MySql准实时同步数据到HDFS(单机版)
一、方案
MySql->Maxwell->Kafka->Flume->HDFS
按照这个顺序新搭建一套环境。
主要参考地址(感谢):
https://blog.csdn.net/hyb1234hi/article/details/80424971
二、环境
Linux:CentOS7
下载地址:http://mirrors.aliyun.com/centos/7.8.2003/isos/x86_64/
各个版本的ISO镜像文件说明:
CentOS-7-x86_64-DVD-1708.iso 标准安装版(推荐)
CentOS-7-x86_64-Everything-1708.iso 完整版,集成所有软件(以用来补充系统的软件或者填充本地镜像)
CentOS-7-x86_64-LiveGNOME-1708.iso GNOME桌面版
CentOS-7-x86_64-LiveKDE-1708.iso KDE桌面版
CentOS-7-x86_64-Minimal-1708.iso 精简版,自带的软件最少
CentOS-7-x86_64-NetInstall-1708.iso 网络安装版(从网络安装或者救援系统)
Jdk:jdk-8u181-linux-x64.tar.gz
Zk:apache-zookeeper-3.5.5-bin.tar.gz
下载地址(包含hdfs所用到的所有组件,根据需要下载):
链接:https://pan.baidu.com/s/1XxBdG8mhkTUnIvlkjbFwnQ
提取码:az2j
Mysql:5.6.26(为了跟我这边生产一致)
下载地址:https://downloads.mysql.com/archives/community/
Maxwell:1.27.0
下载地址:
源码地址:https://gitee.com/mirrors/Maxwell.git
Apache官网(下面三个都是在官网找的下载地址):https://www.apache.org/
Kafka:2.13-2.5.0
下载地址:https://mirror.bit.edu.cn/apache/kafka/2.5.0/kafka_2.13-2.5.0.tgz
Flume:1.9.0
下载地址:
https://mirror.bit.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
Hadoop:3.3.0
下载地址:
https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
三、各组件安装
安装之前先配个映射关系吧:
不建议用默认的localhost,可能会与本机windows的localhost冲突,
Vim /etc/hosts
添加映射关系:

上面两个是自带的,下面这个是新加的,ip 对应 名称 ,这个名称自己随便起个就行。然后在修改本机windows的hosts文件,也配置个同样名称和ip的映射关系:
路径:C:\Windows\System32\drivers\etc\hosts
新加一行:

10.39.251.123就是我安装hadoop服务器的ip,这样后面直接访问psb-tt-123就行了。
1、jdk安装
a)、上传
由于安装Kafka和HDFS需要jdk,所以首先给jdk安装上:
在/usr/local/soft/jdk目录下上传jdk8的包(路径根据自己喜好设置;如果跟本文一致,对应的路径没有则创建)
使用rz命令,弹窗-> 选择
jdk-8u181-linux-x64.tar.gz
b)、解压
使用解压命令:
tar -zxvf jdk-8u181-linux-x64.tar.gzc)、配置
解压完成配置环境变量:
vim /etc/profile添加下面几行:
export JAVA_HOME=/usr/local/soft/jdk/jdk1.8.0_181
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:JRE_HOME/bin:$PATH使配置文件生效:
source /etc/profiled)、验证
验证安装是否成功:
java -version
2、zookeeper安装
由于kafka需要用到zookeeper,所以先把zookeeper安装上。
a)、上传
在/usr/local/soft/zookeeper目录下上传apache-zookeeper-3.5.5-bin.tar.gz的包(路径根据自己喜好设置;如果跟本文一致,对应的路径没有则创建)
使用rz命令,弹窗-> 选择
apache-zookeeper-3.5.5-bin.tar.gz
b)、解压
使用解压命令:
tar -zxvf apache-zookeeper-3.5.5-bin.tar.gzc)、配置
解压完成配置环境变量:
cd 到conf目录,然后使用cp命令copy一份配置文件,zk默认加载zoo.cfg名称的配置文件: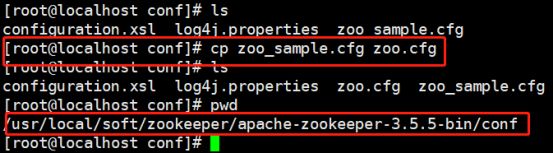
修改下配置文件里的这个路径:
![]()
d)、启动
./zkServer.sh start ../conf/zoo.cfg
使用zkCli.sh登录:

