汉字的笔顺信息提取
为了让机械臂能够书写出汉字,需要提取汉字的笔画信息,而汉字存在笔画顺序,笔画先后的问题,使用普通的方式是不能很好的按照笔画顺序书写出一个汉字的。
这里使用爬虫爬取百度汉字上的GIF图片,然后使用一些图像处理提取汉字的笔画顺序信息。
-
爬取GIF图片
这里就不详细写了,大家自行搜索一下就有一大堆了,稍加修改就能用了。
贴一下爬取的网址吧:
https://hanyu.baidu.com/s?wd=%E5%9F%8E&ptype=zici
在左上角,百度汉语下面就有该字的GIF了,有些汉字是没有的。 -
提取笔画信息
爬取完GIF后,就可以提取笔画信息了,因为GIF是由很多帧图片组成的,可以读取GIF中的每一帧图片,然后利用当前帧减去前一帧就可以得到书写过程了,然后提取当前帧减去前一帧出来的图片中的信息就可以得到一个点,每一个笔画都会有几帧或者一帧,有的笔画只有一帧那就需要进行判断处理了,也存在一帧图片会有两个笔画的现在,这也需要后续处理了。
当然在提取过程中需要对每一帧图片作一些图片处理,因为爬取下来的GIF中是有虚线点和背景水印的,这里就做二值化和腐蚀处理就可以了。
最后的效果就是下面这样了,提取右边黑白图片中的轮廓点然后就可以获取到当前笔画中的一个点了。
这里每个字的开始和每个笔画的开始前都是空白的,这时的轮廓点就为0,通过判断轮廓点数就可以知道是下一笔。
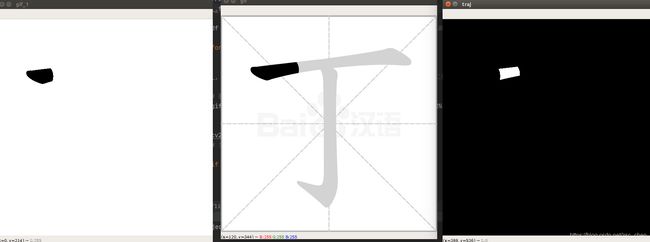
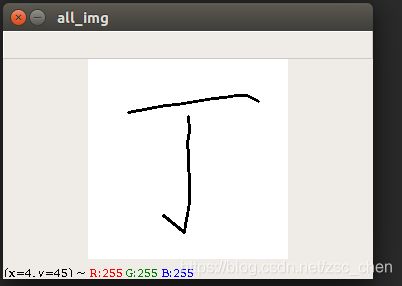
最后提取出来的数据就像这样子,“丁”字有两笔,第一个(0,0)为开始书写,第二个(0,0)是第一笔结束,开始第二笔;第三个(0,0)是提取结束

读取数据的时候以0.0,0.0为开始点和下一笔开始的信号,这样就可以做到书写多个汉字并正确的书写汉字。
用这个数据写出来的字如下
3. 处理笔画信息
主要是判断一个笔画只有一个帧,也就是只能提取出一个点的情况,还有一个就是一帧图片有2个笔画出现的情况了。
这里出现需要判断的地方主要是笔画是“点”是会出现只有一帧的情况,这时就需要判断,如果出现这个情况就自己在提取出来的那个点的基础上x,y方向加上一点当作是下一个点再写进文件中。
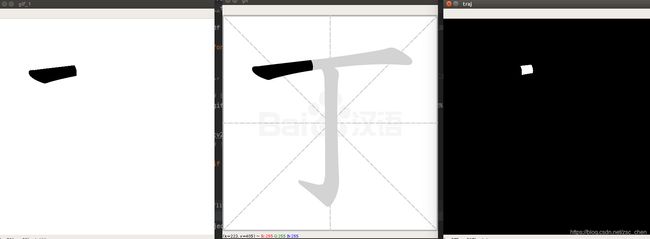
还有一种情况时一帧出现两个笔画,这种情况主要出现在 弯钩 提钩这种笔画中,如下图。
这里就需要对轮廓点进行判断,小于一定的值的话就舍弃。
最后在每个笔画的开始会有好几帧图片提取出来的轮廓点时0,这时就会写入多个(0,0),这里可以通过一个变量判断,只写入一次(0,0),也可以不管这个(0,0),在后续读取中作多一个判断也可以,像上一步的数据中就做了一个提前的判断处理。

- 爬取不到的汉字怎么办?数字或者字母没有GIF怎么办?
当然是利用OpenCv写一个鼠标点击函数,自己用鼠标写,提取。
创建一张空白图片,然后设置鼠标点击函数就OK了。
左键拖动就写,然后记录鼠标点位置,松开左键就是下一笔,然后摁下拖动再记录,再设置一个点击’n’键就清空画布,书写下一个字就行了。
def write(self, event, x, y, flags, param):
if event == cv2.EVENT_MOUSEMOVE and flags == cv2.EVENT_FLAG_LBUTTON:
cv2.circle(self.img, (x, y), 2, (0, 0, 0), 4)
self.step += 1
if self.step == 5:
add_point = '{},{}\n'.format(x, y)
self.f.write(add_point)
self.step = 0
if event == cv2.EVENT_LBUTTONUP:
add_point = '{},{}\n'.format(0.0, 0.0)
self.f.write(add_point)
print('next point')
def start_write(self):
i = 0
cv2.namedWindow('write_image')
cv2.setMouseCallback('write_image', self.write)
while i < len(self.str_write):
cv2.imshow('write_image',self.img)
k = cv2.waitKey(1)&0xFF
if k == ord('c'):
self.clear = True
self.img[:, :, 0] = 255
self.img[:, :, 1] = 255
self.img[:, :, 2] = 255
self.clear = False
if k == ord('n'):
i += 1
self.f.close()
self.f = open(self.filename + self.str_write[i] + '.txt', 'w')
add_point = '{},{}\n'.format(0.0, 0.0)
self.f.write(add_point)
print(self.str_write[i])
# self.clear = True
self.img[:, :, 0] = 255
self.img[:, :, 1] = 255
self.img[:, :, 2] = 255
# self.clear = False
elif k == 27:
break
就像这里写一个“好”字

写完一个字摁“n”就会在对应的文件夹生成对应的文件,里面就有每一笔的数据了