高速缓冲存储器Cache
为什么要使用Cache
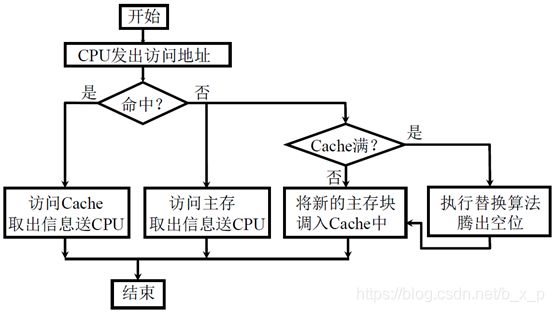
CPU 和主存(DRAM)的速度差异,避免 CPU “空等” 现象。
程序局部性原理
为了充分发挥Cache的能力,使得机器的速度能够切实的得到提高,必须要保障CPU访问的指令或数据大多情况下都能够在Cache中找到,这样依靠程序访问的局部性原理。
时间局部性: 当前正在使用的指令和数据,在不久的将来还会被使用到。那就是如果使用了指令和数据,将这些指令和数据放入到cache中,后面再用的时候直接从cache中获取。
空间局部性: 当前正在使用的指令和数据,在不久的将来相邻的数据或指令可能会被使用到。那就是,如果使用了指令和数据,需要将相邻的指令和数据也放入到cache中。
所以放入cache中的数据是以块为单位的,块包含了当前正在使用的指令和数据和相邻的指令和数据,块的大小要通过实验的方式进行确定。
Cache工作原理
(一)主存和缓存编址
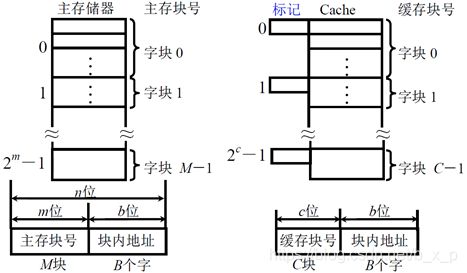
主存和缓存按块存储,块的大小相同,B 为块长,一般每块可取 4 ~ 8 个字,把主存储器和cache分成大小相等的块,主存中共有M块,cache中共育C块,Cache的容量要远远小于主存的容量,所以C要远远小于M,如果我们把主存和Cache分为大小相等的块,CPU给出的地址就可以分为两部分,即主存块号和块内地址,块内地址的位数决定了块的大小。Cache也分为了cache缓存编号和块内地址,但是在实际中,cache的缓存编号和块内地址没有实际的用处,也不用真正的去形成。
对于块内地址部分,主存块和cache块大小是相同的,所以块内地址位数是完全相同的,另外一个块在内存和cache之间进行传送的时候,是整体进行传送的,块内字节的顺序不会发生任何变化,所以内存块内地址和cache块内地址部分的值是完全相同的。
Cache上的标记,用于标记贮存块和cache块之间的对应关系,如果一个主存块我们把他保存到了cache中了,我们就把主存块号写入到标记中,将来CPU如果再次访问这个地址数据的时候,先访问cache,用主存块号和cache中的标记进行比较,看要访问的数据是否在cache中,如果和某一个标记正好相等,并且这个cache块是有效的,那这个cache块中就保存了他要访问的在内存中的信息,他就直接从cache中获取这些信息,这样速度就会得到很大的提升。
(二)命中和未命中
由于 M >> C,所以看定存在访问的部分主存内容不存在于 Cache中的情况。
命中: 主存块调入缓存,主存块与缓存块 建立 了对应关系,用 标记记录与某缓存块建立了对应关系的主存块号。
未命中: 主存块 未调入缓存,主存块与缓存块 未建立对应关系。
(三)Cache命中率
CPU 欲访问的信息在 Cache 中的 比率,命中率 与 Cache 的 容量 与 块长 有关,一般每块可取 4 ~ 8 个字,块长取一个存取周期内从主存调出的信息长度,这个和前面讲的提高存储器的访问速度中的多体交叉有关。如:采用16体交叉,每个存储体保存一个字,块长就是16个存储字,在一个存储周期中,可以把16个存储字取出放到cache中。如:
| CRAY_1 | 16体交叉 | 块长取 16 个存储字 |
|---|---|---|
| IBM 370/168 | 4体交叉 | 块长取 4 个存储字 |
CPU取若干次数据,从cache中读取了N1次,从主存中读取了N2次:
命中率 = N1 / (N1 + N2)
(四)Cache–主存系统效率
效率 e 与 命中率 有关:

分子是,CPU去访问一次Cache需要的时间。分母是CPU访问访问数据的平均时间(有的访问的是cache,有的访问的是主存)。
设 Cache 命中率 为 h,访问 Cache 的时间为 tc ,访问 主存 的时间为 tm
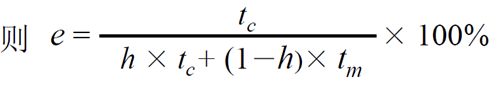
对于上面的这个公式,效率e的范围;[tc/tm, 1]。对于分母的平均时间计算,是在访问cache和访问主存并行的情况下计算出来的,如果,每次先访问cache,cache未命中再访问主存,公式将会发生变化。分母为 tc + (1 - h)tm。
Cache基本结构
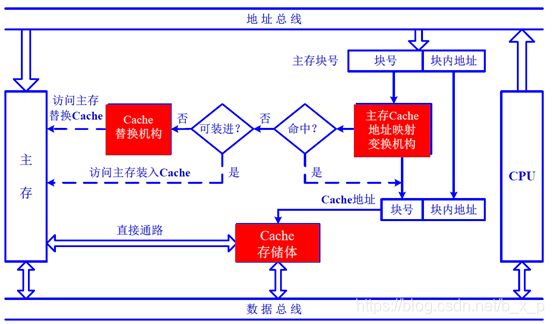
将主存地址映射到缓存中定位称为地址映射,将主存地址变换成缓存地址称为地址变换,当新的主存块需要调入缓存中,而它的可用位置又被占用时,需根据替换算法解决调入问题。
Cache读写操作
(一)读操作
(二)写操作
写直达法写回法(Write – through): 写操作时数据既写入Cache又写入主存,写操作时间就是访问主存的时间,Cache块退出时,不需要对主存执行写操作,更新策略比较容易实现。
写回法(Write – back) 写操作时只把数据写入 Cache 而不写入主存,当 Cache 数据被替换出去时才写回主存,写操作时间就是访问 Cache 的时间,Cache块退出时,被替换的块需写回主存,增加了Cache 的复杂性。
Cache改进
(一)增加Cache级数
片载(片内)Cache,片外 Cache
(二) 统一缓存和分立缓存
指令 Cache,数据 Cache
| Pentium | 8K 指令 Cache | 8K 数据 Cache |
|---|---|---|
| owerPC620 | 32K 指令 Cache | 32K 数据 Cache |
现在的缓存可分为片载缓存和片外缓存两级,并将指令缓存和数据缓存分开设置。
Cache-主存地址映射
(一)直接映射
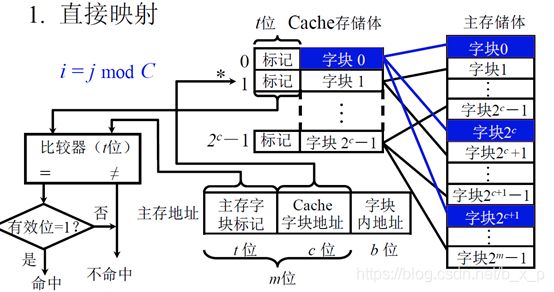
以cache存储体容量为单位,将主存储体划分为若干个和cache存储体大小相等的区域。每个区的大小和cache存储体的大小相等,每个区中包含的字块数和cache存储体中包含的字块数相等。每个区中的字块进行编号的时候,可以编号2的C次方减一个,在进行映射的时候,任何一个区的第0块只能存放在cache存储的第0块,任何一个区的第1块只能存放在cache存储的第1块中。即:每个缓存块 i 可以和 若干 个 主存块 对应,每个主存块 j 只能和 一 个 缓存块 对应。
对于这种方式,如果CPU给出一个地址,我们可以把地址分为三部分:主存字块标记,Cache字块地址,块内偏移。主存字块标记对应主存字块编号,Cache字块地址对应cache字块地址,块内偏移就是块内地址。