创建一个kafka目录,给下面kafka连接时使用:

使用ls命令查看是否创建成功:

小技巧:所有不清楚命令的,各种输入help来看看命令帮助:

3、Mysql安装
①、在/usr/local/soft/mysql目录下上传msyql的server包和client包(路径根据自己喜好设置;如果跟本文一致,对应的路径没有则创建)
使用rz命令,弹窗-> 选择
MySQL-client-5.6.26-1.el7.x86_64.rpm、MySQL-server-5.6.26-1.el7.x86_64.rpm
这两个包,上传完成。
②、卸载MariaDB(CentOS7默认自带)
a)、检查是否安装了mysql
centos7默认是安装的mariadb,而安装mysql的话会和mariadb的文件冲突,所以需要先卸载掉mariadb
rpm -qa|grep -i mysql检查是否安装了mysql
如果有默认安装的mysql,一般是下面这样,最多版本号不同

我的版本是这样的(我CentOS7下载的是精简版的1.0G的大小,连基本的命令都没有的那种)

b)、卸载默认安装的mysql
rpm -e --nodeps强制删除mariadb的所有相关软件包

c)、安装client
rpm -ivh MySQL-client-5.6.26-1.el7.x86_64.rpm
d)、安装server
rpm -ivh MySQL-server-5.6.26-1.el7.x86_64.rpm
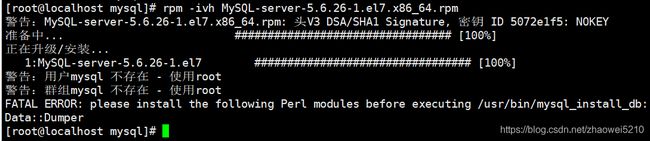
我这里没有新建mysql用户组和对应的mysql用户,直接使用root用户
报错:FATAL ERROR: please install the following Perl modules before
executing ./scripts/mysql_install_db:
Data::Dumper
解决办法:
yum -y install autoconfe)、启动
service mysql start![]()
find / -name *localhost.localdomain.*在全盘搜索localhost.localdomain.err文件
![]()
查看错误日志:
less /var/lib/mysql/localhost.localdomain.err
shift + g #跳到文件最后一行Can't open and lock privilege tables: Table 'mysql.user' doesn't exist
![]()
可能在安装时没有初始化好,使用下面命令初始化一下:
mysql_install_db --user=mysql初始化完成再次启动:
![]()
f)、账户和权限配置
由于安装完成后没有配置用户名和密码,又在本机上,所以直接用msyql登录:

show databases;查看有哪些数据库:
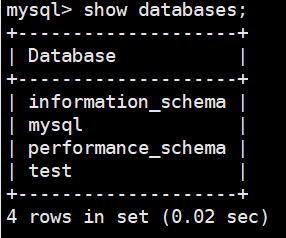
information_schema:保存关于mysql服务器所维护的所有其他数据库的信息,如数据库名,数据库的表,表栏的数据类型与访问权限等。
performance_schema:用于收集数据库服务器性能参数。
mysql:存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息。
test:测试库。
切换数据库:
use mysql
可以使用select * from user\G;查看到root用户都是没有密码的;首先来更新root密码,个人设置为root;
set password for root@localhost = password('root');然后用exit退出:

此时在直接使用msyql是登录不上了,需要添加密码参数:
mysql -h127.0.0.1 -p3306 -uroot -proot
h: host p:port u:user p:password

切换数据库,创建一个maxwell用户,用户数据同步:
use mysql;![]()
再用select * from user\G;便能看到maxwell用户了。
给maxwell用户授权:
GRANT ALL on maxwell.* to 'maxwell'@'%' identified by 'maxwell';
GRANT ALL on maxwell.* to 'maxwell'@'localhost' identified by 'maxwell';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'localhost';
刷新权限:
flush privileges;背景:mysql中删除又想重建maxwell用户,但是执行创建命令报错。
解决方法:
drop user maxwell@localhost;
flush privileges;
create user maxwell@localhost identified by 'maxwell';
g)、创建表
创建一个需要同步数据的表,切换数据库:
use test;创建表:
CREATE TABLE tbox_location_info (
`id` INT (32) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`terminal_phone` VARCHAR (15) DEFAULT NULL COMMENT '终端手机号',
`latitude` VARCHAR (10) DEFAULT NULL COMMENT '纬度',
`longitude` VARCHAR (10) DEFAULT NULL COMMENT '经度',
`ls_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '位置所属时间',
`total_mileage` VARCHAR (10) DEFAULT NULL COMMENT '当前位置车辆累计行驶里程(km)',
`created_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`, `ls_time`),
KEY `terminalPhone_idx` (`terminal_phone`) USING BTREE,
KEY `lsTime_idx` (`ls_time`) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
查询一下这个表:

h)、mysql配置
先关闭msyql:
service mysql stop![]()
全路径搜索msyql配置文件:
find / -name *my.cnf*
添加配置:
vim /usr/my.cnf
server-id=1
log-bin=master
binlog_format=row
binlog_row_image=FULL
esc -> :wq 保存
重新启动:
service mysql start解释:
log-bin=master --开启binlog,binlog日志文件名称前缀为master,实际文件名是:master.000001这种
binlog_format=row --binlog格式为row
3、Maxwell安装
a)、上传
在/usr/local/soft/maxwell目录下上传maxwell的maxwell-1.26.1.tar.g包(路径根据自己喜好设置;如果跟本文一致,对应的路径没有则创建)
使用rz命令,弹窗-> 选择
maxwell-1.26.1.tar.gz包,上传完成。
b)、解压:
tar -zxvf maxwell-1.26.1.tar.gz解压完成:

c)、启动
Maxwell存储在MySQL服务器本身所需要的所有状态,在schema_database选项指定的数据库中。默认情况下, 数据库被命名为maxwell。
默认是本机msyql,可以查看maxwell下的config目录下的
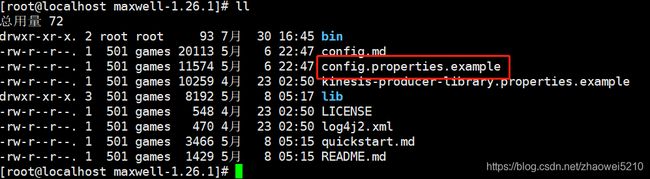
这个文件:
![]()
应该可以修改配置文件,然后启动加载指定的配置文件就能连到其他服务器上的mysql,我没试过,因为我搭建的都是在一台服务器上。
启动maxwell:
./maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --port='3306' --producer=stdout
d)、测试
在mysql里插入一条数据,查看日志:
![]()
![]() 可以看到maxwell日志里已经有了mysql插入的那条数据,好了maxwell能连上mysql了。注意看created_time字段同步过来的少了8个小时,这是因为maxwell的问题。
可以看到maxwell日志里已经有了mysql插入的那条数据,好了maxwell能连上mysql了。注意看created_time字段同步过来的少了8个小时,这是因为maxwell的问题。
参考地址:https://github.com/zendesk/maxwell/issues/903
下面自己clone maxwell源码修改下源码后重新编译打包:
给个码云的地址(github的太慢而且下载到90%的时候卡住后下载失败):
https://gitee.com/mirrors/Maxwell.git
clone到本地后(目前是1.27.0版本),idea导入,修改pom文件:
(我注释了profile下kafka版本不是1.0.0的所有其他版本,因为它报错了)
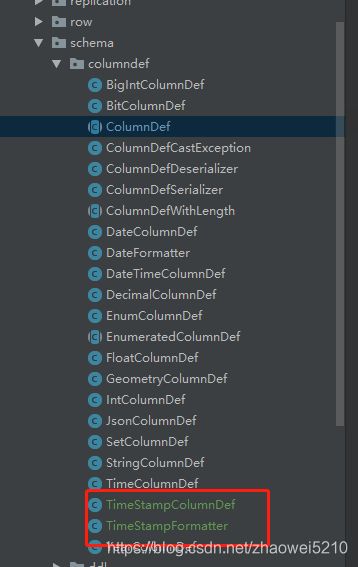
对应的java类也是从这里下载的,版本不同,需要稍微修改下:
类:
 修改的地方:
修改的地方:

下面两个类是新增:
把项目压缩成zip上传到linux服务器,然后unzip解压,cd进入到项目根路径,然后执行mvn clean , mvn compile(可选), mvn -Dmaven.test.skip=true package,打成的包在target目录下,cd到target目录下,copy出maxwell-1.27.0.tar.gz到maxwell下,然后tar -zxvf maxwell-1.27.0.tar.gz,在cd到maxwell-1.27.0下的bin目录下,chmod 777 maxwell maxwell-benchmark maxwell-bootstrap maxwell-docker 赋予权限,执行sed -i 's/\r$//' maxwell,替换windows与linux的换行符不同差异(linux:结尾是\n,windows:结尾是\n\r)
(不执行替换命令直接执行maxwell命令可能会出现:/bin/bash^M: 坏的解释器: 没有那个文件或目录,参考地址:https://blog.csdn.net/mingzznet/article/details/12524527)
再执行:
./maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --port='3306' --producer=stdout在mysql插入一条数据:
附一条插入sql:insert into tbox_location_info(terminal_phone,latitude,longitude,ls_time,total_mileage,created_time)values('010090452566','36.287276','120.3644','2020-09-10 11:26:59','4525.26','2020-09-10 11:27:09');![]()
maxwell窗口查看:
![]()
ok,时间对了,上面给的maxwell1.27.0的包是我已经修改好的了,直接解压就能用。
3、Kafka安装
a)、上传
在/usr/local/soft/kafka目录下上传kafka的kafka_2.13-2.5.0.tgz包(路径根据自己喜好设置;如果跟本文一致,对应的路径没有则创建)
使用rz命令,弹窗-> 选择
kafka_2.13-2.5.0.tgz,上传完成。
b)、解压
解压:
tar -zxvf kafka_2.13-2.5.0.tgzc)、配置
三个地方,其他默认就好:

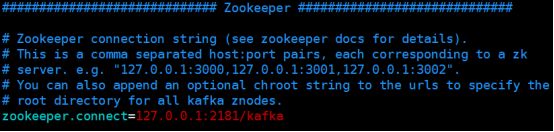
ps:如果没配置好,就启动然后在zk留下记录后,需要重新配置然后删除如下目录:

的所有文件,然后在重启。(kafka默认使用的是zk的根目录)
查看topic:

常规命令:
#常规模式启动kafka
bin/kafka-server-start.sh config/server.properties
#进程守护模式启动kafka
nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &
#Kafka关闭命令(备注:先进入kafka目录)
bin/kafka-server-stop.sh
#创建topic
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181/kafka --replication-factor 1 --partitions 5 --topic maxwell
#删除topic
bin/kafka-topics.sh --zookeeper 127.0.0.1:2181/kafka --delete --topic maxwell
#查看topic列表
bin/kafka-topics.sh --list --zookeeper=127.0.0.1:2181/kafka
#查询topic内容:
#bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic maxwell --from-beginningd)、启动
常规模式启动(ctrl+z退出后服务关闭):
./kafka-server-start.sh ../config/server.properties后台进程启动(ctrl+z退出后服务还在):
nohup ./kafka-server-start.sh ../config/server.properties &可以使用tail -200f nohup.out查看启动日志。

能正常启动,有可能启动会报错:

内存不足(由于我虚拟机就给了1个G,可能内存不足了),修改kafka-server-start.sh文件配置:
vim kafka-server-start.sh
这里本来默认是1G的,调小点。在启动,如果还内存不足,调整为128m试试。
e)、测试前准备
创建一个topic:
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181/kafka --replication-factor 1 --partitions 5 --topic maxwell
查看topic:
./kafka-topics.sh --describe --zookeeper 127.0.0.1:2181/kafka --topic maxwell
然后停止maxwell,重新启动,maxwell订阅kafka的topic(进入maxwell的bin目录):
后台进程启动:
nohup ./maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --port='3306' --producer=kafka --kafka.bootstrap.servers=127.0.0.1:9092 --kafka_topic=maxwell &![]()
不知道为何我重启后出现了maxwell记录的同步position和mysql的binlog位置不一致:
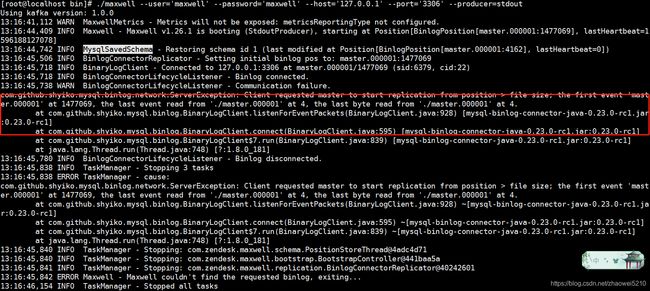
经过一番查找,发现maxwell有个启动参数(正常启动不需要带上):
--init_position=master.000001:0:0,指定当次启动从哪个binlog的哪一行同步。在maxwell包的下有一个config.md文件,里面有参数说明:

![]()
这里还有个quickstart.md,里面有关于mysql、maxwell、kafka、redis等配置:

使用后台进程守护模式启动:
nohup ./maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --port='3306' --producer=kafka --kafka.bootstrap.servers=127.0.0.1:9092 --kafka_topic=maxwell --init_position=master.000001:0:0 &因为是测试环境init_position具体文件位置都是随便填的,这个参数看情况加不加,加的话具体position位置需确定。

f)、测试
①、mysql插入一条数据:
![]()
查看kafka的窗口:
![]()
Kafka已经有mysql的插入数据了。
②、mysql更新一条数据:

![]()
③、mysql删除一条数据:

![]()
4、flume安装
参考地址:
https://www.cnblogs.com/zxf330301/p/8317371.html
https://www.cnblogs.com/Gxiaobai/p/13213303.html
https://blog.csdn.net/weixin_38963816/article/details/80358273
a)、上传
在/usr/local/soft/flume目录下上传flume的apache-flume-1.9.0-bin.tar.gz包(路径根据自己喜好设置;如果跟本文一致,对应的路径没有则创建)
使用rz命令,弹窗-> 选择
apache-flume-1.9.0-bin.tar.gz,上传完成。
b)、解压
解压:
tar -zxvf apache-flume-1.9.0-bin.tar.gzc)、配置
首先查看下版本号,看是否安装成功:

copy一份配置文件并重命名:

编辑该配置文件:
vim flume-conf.properties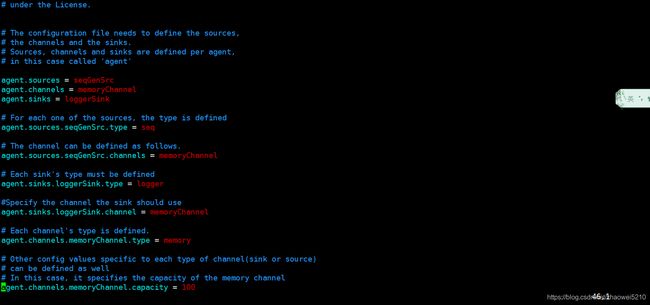
上面是修改前,下面是修改后:

增加内容:
#定义别名
#对channel而言,相当于生产者,通过接收各种格式数据发送给channel进行传输
a1.sources=r1
#相当于数据缓冲区,接收source数据发送给sink
a1.channels=c1
#对channel而言,相当于消费者,通过接收channel数据通过指定数据类型发送到指定位置
a1.sinks=k1
# 配置sources
#配置flume自定义过滤器,com.zw.cn.flume.MyInterceptor是自定义的过滤器类
#a1.sources.r1.interceptors = i1
#a1.sources.r1.interceptors.i1.type = com.zw.cn.flume.MyInterceptor$Builder
#定义消息源类型
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
#kafka地址
a1.sources.r1.kafka.bootstrap.servers = 127.0.0.1:9092
#定义kafka所在zk的地址
a1.sources.r1.kafka.zookeeperConnect = 127.0.0.1:2181
#配置消费的kafka topic,可以使用正则匹配
#a1.sources.r1.kafka.topics.regex = ^topic_app_.*$
a1.sources.r1.kafka.topics = maxwell
# 配置channel
# channel类型,内存类型
a1.channels.c1.type=memory
# channel存储的事件容量
a1.channels.c1.capacity=10000
# 事务容量
a1.channels.c1.transactionCapacity=1000
# 配置sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /test/%Y%m%d
a1.sinks.k1.hdfs.path = /tbox/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = tbox_location_info
#基于时间间隔来进行文件滚动,默认是30,即每隔30秒滚动一个文件。0就是不使用这个策略。
a1.sinks.k1.hdfs.rollInterval = 0
## 触发滚动文件大小(byte) 如果记录的文件大于104857600字节(100M)时切换一次
#基于文件大小进行文件滚动,默认是1024,即当文件大于1024个字节时,关闭当前文件,创建新的文件。0就是不使用这个策略。
a1.sinks.k1.hdfs.rollSize = 104857600
#基于event数量进行文件滚动。默认是10,即event个数达到10时进行文件滚动。0就是不使用这个策略。
a1.sinks.k1.hdfs.rollCount = 0
#闲置N秒后,关闭当前文件(去掉.tmp后缀)。
a1.sinks.k1.hdfs.idleTimeout = 0
## 使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream:为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# 绑定channel-source, channel-sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1后台启动(bin目录):
nohup ./flume-ng agent --conf /usr/local/soft/flume/apache-flume-1.9.0-bin/conf --conf-file /usr/local/soft/flume/apache-flume-1.9.0-bin/conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console &Mysql插入一条数据,发现flume报错如下:

看这情况就是jar包冲突了,是flume依赖的guava.jar与hadoop里依赖的jar版本不一致,因为我提前安装了hadoop,所以用hadoop里依赖的guava包替换掉flume安装的guava.jar。

上面的替换下面的。
rm -rf /usr/local/soft/flume/apache-flume-1.9.0-bin/lib/guava-11.0.2.jar
cp /usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/soft/flume/apache-flume-1.9.0-bin/lib/
参考地址:https://blog.csdn.net/GQB1226/article/details/102555820
已经替换掉了,再重启下,mysql在插入一条数据:

可以看到已经有数据过来,只不过我没启动hadoop,连接hadoop没连接上报错了,湖面有安装hadoop。
d)、flume自定义过滤器
参考地址:

把这两行放开注释。
随意新建个maven项目,引入基本的spring的jar包,在引入下面这个包:
新建类实现上面包的Interceptor接口:

整个类内容:
package com.zw.cn.flume;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.eclipse.jetty.util.StringUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
/**
* @Description: 自定义flume拦截器类型
* @Author: zhaowei
* @Date: 2020/7/29
* @Time: 14:46
*/
public class MyInterceptor implements Interceptor {
private static final Logger logger = LoggerFactory.getLogger(MyInterceptor.class);
/**
* 初始化放在,最开始执行一次
* 把配置的数据初始化到map中,方便后面调用
*/
@Override
public void initialize() {
}
/**
* 具体的处理逻辑
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
try{
String origBody = new String(event.getBody());
logger.info("origBody:{}", origBody);
if(StringUtil.isNotBlank(origBody)){
String newBody = JSON.toJSONString(JSONObject.parseObject(origBody).get("data"));;
event.setBody(newBody.getBytes());
logger.info("newBody:{}", newBody);
}
}catch (Exception e){
logger.error("拦截器处理失败!:", e);
}
return event;
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new MyInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public List intercept(List list) {
for (Event event : list) {
intercept(event);
}
return list;
}
@Override
public void close() {
}
} 把该文件打包成jar包,放在flume的lib文件下:

rz 上传,打包成的jar文件:myInterceptor.jar
然后重启flume,mysql插入一条数据测试:
![]()
flume查看:

可以看到我们自定义的拦截器里打印的日志,已经获取到我们想要的data里的数据了。
5、hadoop安装
有些系统上需要关闭防火墙,我这边是安装的精简版没有防火墙。
a)、上传
在/usr/local/soft/hadoop目录下上传hadoop的hadoop-3.3.0.tar.gz包(路径根据自己喜好设置;如果跟本文一致,对应的路径没有则创建)
使用rz命令,弹窗-> 选择
hadoop-3.3.0.tar.gz,上传完成。
b)、解压
解压:
tar -zxvf hadoop-3.3.0.tar.gzc)、配置
$ vim /etc/profile # 添加hadoop_home,以及/bin;/sbin路径
export HADOOP_HOME=/usr/local/soft/hadoop/hadoop-3.3.0 #hadoop安装目录,就是解压后的目录
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/jre/bin:$PATH
$ source /etc/profile # 使环境变量生效查看是否安装成功
[root@new-frame-251 hadoop]# hadoop version
Hadoop 3.3.0
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af
Compiled by brahma on 2020-07-06T18:44Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
This command was run using /usr/local/soft/hadoop/hadoop-3.3.0/share/hadoop/common/hadoop-common-3.3.0.jar①、/usr/local/soft/hadoop/hadoop-3.3.0目录下新建一个tmp目录,tmp目录下新建data和name两个目录(注意两个目录的文件权限)
②、修改/usr/local/soft/hadoop/hadoop-3.3.0/etc/hadoop目录下core-site.xml文件
fs.defaultFS
hdfs://psb-tt-123:9000
hadoop.tmp.dir
/usr/local/soft/hadoop/hadoop-3.3.0/tmp
③、修改/usr/local/soft/hadoop/hadoop-3.3.0/etc/hadoop目录下hdfs-site.xml文件
dfs.replication
1
dfs.namenode.name.dir
/usr/local/soft/hadoop/hadoop-3.3.0/tmp/name
dfs.datanode.data.dir
/usr/local/soft/hadoop/hadoop-3.3.0/tmp/data
④、修改/usr/local/soft/hadoop/hadoop-3.3.0/etc/hadoop目录下hadoop-env.sh文件
JAVA_HOME=/opt/jdk1.8.0_211d)、SSH免密登录
cd ~/.ssh/ #若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys #加入授权
chmod 600 ./authorized_keys #修改文件权限e)、启动
第一次启动前需要格式化一下: ./hadoop namenode -format
然后:start-dfs.sh
可能报错:

解决办法:
在Hadoop安装目录下找到sbin文件夹,在里面修改2个文件
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root重新start-dfs.sh启动,检测是否启动成功: jps

f)、测试
Mysql插入两条数据:

查看flume窗口:
![]()
hadoop命令查看该文件内容:
![]()
在访问hadoop的web页面:
http://psb-tt-123:9870(已经配置好的映射关系),这里浏览器可能还需要设置下跨域访问,我用的谷歌浏览器,网上跨域一大堆。
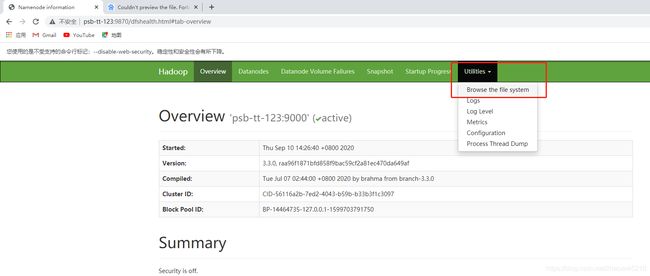

已经有对应的目录了,点进去:
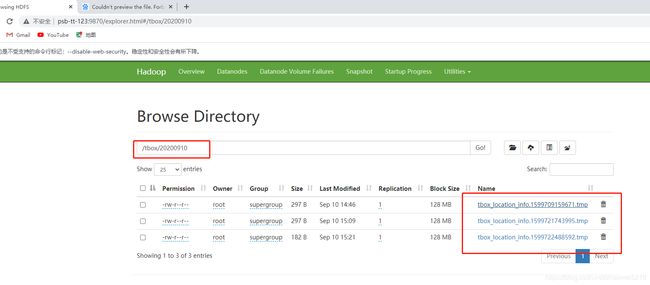
在随便点击一个然后可以查看文件部分内容,也可以下载下来:
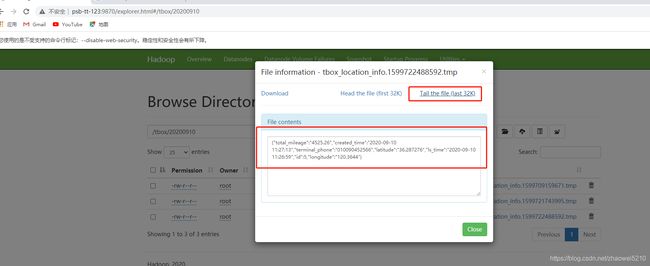
我这里已经设置过过滤器了,如果没设置,数据有了,但是我们可能只想要data里的json,原有结构如下:
![]()
其他的信息是库、表、数据类型(增删改)等。看实际需求,如果需要过滤,则需要修改下flume,自定义一个过滤器,请看下flume模块的自定义过滤器。
此次用到的命令,其实只需要看help就行了:
hadoop shell 命令官网:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
hadoop学习地址:https://blog.csdn.net/anaitudou/category_9276477.html
put上传命令:
hadoop fs -put /usr/local/soft/jdk8/jdk-8u181-linux-x64.tar.gz hdfs://192.168.217.100:9000/jdk
登录上后查看根目录(逐级查看):
hadoop fs -ls -R /
单级目录创建
hadoop fs -mkdir path
多级目录创建(包括文件)
hadoop fs -mkdir -p path/path/t1.txt
命令help:
hadoop fs -help