由于格式(format)多次namenode造成的集群id(ClusterID)不一致问题
高可用集群(ha集群),有两个namenode,一个active状态,一个standby状态。
1,当配置好第一个namenode后,第一次启动第一台namenode:hadoop-daemon.sh start namenode
2,第一次格式化namenode会产生集群ID(ClusterID):hdfs namenode -format
3,在另一台namenode执行:hdfs namenode -bootstrapStandby 同步集群ID到第二台namenode,
namenode的相关版本信息:
/home/hadoop/data/hadoopdata/name/current
#Tue Aug 21 09:28:12 CST 2018
namespaceID=1665921504
clusterID=CID-c5751e32-15c0-4ef0-90a3-232ea8a0be43 集群id
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1022750697-192.168.191.201-1534814892189 块池id
layoutVersion=-63
datanode的相关版本信息:
/home/hadoop/data/hadoopdata/data/current
#Tue Aug 21 09:18:00 CST 2018
storageID=DS-c4e87314-fb9c-49ee-95a3-5bf88a4c5cab
clusterID=CID-d2340bfc-d5b3-49af-aafe-f0854d1d4378
cTime=0
datanodeUuid=fcf91934-0f78-4eb7-8617-aa93291406c7
storageType=DATA_NODE
layoutVersion=-56
问题:
再次或多次对namenode格式化format后,会生成新的集群ID,其他节点的进程的集群ID却还是第一次格式化同步后的,集群ID版本不一致,不匹配,
导致start-all.sh时第二台namenode不能启动,三个datanode也不能启动,即便在各自单独节点上能够启动,但在web端访问时,三个datanode节点进程都不能正常显示,第二台standby状态的namenode也不能访问
解决办法:
1,将第一个active状态的namenode节点 /var/sxt/hadoop/ha/dfs/name/current(这个目录是各自创建的,每个人可能不同) 版本目录下的VERSION文件中的 Cluster ID复制更新到每个节点进程的VERSION文件里,更新 Cluster ID值,使其与第一台namenode的集群id版本一致。这种方法比较麻烦,还容易出错,因为我发现不但要改第二个namenode进程的VERSION里的 Cluster ID,三个datanode进程和三个journalnode进程的VERSION里的 Cluster ID都需要修改为同一个版本,所 以容易漏掉修改哪个进程的 Cluster ID,除此之外,我还发现,同步信息中的Namespace ID和Block pool ID版本也一致(第二种解决办法发现的),所以修改的地方比较多,容易出错,并且这种方法我也没验证成功,按理是可以的。
2,删除所有节点版本目录下dfs目录下生成的文件,重新在第二个namenode上执行同步hdfs namenode -bootstrapStandby 即可
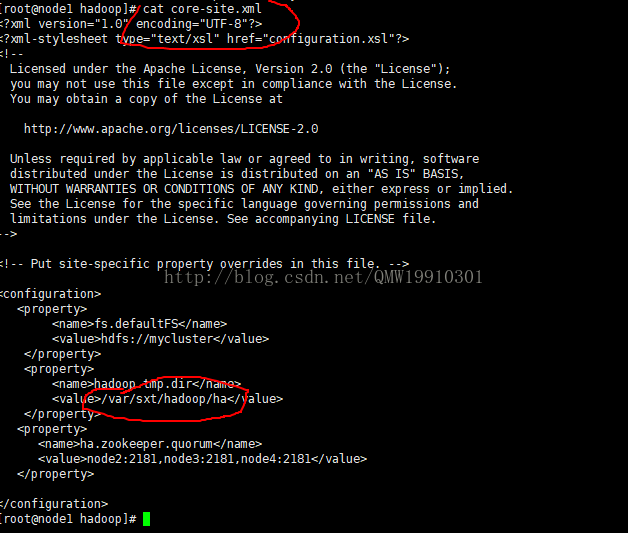
/var/sxt/hadoop/ha/dfs/name/current
/var/sxt/hadoop/ha/dfs/data/current
我这里删除的文件是dfs下的文件,包括name文件夹和data文件夹
每个人的版本目录各异,因为var目录是自定义创建,然后在core-site.xml中配置的,删除时依情况而定
---------------------
作者:爱若手握流沙
来源:CSDN
原文:https://blog.csdn.net/QMW19910301/article/details/78055601
版权声明:本文为博主原创文章,转载请附上博文链接!