Oracle为什么不需要double write?
近期看到朋友圈转发了几篇关于MySQL innodb double write的文章;感觉都还不错。突然想到为什么Oracle没有这个东西?PostgreSQL是否也有类似机制?
在网上搜了一下,发现有人之前简单写过类似文章。。。。但是;毫无疑问,没有一篇能够完全分析透彻的的。
所以,我想来好好说一下这个问题。
首先MySQL 的double write的机制,是为了解决partial write的问题;那么为什么会存在partial write呢? 这本质上是因为操作系统的最小IO单位一般为4k;以前大家使用的sas、sata的sector 都是512. 现在如果是nvme ssd之类,已经有4k甚至16kb的sector了。之所以sector越来越大就是为了解决ssd容量的问题。
这里不扯太远了。简单的将,由于数据库的最小IO单位是page或者block,mysql 默认是16kb,而Oracle 大家通常默认使用8k的block size。这就导致数据库的一次最小IO对于操作系统来讲,需要调用多次完成。这里以MySQL为例,每一次写16kb,假定os 最小IO为4k;那么需要调用4次。那么问题就来了。
假设操作系统只执行了2 IO操作就crash了,这个page 不就写坏了吗?这就是partial write 。
为什么说MySQL 的double write 可以解决partial write的问题呢 ? 要回答这个问题之前;我们先来看一下MySQL整个数据读取和写入的基本流程(这只是大致流程,实际要要复杂的多):
1、 data page1从idb数据文件中被读取到buffer pool中(这里也涉及到各种LRU);
2、 user A发起事务T1 开始修改 page1;此时page1 会变成一个脏页(dirty page);
3、 同时MySQL会开始写redo log;当然这里是先将page1的变更写入redo buffer;并不会立刻落盘;
4、User A 开始发起commit提交这个事务T1;
5、 此时MySQL会将redo buffer内容flush到redo log中,即完成此时的redo 落盘操作;
6、完成日志落盘后,Page1 会被先通过memcopy到double write buffer中;注意其实double write buffer并不是内存结构;其实是是在
共享表空间ibdata中分配的一块连续区域,相当于是把磁盘当内存使用;大小默认是2m,分为2个部分,每个部分1M;根据16kb单位进行计算,大概就是128个page。
7、最后double write buffer被写满或者用户本身发起了刷脏行为,那么会把数据从double write buffer写入到数据文件中。
上述是大致流程;那么为什么说能解决partial write问题呢?
1)假设page1 写入到double write buffer 就失败了;那么这个page1 根本就不会被写入到数据文件落盘;如果此时数据库crash了;
按照正常的恢复流程,找检查的,应用redo,undo进行恢复即可。这没什么可说的。
2)假设写入到double write buffer成功;但是page1 在写入到数据文件中时失败;如何进行恢复呢?这就是我们要说的关键地方
由于double write buffer中是写成功了,数据文件写失败;那么在恢复时MySQL在检查这个page1时发现checksum有问题;会直接从
double write buffer中copy 已经写完成的page1覆盖到数据文件对应位置;然后再去应用redo等等。
所以简单来讲,double write机制更像在数据落盘之前多了一层缓冲。 那么这个机制是否有问题呢 ? 我认为是存在一定问题的;
比如为了确保机制的实现,double write buffer并不是真正的内存不buffer,是从共享表空间中分配一块连续区域出来;这本质上是用
磁盘当内存使用,虽然读写大都是顺序读写(实际上可能也存在随机single page flush的情况)。磁盘的操作毕竟比纯内存中的操作要慢一些;当然这个机制本身来讲并不会带来多大的性能衰减,因为就是普通的SAS 硬盘,顺序读写性能都是非常不错的。
另外为什么会出现这个问题呢,其实是因为很多存储设备不支持原子写;MySQL 目前暂时也不支持;不过MariaDB目前是支持这个特性的。https://mariadb.com/kb/en/atomic-write-support/
当然这是过去的时代,现在都是各种Fusion IO/PCIE SSD;大多都已经支持了原子写了。既然硬件已经支持,是否我们就可以在SSD方面关闭这个功能呢?很明显是可以的,既然都支持原子写了,还需要double write这种鸡肋的功能干什么呢,这本身就是一种不算太完美的方案。其实MySQL官方文章也直接说明了这个问题:
If system tablespace files (“ibdata files”) are located on Fusion-io devices that support atomic writes, doublewrite buffering is automatically disabled and Fusion-io atomic writes are used for all data files. Because the doublewrite buffer setting is global, doublewrite buffering is also disabled for data files residing on non-Fusion-io hardware. This feature is only supported on Fusion-io hardware and is only enabled for Fusion-io NVMFS on Linux. To take full advantage of this feature, an innodb_flush_method setting of O_DIRECT is recommended.
