驱动中。VIRTIO-VIDEO驱动还在讨论中,可以参考链接[2]。链接[3]是正在考虑的在VIRTIO-VIDEO驱动程序中添加支持的补丁。它正在使用的API是这个补丁集的v3版本,但是更新它所做的更改相对来说不会太多。这个补丁集新增了一种dma-bufs,它支持查询底层virtio对象的UUID,同时支持从virtgpu导出资源。
[1] https://markmail.org/thread/2ypjt5cfeu3m6lxu
[2] https://markmail.org/thread/p5d3k566srtdtute
[3] https://markmail.org/thread/j4xlqaaim266qpks
7.6 KVM:Add virtualization support of split lock dection
这个补丁系列的目标是在KVM中添加split lock detection的虚拟化支持。(译注:split lock是一种内存或者总线锁,一旦一个CPU使用该锁,其它的CPU或者设备都无法访问内存或者总线)。因为split lock detection的实现是和CPU型号紧耦合的,而虚拟机的CPU型号又是由VMM配置的。因此我们选择采用半虚拟化的方式来向客户机暴露并列举CPU的型号。
7.7 KVM: PKS Virtualization support
这个RFC补丁系列引入了KVM对PKS的支持,补丁中有些定义依赖于PKS内核补丁。
PKS (Protection Keys for Supervisor Pages,特权页面的保护密钥)是保护密钥体系架构的一个扩展特性,用于以支持限制特定线程在特权页面上的访问权限。(译注:PKS将内核地址空间中的每个页面和一个Protection Key关联起来。Protection Key一共16个,因此内核页面被划分为16个区域,每个区域都可以独立配置权限。修改这些区域的权限策略会比直接修改这些页面的权限设置会更加高效)
PKS的工作原理与现有的PKU(用户页面保护)相似。它们都是在系统完成原有的访问权限检查之后再执行一个额外的检查。如果访问权限被违反了,则会触发#PF并且PFEC.PK状态位将被设置。PKS引入MSR IA32PKRS来管理特权页面保护密钥的权限。MSR包含16对ADi和WDi位。每一对ADi/WDi可以将权限通知到整组具有相同PKS密钥的页面中,该密钥被保存在页表项的bits[62:59]。目前IA32PKRS并没有被XSAVES架构支持。这个补丁集的目的是在KVM中添加PKS的虚拟化支持。它实现了PKS CPUID枚举,vmentry/vmexit配置,MSR公开,嵌套虚拟化的支持等。目前,PKS还不支持影子页表。关于PKS的详细信息可以在最新的“Intel 64 and IA-32 Architectures Software Developer's Manual”手册中找到。
(END)
Linux阅码场原创精华文章汇总
更多精彩,尽在"Linux阅码场",扫描下方二维码关注
