Viterbi算法(续)
1.题目背景:
从前有个村儿,村里的人的身体情况只有两种可能:健康或者发烧。
假设这个村儿的人没有体温计或者百度这种神奇东西,
他们唯一判断他身体情况的途径就是到村头我的偶像金正月的小诊所询问。
月儿通过询问村民的感觉,判断她的病情,再假设村民只会回答正常、冷或头晕。
有一天村里奥巴驴就去月儿那去询问了。
第一天她告诉月儿她感觉正常。
第二天她告诉月儿感觉有点冷。
第三天她告诉月儿感觉有点头晕。
那么问题来了,月儿如何根据阿驴的描述的情况,推断出这三天中阿驴的一个身体状态呢?
为此月儿上百度搜 google ,一番狂搜,发现维特比算法正好能解决这个问题。月儿乐了。
2.已知情况:
隐含的身体状态 = { 健康 , 发烧 }
可观察的感觉状态 = { 正常 , 冷 , 头晕 }
月儿预判的阿驴身体状态的概率分布 = { 健康:0.6 , 发烧: 0.4 }
这就是初始状态序列。
月儿认为的阿驴身体健康状态的转换概率分布 = {
健康->健康: 0.7 ,
健康->发烧: 0.3 ,
发烧->健康:0.4 ,
发烧->发烧: 0.6}
这样就可以列出相应的状态转移矩阵。(见附录代码)
月儿认为的在相应健康状况条件下,阿驴的感觉的概率分布 = {
健康,正常:0.5 ,冷 :0.4 ,头晕: 0.1 ;
发烧,正常:0.1 ,冷 :0.3 ,头晕: 0.6 }
这样就可以列出相应的观测矩阵。
由上面我们可以发现,HMM的三要素都齐备了,下面就是解决问题了。
阿驴连续三天的身体感觉依次是: 正常、冷、头晕 。
3.题目:
已知如上,求:阿驴这三天的身体健康状态变化的过程是怎么样的?
即已知观测序列和HMM模型的情况下,求状态序列。
4.求解过程:
·初始化:
第一天的时候,对每一个状态(健康或者发烧),分别求出第一天身体感觉正常的概率:
P(第一天健康) = P(正常|健康)*P(健康|初始情况) = 0.5 * 0.6 = 0.3
P(第一天发烧) = P(正常|发烧)*P(发烧|初始情况) = 0.1 * 0.4 = 0.04
·第二天:
第二天的时候,对每个状态,分别求在第一天状态为健康或者发烧情况下观察到冷的最大概率。
在维特比算法中,我们先要求得路径的单个路径的最大概率,然后再乘上观测概率。
P(第二天健康) = max{0.3*0.7, 0.04*0.4}*0.4=0.3*0.7*0.4=0.084
此时我们需要记录概率最大的路径的前一个状态,即0.084路径的前一个状态,我们在小本本上记下:
第一天健康。
P(第二天发烧)=max{0.3*0.3, 0.04*0.6}*0.3=0.027, 同样的在0.027这个路径上:
第一天也是健康的。
·第三天:
第三天的时候,跟第二天一样。
P(第三天健康)=max{0.084*0.7, 0.027*0.4}*0.1=0.00588,在这条路径上,第二天是健康的。
P(第三天发烧)=max{0.084*0.3, 0.027*0.6}*0.6=0.01512,在这条路径上,第二天是健康的。
·最后一天:
最后一天的状态概率分布即为最优路径的概率,即P(最优)=0.01512
这样我们可以得到最优路径的终点,是发烧
由最优路径开始回溯。请看我们的小本本:
在求得第三天发烧概率的时候,我们的小本本上面写的是第二天健康,好了,第二天就应该是健康的状态;
然后在第二天健康的情况下,我们记录的第一天是健康的。
这样,我们的状态序列逆推出来了。即为:健康,健康,发烧。
·简略的画个图吧:
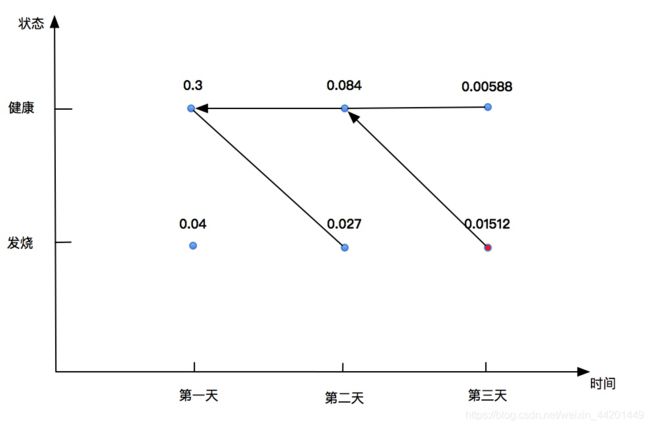
这儿的箭头指向就是一个回溯查询小本本的过程,我们在编写算法的时候,其实也得注意,每一个概率最大的单条路径上都要把前一个状态记录下来。
附录(python代码)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @File : Viterbi_Algorithm_s
# @Author : 研哥哥
# @Time : 2020/7/25 21:46
"""
实现精简的隐马尔科夫模型的维特比算法(Viterbi Algorithm)
"""
import numpy as np
def viterbi_algorithm(A, B, pai, O):
N = np.shape(A)[0] # 隐马尔科夫模型状态个数
T = np.shape(O)[0] # 观测序列的观测个数,即时刻个数
delta = np.zeros((T, N)) # 每个时刻每个状态对应的局部最优状态序列的概率数组
psi = np.zeros((T, N)) # 每个时刻每个状态对应的局部最优状态序列的前导状态索引数组