如果直接看源码你会看到如下的类似内容:
#if !defined(NO_FALLOCATE) && defined(UNIV_LINUX)
/* Note: This should really be per node and not per
tablespace because a tablespace can contain multiple
files (nodes). The implication is that all files of
the tablespace should be on the same medium. */
if (fil_fusionio_enable_atomic_write(it->m_handle)) {
if (srv_use_doublewrite_buf) {
ib::info(ER_IB_MSG_456) << "FusionIO atomic IO enabled,"
" disabling the double write buffer";
srv_use_doublewrite_buf = false;
}
it->m_atomic_write = true;
} else {
it->m_atomic_write = false;
}
#else
it->m_atomic_write = false;
#endif /* !NO_FALLOCATE && UNIV_LINUX*/
简单的讲,就是如果都使用了支持原子写的fusion-io 等存储设备,那么double write机制会被自动disable。同时官方建议将innodb_fush_method设置为o_direct;这样可以充分发挥硬件性能。
除了硬件等支持,那么传统等文件系统比如ext4/xfs/zfs/VxFS 是否支持原子写呢?
实际上ext4/xfs对原子写支持目前都不是非常优化,zfs是天然支持对,老早对版本就支持了,另类的文件系统;另外veritas的VxFS也是支持的;其官网有相关的解释:https://sort.veritas.com/public/documents/vis/7.0/linux/productguides/html/infoscale_solutions/ch05s07.htm
对存储这方面了解不多,不敢写太多,免得被碰。我们还是回到数据库这个层面上来。
国内也有一些硬件厂家在不断努力优化这个问题;例如Memblaze的混合介质的多命名空间管理解决方案(这里我不是打广告,只是网上搜到一点材料 https://cloud.tencent.com/developer/news/404974 )从这个测试了来看,percona mysql 8.0..15在启用parallel double write的情况下;性能有超过30%的提升,这还是非常不错的。注意这里的parallel 是根据buffer pool instance来的;提高并发处理能力。
实际上MySQL 原生版本在8.0.20在double write方面做了重大改变(看上去有点抄袭xxx的做法);比如也可以把double write files进行单独存放了;
Prior to MySQL 8.0.20, the doublewrite buffer storage area is located in the InnoDB system tablespace. As of MySQL 8.0.20, the doublewrite buffer storage area is located in doublewrite files.
也引入了类似Parallel的机制;如果查看官方文档能看到引入了类似如下的相关参数:
innodb_doublewrite_files(这个跟buffer pool instacne有关)
innodb_doublewrite_pages
innodb_doublewrite_batch_size
不难看出MySQL 8.0.20 在这方面做的很不错了,相比性能必定又上升一个台阶。 对于这个我一直感觉比较奇怪;为什么会出现?
那么这个有没有可能跟MySQL 自身page的结构有关系呢? 开始我以为可能是这个问题,发现其实并不是:
查看mysql的源码来看,本身mysql 也具是需要检查page checksum的,否则怎么判断坏页呢?
/** Issue a warning when the checksum that is stored in the page is valid,
but different than the global setting innodb_checksum_algorithm.
