| 1.Hive基本操作:建库、建表、查询 Hive提供了一个被称为Hive查询语言(简称HiveQL或是HQL)的SQL方言,其语法基本与MySql一致,比较容易上手,因为大多数的开发工程师对MySql很熟悉。 1.1建库: create database mydb; 
在上一篇的介绍中,我们将Hive使用了远程Mysql来存放元数据metastore信息。元数据存储中存储了如表的模式和分区(后面我们接着讨论分区)信息等数据信息。用户在执行如create table x...或者alter table y...或者create database...等命令时会指定这些信息。因为多用户和系统可能需要并发访问元数据存储,所以默认的内置数据库并不适用于生产环境。我们之前通过在Mysql创建hive数据库来存放数据元信息,现在我们就来查看一下在Hive中创建了数据库mydb的元数据信息 
如图所示,我们看到Mysql的hive数据库中的dbs表存放的是Hive仓库中创建数据库的元数据信息,包括数据库的名称,以及这个数据库的所在地址,注意看,数据库的所在地址在hdfs://s10/user/hive/warehouse/mydb.db,其中/user/hive/warehouse是我们在hive-site.xml的配置中:  属性hive.metastore.warehouse.dir告诉Hive在本地的文件系统中使用的是哪个路径来存放Hive表中的数据。(这个值会追加到Hadoop配置文件中所配置的属性fs.defaultFS的值也就是我们之前搭建Hadoop集群中配置的core-site.xml)  所以也就是hdfs://s10/user/hive/warehouse/mydb.db我们注意到,这是一个目录,并且存储在了Hadoop的分布式文件系统HDFS上。 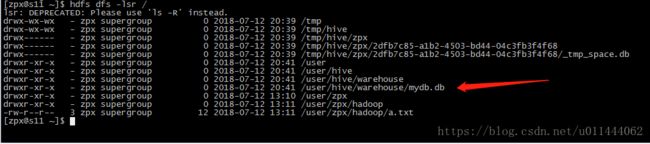
我们也可以直接在Hive的命令行CLI上直接查看,速度可能会快点 
1.2建表(并非完整的建表语句,后面继续讨论)  表建完之后我们我们试使用insert into插入一行数据,注意平时我们一般不是用insert ion的方式进行插入数据,我们会发现他启动的是MapReduce来完成数据额添加而是使用load的方式,此处只是想说一下Hive安装完成之后的基本使用,后面会具体的描述完成建表,插入数据
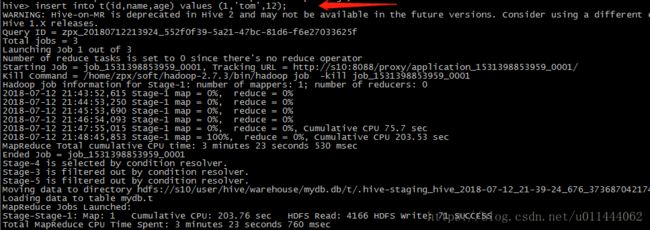 数据添加完成之后,我们到Mysql的hive数据库中看一下, 在tbls表中可以查看到表的元数据,发现有一栏TBL_TYPE,值是MANAGED_TABLE(管理表)。在Hive中的表有两种,一直是管理表,一种是外部表,外部表的建表语句是create external table xx...。主要的区别如下: 1.managed table
管理表。
删除表时,数据也删除了。
2.external table
外部表。 删除表时,数据不删。 也就是说外部表中仅仅只是具有元数据,而真实的数据并不是在这张表,在文件系统的其他地方,我们只是创建外部表,然后使用类SQL的语句HQL去操纵数据,删除表的时候,真实数据并没有被删除,仍然存在文件系统中,这种方式比较的安全。

 表建好了,也有了数据,根据建库一样,我们来看看表在哪里,使用dfs -lsr /;来查看。发现这张表存放在了Hadoop的分布式文件系统HDFS上,路径仍然是hdfs://s10/user/hive/warehouse/mydb.db/t,发现,这张表仍是一个目录。
 1.3查询: 使用select * from t;来查看一下数据:
 总结:Hive使用类SQL的方式,提供一种叫做HQL的查询语言(跟SQL极其相似),然后让用户,工程师直接使用查询语言(只要熟悉Mysql就可以)操纵数据,其底层如果涉及到了MapReduce会自行调用,就不用我们来写MaprReduce的Mapper函数和Reducer函数了。我们只需要把在需要的数据上建库,建表就可以。Hive仓库中创建的库,表,都是存放在Hadoop分布式文件系统的目录结构,提供管理表和外部表两种形式供使用。 2.使用API通过JDBC连接访问 我们使用的Hive命令行也就是CLI,只能在服务器上也就是按照了Hive的主机上使用,而且不能两个一起用,如果开启了一个Hive然后再起一个就会阻塞掉,不支持并发访问。我们不能一直在Hive服务器下进行操作,那怎么处理呢?Hive提供了远程Thrift Server能够提供并发访问,并且可以支持远程连接。我们知道远程连接,一个会是套接字Socket连接,那Hive的远程连接是什么情况呢? 我们来到Hive的安装目录bin下,查看一下Hive的帮助,