# (1)viterbi algorithm
for t in range(T): # [0,1,...,T-1]
if 0 == t: # 计算初值
delta[t] = np.multiply(pai.reshape((1, N)), np.array(B[:, O[t]]).reshape((1, N)))
continue
for i in range(N):
delta_t_i = np.multiply(np.multiply(delta[t - 1], A[:, i]), B[i, O[t]])
delta[t, i] = max(delta_t_i)
psi[t][i] = np.argmax(delta_t_i)
states = np.zeros((T,))
t_range = -1 * np.array(sorted(-1 * np.arange(T)))
for t in t_range:
if T - 1 == t:
states[t] = np.argmax(delta[t])
else:
states[t] = psi[t + 1, int(states[t + 1])]
print('局部最优状态的概率分布图:\n', delta)
print('局部最优状态的前时刻状态索引图:\n', psi)
print('最优状态序列:', states)
return states
def _viterbi_demo():
"""
1.题目背景:
从前有个村儿,村里的人的身体情况只有两种可能:健康或者发烧。
假设这个村儿的人没有体温计或者百度这种神奇东西,他唯一判断他身体情况的途径就是到村头我的偶像金正月的小诊所询问。
月儿通过询问村民的感觉,判断她的病情,再假设村民只会回答正常、冷或头晕。
有一天村里奥巴驴就去月儿那去询问了。
第一天她告诉月儿她感觉正常。
第二天她告诉月儿感觉有点冷。
第三天她告诉月儿感觉有点头晕。
那么问题来了,月儿如何根据阿驴的描述的情况,推断出这三天中阿驴的一个身体状态呢?
为此月儿上百度搜 google ,一番狂搜,发现维特比算法正好能解决这个问题。月儿乐了。
2.已知情况:
隐含的身体状态 = { 健康 , 发烧 }
可观察的感觉状态 = { 正常 , 冷 , 头晕 }
月儿预判的阿驴身体状态的概率分布 = { 健康:0.6 , 发烧: 0.4 }
这就是初始状态序列。
月儿认为的阿驴身体健康状态的转换概率分布 = {
健康->健康: 0.7 ,
健康->发烧: 0.3 ,
发烧->健康:0.4 ,
发烧->发烧: 0.6}
这样就可以列出相应的状态转移矩阵。(人懒。。不想编辑公式了)
月儿认为的在相应健康状况条件下,阿驴的感觉的概率分布 = {
健康,正常:0.5 ,冷 :0.4 ,头晕: 0.1 ;
发烧,正常:0.1 ,冷 :0.3 ,头晕: 0.6 }
这样就可以列出相应的观测矩阵。
由上面我们可以发现,HMM的三要素都齐备了,下面就是解决问题了。
阿驴连续三天的身体感觉依次是: 正常、冷、头晕 。
3.题目:
已知如上,求:阿驴这三天的身体健康状态变化的过程是怎么样的?即已知观测序列和HMM模型的情况下,求状态序列。
"""
# 隐马尔可夫模型λ=(A, B, pai)
# A是状态转移概率分布,状态集合Q的大小N=np.shape(A)[0]=2
# 从下给定A可知:Q={健康, 发烧}, N=2
A = np.array([[0.7, 0.3],
[0.4, 0.6]])
# B是观测概率分布,观测集合V的大小T=np.shape(B)[1]=3
# 从下面给定的B可知:V={正常, 冷, 头晕},T=3
B = np.array([[0.5, 0.4, 0.1],
[0.1, 0.3, 0.6]])
# pai是初始状态概率分布,初始状态个数=np.shape(pai)[0]=2
pai = np.array([[0.6],
[0.4]])
# 观测序列
O = np.array([[0],
[1],
[2]]) # 0表示正常,1表示冷,2表示头晕,就是(正常,冷,头晕)观测序列
viterbi_algorithm(A, B, pai, O)
if __name__ == '__main__':
_viterbi_demo()
代码结果
局部最优状态的概率分布图:
[[0.3 0.04 ]
[0.084 0.027 ]
[0.00588 0.01512]]
局部最优状态的前时刻状态索引图:
[[0. 0.]
[0. 0.]
[0. 0.]]
最优状态序列: [0. 0. 1.]
结语
至此,大功告成!
Viterbi算法(续))已全部完成,祝各位学业有成!
另外:博主关于此算法会在后续NLP理解上再次编写新的博客!
此博文只做学习用途,无任何商业用途!
大大怪爱小乖乖!
研哥哥