@param[in] curr_algo current checksum algorithm
@param[in] page_checksum page valid checksum
@param[in] page_id page identifier */
void page_warn_strict_checksum(srv_checksum_algorithm_t curr_algo,
srv_checksum_algorithm_t page_checksum,
const page_id_t &page_id);
说完了MySQL,我们再来看看PostgreSQL(开源数据库永远的老二)是否也存在这个问题。 我本身对PostgreSQL是不太熟的;
查阅了相关文档发现,PG在老早的版本就引入了full page write机制,来避免这种partial write问题。
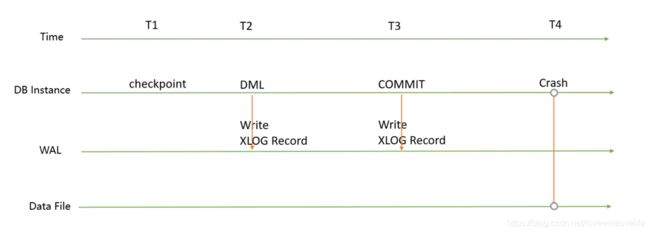
这里我盗用一个图片来简单解释一下PostgreSQL的数据写入流程:
1、假设T1 时间点触发了checkpoint;
2、T2时间点开始将DML操作产生的变化刷到xlog(关系型数据库都是日志写优先原则)
3、T3时间点事务发起了commit提交操作;这个时候会将脏页变化落盘xlog(这时候仍然还没开始写脏页)
4、T3之后准备将脏数据flush 到datafile时;如果数据库这时候crash;可能会是什么现象?
那么PostgreSQL 的full page write机制为什么说可以避免在T4时间点crash 数据不丢的问题呢 ? 实际上是因为在这里T2
时间点;如果启用了full page write(实际上默认就启用了);会将整个脏页写入到wal 日志。我靠。。。这是什么鬼。。
这当然解决了partial write的问题。crash就直接用wal日志进行恢复就完了,因为里面有脏页的完整记录。
从这里我们也能看到问题的所在;如果写入整个page 的内容到wal日志(注意:这里是说每次checkpoint后的数据块第一次变脏落盘之前,整个page都会写入wal日志,后面再次被修改就不需要写整个page了),那么势必会导致wal日志的疯狂增长;同时在性能上也会有一定影响。
关于启用full page write 之后存在写放大问题,如何优化wal日志,可以参考这个文章:
http://www.postgres.cn/v2/news/viewone/1/273
上述文章中提到可以通过降低checkpoint 以及 压缩等方式来降低写放大的影响。其中关于full page write的源码机制分析;可参考
阿里内核数据库组的这篇文档,很赞。http://mysql.taobao.org/monthly/2015/11/05/
PostgreSQL官方文档其实对这个描述是不太充分的;如下是我摘自postgreSQL 12的官方文档内容:
full_page_writes ( boolean)
When this parameter is on, the PostgreSQL server writes the entire content of each disk page to WAL during the first modification of that page after a checkpoint. This is needed because a page write that is in process during an operating system crash might be only partially completed, leading to an on-disk page that contains a mix of old and new data. The row-level change data normally stored in WAL will not be enough to completely restore such a page during post-crash recovery. Storing the full page image guarantees that the page can be correctly restored, but at the price of increasing the amount of data that must be written to WAL. (Because WAL replay always starts from a checkpoint, it is sufficient to do this during the first change of each page after a checkpoint. Therefore, one way to reduce the cost of full-page writes is to increase the checkpoint interval parameters.)
Turning this parameter off speeds normal operation, but might lead to either unrecoverable data corruption, or silent data corruption, after a system failure. The risks are similar to turning off fsync, though smaller, and it should be turned off only based on the same circumstances recommended for that parameter.
Turning off this parameter does not affect use of WAL archiving for point-in-time recovery (PITR) (see Section 25.3).
This parameter can only be set in the postgresql.conf file or on the server command line. The default is on.
那么这里有个问题;现在都是各种PCIE SSD 满天飞了;比如宝存的PCIE就支持原子写了;那么这种情况下我们能否关闭full page write机制?