 我们发现在这里边,Hive其实是通过 hive --service来开启一个服务,如果什么都没有加,其实开启的是命令行服务,也就是CLI,等价于hive --service cli
 那么Hive的远程连接服务叫什么呢?叫做hiveserver2,hiveserver2启动的服务就是专门针对远程的服务进行套接字连接访问的机制其端口号默认是10000,我们在bin目录下来查看一下,使用命令cat hiveserver2

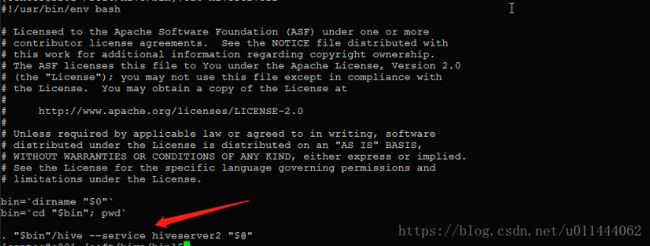 我们可以通过hiveserver2直接运行或是使用hive --service hiveserver2来开启 hive还为我们提供了一个叫做beeline的工具与hive的CLI命令行一样,只是beeline可以连接到hiveserver2(其实就是一个能连接到提供远程服务hive上的命令行,并且支持并发访问),启动方式与hiveserver2一样,可以直接beeline或是使用hive --service beeline来开启。 通过beeline方式连接到远程hive数据仓库
--------------------------------
1.启动hiveserver2服务器,监听端口10000
$>hive --service hiveserver2 & //后台运行
2.通过beeline命令行连接到hiveserver2
$>beeline //进入beeline命令行(于hive --service beeline)
$beeline>!help //查看帮助
$beeline>!quit //退出
$beeline>!connect jdbc:hive2://localhost:10000/mydb//连接到hibve数据
$beeline>show databases ;
$beeline>use mydb ; $beeline>show tables; //显式表 Hive的进程是RunJar。说明我们已经开启了Hive,只不过是支持远程连接,并且端口号10000也已经被监听。

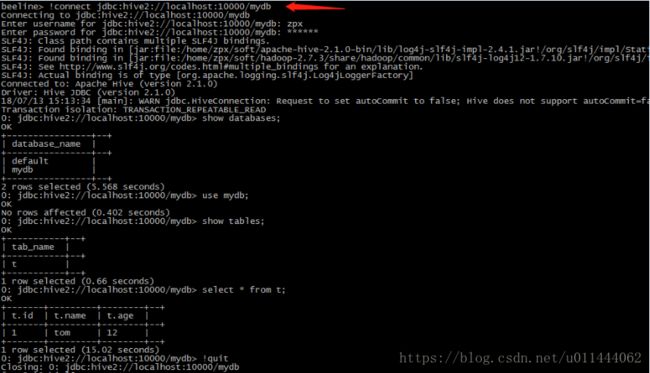 使用Hive-jdbc驱动程序采用jdbc方式访问远程数据仓库
----------------------------------------------------
1.创建java模块
2.引入maven
3.添加hive-jdbc依赖
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
com.it18zhang
HiveDemo
1.0-SNAPSHOT
org.apache.hive
hive-jdbc
2.1.0
4.App
package com.hadoop.hivedemo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
/**
* 使用jdbc方式连接到hive数据仓库,数据仓库需要开启hiveserver2服务。
*/
public class App {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn = DriverManager.getConnection("jdbc:hive2://192.168.100.10:10000/mydb");
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("select id , name ,age from t");
while(rs.next()){
System.out.println(rs.getInt(1) + "," + rs.getString(2)) ;
}
rs.close();
st.close();
conn.close();
} } 注意:Hive不是关系数据库,不是OLTP(实时事务处理),而是OLAP(实时分析处理),不能实时查询和行级更新。 |