Tensorflow on Spark在CDH5.16上的实践
Spark和Tensorflow目前是各自领域的代表,二者集成的资料很少,官方资料过于简单
这是官方的安装地址 https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN#convert-the-mnist-zip-files-into-hdfs-files 讲得很简单,按这个步骤是肯定跑不起来的,遇到的问题下文大概都有。
我已经装好了一套CDH5.16,python也已经装好是2.7版本,只需要安装tensorflow,按下面步骤来,我的集群有6台机器,每台机器都执行以下操作
yum install pip
pip install --ignore-installed enum34
pip install numpy
pip install tensorflow
pip install tensorflowonspark
全部安装完成后,选取一台机器下载需要用到的源码,后面的操作都在此台机器上执行
mkdir /data/tensorflow
cd /data/tensorflow
git clone --recurse-submodules https://github.com/yahoo/TensorFlowOnSpark.git #下载TensorflowOnSpark的源码
git clone https://github.com/tensorflow/ecosystem.git #下载Hadoop Input/OutputFormat for TFRecords源码
yum install maven #安装mvn工具
cd /data/tensorflow/ecosystem/hadoop
mvn clean package #将/data/tensorflow/ecosystem/hadoop下面的项目打成jar包,会生成target文件夹,里面有 tensorflow-hadoop-1.10.0.jar,后面用下载Hadoop Input/OutputFormat for TFRecords时需要
下载 MNIST数据集
mkdir /data/tensorflow/TensorFlowOnSpark/mnist
curl -O "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz"
curl -O "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz"
将数据集转换,可以转换成csv或者TFRecords格式
在下载的数据集的上一层目录执行,我的是/data/tensorflow/TensorFlowOnSpark
TFRecords格式
spark2-submit \
--master local \
--jars /data/tensorflow/ecosystem/hadoop/target/tensorflow-hadoop-1.10.0.jar \
/data/tensorflow/TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \
--output /data/tensorflow/TensorFlowOnSpark/examples/mnist/tfr \
--format tfr
csv格式
spark2-submit \
--master local \
/data/tensorflow/TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \
--output /data/tensorflow/TensorFlowOnSpark/examples/mnist/csv \
--format csv
注意以上输出目录是hdfs上的目录
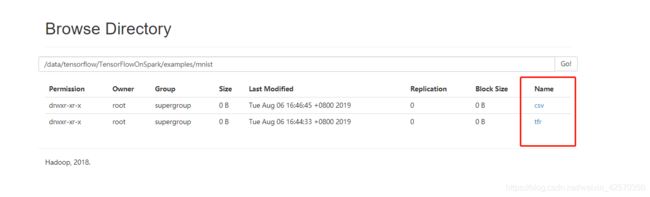
开始训练数据生成模型
tfr格式
spark2-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-cores 1 \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.yarn.maxAppAttempts=1 \
--queue default \
--conf spark.executorEnv.LD_LIBRARY_PATH="/opt/cloudera/parcels/CDH/lib64:$JAVA_HOME/jre/lib/amd64/server" \
--jars /data/tensorflow/ecosystem/hadoop/target/tensorflow-hadoop-1.10.0.jar \
--py-files /data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \
/data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \
--images hdfs:/data/tensorflow/TensorFlowOnSpark/examples/mnist/tfr/train \
--format tfr \
--mode train \
--model /mnist_model_tfr \
--cluster_size 10
csv格式
spark2-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-cores 1 \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.yarn.maxAppAttempts=1 \
--queue default \
--conf spark.executorEnv.LD_LIBRARY_PATH="/opt/cloudera/parcels/CDH/lib64:$JAVA_HOME/jre/lib/amd64/server" \
--py-files /data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \
/data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \
--images hdfs:/data/tensorflow/TensorFlowOnSpark/examples/mnist/csv/train/images \
--labels hdfs:/data/tensorflow/TensorFlowOnSpark/examples/mnist/csv/train/labels \
--format csv \
--mode train \
--model /mnist_model \
--cluster_size 10
注意:num-executors要等于cluster_size,没有gpu参数–queue要为default,关闭动态分配,–model后面的是hdfs目录
查看模型
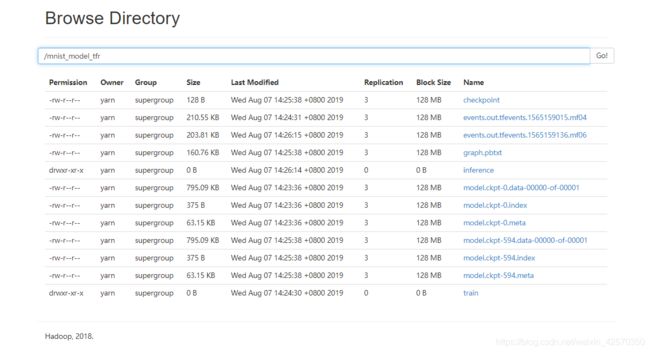

预测数据
tfr格式
spark2-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-cores 1 \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.yarn.maxAppAttempts=1 \
--queue default \
--conf spark.executorEnv.LD_LIBRARY_PATH="/opt/cloudera/parcels/CDH/lib64:$JAVA_HOME/jre/lib/amd64/server" \
--jars /data/tensorflow/ecosystem/hadoop/target/tensorflow-hadoop-1.10.0.jar \
--py-files /data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \
/data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \
--images hdfs:/data/tensorflow/TensorFlowOnSpark/examples/mnist/tfr/test \
--format tfr \
--mode inference \
--model /mnist_model_tfr \
--output /predictions_tfr \
--cluster_size 10
csv格式
spark2-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 10 \
--executor-cores 1 \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.yarn.maxAppAttempts=1 \
--queue default \
--conf spark.executorEnv.LD_LIBRARY_PATH="/opt/cloudera/parcels/CDH/lib64:$JAVA_HOME/jre/lib/amd64/server" \
--py-files /data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \
/data/tensorflow/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \
--cluster_size 10 \
--images hdfs:/data/tensorflow/TensorFlowOnSpark/examples/mnist/csv/test/images \
--labels hdfs:/data/tensorflow/TensorFlowOnSpark/examples/mnist/csv/test/labels \
--format csv \
--mode inference \
--model /mnist_model \
--output /predictions
查看预测的结果
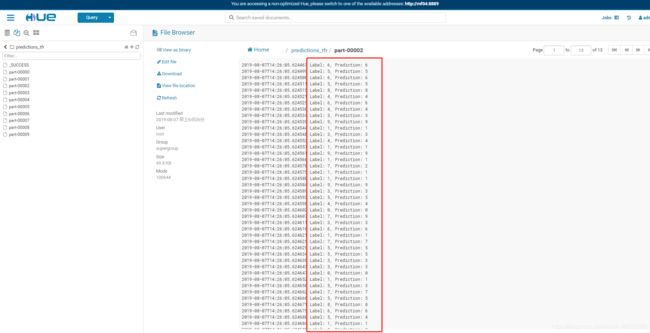
至此整个流程算是跑通了
报错汇总!!!!
Modules/common.h:9:20: 致命错误:Python.h:没有那个文件或目录
#include "Python.h"

解决办法: yum install python-devel
ERROR: Cannot uninstall 'python-ldap'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
解决办法:pip install --ignore-installed python-ldap==3.0.0b1
Modules/constants.h:7:18: 致命错误:lber.h:没有那个文件或目录
#include "lber.h"
^
解决办法:yum install openldap-devel
ERROR: ipapython 4.6.4 has requirement dnspython>=1.15, but you'll have dnspython 1.12.0 which is incompatible.
解决办法:pip install dnspython==1.15
19/08/07 14:54:44 INFO spark.SparkContext: Registered listener com.cloudera.spark.lineage.NavigatorAppListener
Traceback (most recent call last):
File "/data/tensorflow/TensorFlowOnSpark/examples/mnist/mnist_data_setup.py", line 143, in
writeMNIST(sc, "mnist/train-images-idx3-ubyte.gz", "mnist/train-labels-idx1-ubyte.gz", args.output + "/train", args.format, args.num_partitions)
File "/data/tensorflow/TensorFlowOnSpark/examples/mnist/mnist_data_setup.py", line 47, in writeMNIST
with open(input_images, 'rb') as f:
IOError: [Errno 2] No such file or directory: 'mnist/train-images-idx3-ubyte.gz'
解决办法:在下载的数据集目录mnist的上一层目录执行submit,因为源码中写的是相对路径mnist/
ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.
解决办法:重复执行
with open("executor_id", "r") as f:
IOError: [Errno 2] No such file or directory: 'executor_id'
解决办法:https://github.com/yahoo/TensorFlowOnSpark/issues/261
我照这上面的更改的提交命令
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/python/lib/pyspark.zip/pyspark/worker.py", line 253, in main
process()
File "/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/python/lib/pyspark.zip/pyspark/worker.py", line 248, in process
serializer.dump_stream(func(split_index, iterator), outfile)
File "/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/python/lib/pyspark.zip/pyspark/rdd.py", line 2440, in pipeline_func
File "/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/python/lib/pyspark.zip/pyspark/rdd.py", line 2440, in pipeline_func
File "/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/python/lib/pyspark.zip/pyspark/rdd.py", line 2440, in pipeline_func
File "/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/python/lib/pyspark.zip/pyspark/rdd.py", line 350, in func
File "/opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/python/lib/pyspark.zip/pyspark/rdd.py", line 799, in func
File "/usr/lib/python2.7/site-packages/tensorflowonspark/TFSparkNode.py", line 420, in _train
raise Exception("Timeout while feeding partition")
Exception: Timeout while feeding partition
解决办法:spark-submit命令中添加 --conf spark.executorEnv.LD_LIBRARY_PATH="/opt/cloudera/parcels/CDH/lib64:$JAVA_HOME/jre/lib/amd64/server" ,我的是CDH版本的,其它版本的写自己的地址就行