从技术上来讲;假设PCIE支持的原子写是4k;那么pg 默认使用8k page的话,仍然存在这个问题;前提是数据库使用的page size小于或者等于硬件设备所支持的原子写IO大小。如果能够满足这个条件,我认为完全是可以关闭的。
以宝存pcie 为例子,其Nand Flash的最小写单位是page,NandFlash写page的操作是原子操作。我们只要将上层应用程序发过来的写操作放在一个Nand Flash的page也就实现了原子写支持;目前Nand Flash 都是32k;这基本上都是大于数据库的通用block size /page size的。因此,如果你使用宝存的pcie,那么你可以disable 这个特性。(这里不是广告)
这里我再补充一下,类似阿里的PolarDB 似乎也取消了double write的机制;因为其底层的PolarFS分布式文件系统据说实现了原子写支持;那自然也就不需要这个机制了。
前面铺垫了这么久,之前也有MySQL大佬吐槽挖苦说。。。Oracle DBA 连原子写都不知道。
这里我想说的是不知道,是因为Oracle 圈子大家从来没有care过这个东西;或者说Oracle 本身早已解决了这个问题;所以大家从来没有提过。那么为什么Oracle 数据库里面很少提及这个问题呢 ?是真的Oracle 不存在这个问题吗
虽然Oracle 号称这个星期最强关系型OLTP数据库,但是我认为仍然存在这个问题;因为DB层毕竟难以感知OS层的IO操作;
我们先来看下Oracle data block的结构:
BBED> set file 7 block 347
FILE# 7
BLOCK# 347
BBED> map
File: /opt/oracle/oradata/ENMOTECH/users01.dbf (7)
Block: 347 Dba:0x01c0015b
------------------------------------------------------------
KTB Data Block (Table/Cluster)
struct kcbh, 20 bytes @0
struct ktbbh, 96 bytes @20
struct kdbh, 14 bytes @124
struct kdbt[1], 4 bytes @138
sb2 kdbr[66] @142
ub1 freespace[911] @274
ub1 rowdata[7003] @1185
ub4 tailchk @8188
BBED> p kcbh
struct kcbh, 20 bytes @0
ub1 type_kcbh @0 0x06
ub1 frmt_kcbh @1 0xa2
ub2 wrp2_kcbh @2 0x0000
ub4 rdba_kcbh @4 0x01c0015b
ub4 bas_kcbh @8 0x00791f1a
ub2 wrp_kcbh @12 0x0000
ub1 seq_kcbh @14 0x02
ub1 flg_kcbh @15 0x04 (KCBHFCKV)
ub2 chkval_kcbh @16 0xfe84
ub2 spare3_kcbh @18 0x0000
BBED> p tailchk
ub4 tailchk @8188 0x1f1a0602
从结构上来看,我们知道Oracle 这里有一种机制来判断Block是否属于断裂block;即使在block尾部写入一个tailchk值;其中
tailchk 的value=bas_kcbh(后4位)+type_kcbh+seq_kcbh。
正常业务逻辑的情况下,如果检查发现块头部和尾部的值不匹配;则认为断裂块;Oracle中的标准叫法为Fractured Block 。
有人说产生断裂block是因为通过begin bakup的热备场景。。。。其实并不仅仅是这个场景。 我们先来看下标准的解释:
A Fractured Block means that the block is incomplete and considered a Physical Corruption. Information from the block header does not match the block end / tail. It is a clear symptom about issues within the Operating System (OS) / Hardware layers.
In order to understand why a Fractured Block happens, we need to understand how a block is written into disk. The block size at OS level does not match the block size at Oracle level, so in order to write an Oracle block, the Operating System needs to perform more than one write. As an example: if OS block size is 512 bytes and Oracle block size is 8K, the OS performs 16 writes in order to complete the write process.
Oracle keeps track off the header of each block and before writing down to disk updates a 4 byte field/value in the tail of each block (tailchk) to guarantee afterwards consistency check that the block is complete after written.
This value was right on the block when the RDBMS sent the write to the Operating System; this is also confirmed by the fact that the checksum result is different than 0x0 which means that the checksum is different than when it was calculated before write and the block is not the same version that the RDBMS request to write before. The write did not complete as a whole and only partial write was done or the write completed but invalid information was actually written in the block.