因为cache中的第0块,装载的可以是主存储体中任意一个区域的第0块,所以我们要把区号写在标记中。当CPU给出地址访问cacne的时候,先通过Cache字块地址确定读取的是cache中的哪一个块,再通过比较器比较这个块的标记和CPU给定地址的主存字块标记是否相等,如果是,则表示要访问的数据已经被加载进了cache,可以直接从cache中进行获取。
优点:这种方式,可以直接根据块号确定cache ,根据区号判断要读取的块是否被加载进了cache。
缺点:由于任何一个区的第0块只能存放在cache存储的第0块,任何一个区的第1块只能存放在cache存储的第1块中,就算有其他空闲也不能存入,这种映射使得cache的利用率很低,cache在调入的时候,冲突的概率很大,命中率低。
(二)全相联映射
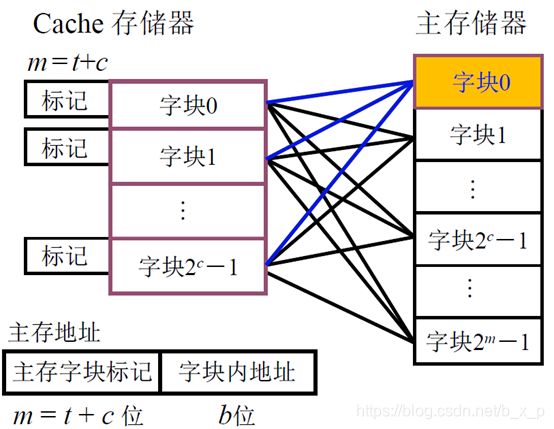
主存储器的任何块,可以被放入到cache中的任意块中,这样,任何一个字块只要想调入cache,只要cache中有空闲就能被调入进来。
缺点:
1、 CPU发出取数据地址,要确定要读取的数据是否在cache中,需要和cache中所有块的标记进行比较,如果相等就命中。这种方式速度比较慢。
2、 需要使用主存字块进行比较是否命中,参加比较的位数比较长,比较器的位数也比较长。
(三)组相联映射
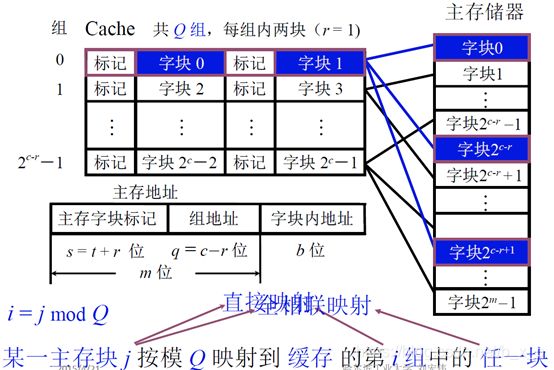
组相联映射,是直接相连映射和全相联映射的折中。
先把cache分成块,再把这若干个块分成组,每组中可以包含2块,4块,8块等。然后把主存储器中的字块也进行分区,每个区的大小和cache中的组数是相同。也就是cache被分成了多少组,主存储器每个区就有多少个块。映像的时候,每个区的第0块,可以放到cache第0组的任何一个位置。也就是,区里面的编号,就直接决定了他被放入到了cache中的那个组中。
这种方式,和直接关联相比,对于主存储器中的每个块,可以放入到cache一组中的多个位置,只要这组中有一个位置空闲,就能被调入。和全关联相比,只需要确定这个块是否在当前组中即可。
对于这种方式,虽然结构比较复杂,但是cache利用率高,获取数据效率高,计算简单。对于这种方式,如果cache只有一组,就变成了全相联,如果cache每组只有一块,就变成了直接相联。
对于以上的三种方式,在多层次的cache中使用是不一样的,对于接近CPU的cache,因为需要高速度,所以使用的是直接相连或者是cache每组块个数比较少的组相联。中间的层次,采用组相联的方式,距离CPU最远的cache,可以采用全相联的方式,因为距离CPU越远,对速度的要求越低,对cache利用率的要求越高。
4.7 替换算法
当使用全相联和组 相联的时候,如果 要获取的数据不在Cache中,从主存中读取后,需要将数据写入缓存Cache,如果Cache中已经有数据需要将Cache中的数据替换出去,那替换策略该如何呢。
(一)先进先出算法(FIFO)
让最先进入到内存块的数据先退出。这种方式并不能很好的体现程序的局部性原理。
(二)近期最少使用算法(LRU)
在最近的一段时间内,我们使用的最少的块。