The tail check only verifies if the header and the tail of the block have been written correctly, but does not warranty that the complete block was written. In order to warranty this, the database has parameter DB_BLOCK_CHECKSUM. When the parameter is set to TRUE / TYPICAL (default value), a checksum value is calculated for the complete block and this value is stored in the block header before writing the block. When the block is read again, this value is recomputed and compared with the one at block header.
There are checks that may be run against datafiles to ensure the validity of all tail values on all blocks of them. RMAN Validate or DBVerify catch this kind of failures and may be used against the Database file(s) to check for Physical Corruption.
Identically, there is a clear path to follow when this happens. These blocks are incorrectly written by the Operating System / Hardware and as such, Oracle operations over the blocks affected are correct (otherwise, a different kind of error would have been printed out).
In addition, restoring and recovering the block is not introducing the issue again, what indicates that the redo changes generated are correct, so the issue is clearly related with other layer (most probably hardware layer)。
上面的红色部分是这段话的关键所在。从上面的内容可以看出;Oracle 通过在数据块(index block也类似)尾部写入一个tailchk的方式来判断这个block是否完整;但是仅仅判断这个值,并不能确保整个block的数据是完好的;不过可以通过db_block_checksum来进一步进行检查(在读写时)。
但是在最后,看Oracle的说法是仍然无法彻底避免这个问题,毕竟最终数据落盘是由OS层来完成的,而不是Oracle自己。
对于上文提到的checksum值,其实Oracle是通过异或算法得出来的;是如果其他值不变的情况下,你是无法修改的;Oracle会自动进行计算。
BBED> modify /x 86 offset 16
Warning: contents of previous BIFILE will be lost. Proceed? (Y/N) y
File: /opt/oracle/oradata/ENMOTECH/users01.dbf (7)
Block: 347 Offsets: 16 to 19 Dba:0x01c0015b
------------------------------------------------------------------------
86fe0000
<32 bytes per line>
BBED> sum apply
Check value for File 7, Block 347:
current = 0xfe84, required = 0xfe84
BBED> p kcbh
struct kcbh, 20 bytes @0
ub1 type_kcbh @0 0x06
ub1 frmt_kcbh @1 0xa2
ub2 wrp2_kcbh @2 0x0000
ub4 rdba_kcbh @4 0x01c0015b
ub4 bas_kcbh @8 0x00791f1a
ub2 wrp_kcbh @12 0x0000
ub1 seq_kcbh @14 0x02
ub1 flg_kcbh @15 0x04 (KCBHFCKV)
ub2 chkval_kcbh @16 0xfe84
ub2 spare3_kcbh @18 0x0000
既然我们认为Oracle也存在这个问题;那么是否有相关的解决方案;如果你查询如下视图会看到如下几条信息:
SQL> l
1* select name,class from v$statname where name like '%partial%'
SQL> /
NAME CLASS
-------------------------------------------------- ----------
physical read partial requests 8
cell partial writes in flash cache 8
IM ADG invalidated pdb partial transaction 128
HSC OLTP partial compression 128
可以看到Oracle 这里是有个关于partial writes的统计数据的;既然有;那么就说明Oracle认为存在这个问题。不过大家也可以看到,上述几个数据都是针对Oracle exadata的。那么我们可以认为如果你使用Oracle exadata的话,其实不是不存在这个partial write问题的。
从这个层面来看,Oracle ACFS文件系统本身应该也还不支持原子写。我看网上很多文章说Oracle不需要类似double write机制,是因为Oracle有什么检查点,控制文件机制。。。。 这完全是瞎扯。
不过这里我想说的是Oracle的checkpoint 机制确实要比MySQL要强一些,我记得在Oracle 8i的时候就提供了增量检查点;在Oracle 10g就提供实现了检查点的自动调节。这一定程度缓解了刷脏的问题。
那么这里我在想,我们能否通过一些方式来验证一个数据库IO;在系统内核层是调用了2次呢;假设数据库block 是8k,os block是4k。
为了进行这个测试验证;我特意为我的虚拟机单独增加了一个盘,用来跟踪特定数据文件的IO情况,避免干扰。
SQL> create table test0405 as select * from dba_objects;
Table created.
SQL> alter table test0405 move tablespace users;
Table altered.
SQL> select header_file,header_block from dba_segments where segment_name='TEST0405';
HEADER_FILE HEADER_BLOCK
----------- ------------
12 130
SQL> select file#,name,CON_ID from v$datafile;
FILE# NAME CON_ID
---------- --------------------------------------------------------------------------- ----------
9 /opt/oracle/oradata/ENMOTECH/killdb/system01.dbf 3
10 /opt/oracle/oradata/ENMOTECH/killdb/sysaux01.dbf 3
11 /opt/oracle/oradata/ENMOTECH/killdb/undotbs01.dbf 3
12 /opt/oracle/oradata/ENMOTECH/killdb/users01.dbf 3
SQL> alter database datafile 12 offline drop;
Database altered.
SQL> !
[oracle@mysqldb1 ~]$ mv /opt/oracle/oradata/ENMOTECH/killdb/users01.dbf /data3/users01.dbf
[oracle@mysqldb1 ~]$ exit
exit
SQL> alter database rename file '/opt/oracle/oradata/ENMOTECH/killdb/users01.dbf' to '/data3/users01.dbf';
Database altered.
SQL> recover datafile 12;
Media recovery complete.
SQL> alter database datafile 12 online;
Database altered.
SQL> select file#,name,CON_ID from v$datafile;
FILE# NAME CON_ID
---------- --------------------------------------------------------------------------- ----------
9 /opt/oracle/oradata/ENMOTECH/killdb/system01.dbf 3
10 /opt/oracle/oradata/ENMOTECH/killdb/sysaux01.dbf 3
11 /opt/oracle/oradata/ENMOTECH/killdb/undotbs01.dbf 3
12 /data3/users01.dbf 3
SQL> select dbms_rowid.rowid_relative_fno(rowid) file_id,
2 dbms_rowid.rowid_block_number(rowid) block_id,
3 dbms_rowid.rowid_row_number(rowid) row_number from test0405
4 where object_id=100;
FILE_ID BLOCK_ID ROW_NUMBER
---------- ---------- ----------
12 132 32
SQL> alter system flush buffer_Cache;
System altered.
SQL> alter system checkpoint;
System altered.
SQL> alter system flush buffer_Cache;
System altered.
+++session 1
SQL> delete from test0405 where object_id=100;
1 row deleted.
SQL> commit;
Commit complete.
SQL> alter system checkpoint;
System altered.
++++session 2
[root@mysqldb1 ~]# ps -ef|grep dbw|grep -v grep
oracle 3664 1 0 17:10 ? 00:00:00 ora_dbw0_enmotech
[root@mysqldb1 ~]#
[root@mysqldb1 ~]#
[root@mysqldb1 ~]# strace -fr -o /tmp/dbw0.log -p 3664
Process 3664 attached
^CProcess 3664 detached
[root@mysqldb1 ~]#
[root@mysqldb1 ~]# cat /tmp/dbw0.log |grep 'pwrite'
3664 0.000221 pwrite(259, "\6\242\0\0S8\300\0\222f\211\0\0\0\1\6#\305\0\0\1\0\n\0\341/\0\0\217f\211\0"..., 8192, 118120448) = 8192
3664 0.000298 pwrite(259, "\6\242\0\0\2279\300\0\226f\211\0\0\0\1\6\322\204\0\0\1\0\24\0\0240\0\0\225f\211\0"..., 8192, 120774656) = 8192
......
3664 0.000135 pwrite(260, "\2\242\0\0\202\34\0\1If\211\0\0\0\1\4\3f\0\0\t\0\25\0U\3\0\0\271\0$$"..., 8192, 59785216) = 8192
3664 0.000124 pwrite(260, "\2\242\0\0\1\35\0\1Kf\211\0\0\0\1\4c\24\0\0\7\0\4\0v\3\0\0\257\0\31\31"..., 16384, 60825600) = 16384
3664 0.000162 pwrite(263, "\6\242\0\0N\3\0\1\233f\211\0\0\0\1\6\227\322\0\0\1\0\3\0\200$\0\0\232f\211\0"..., 8192, 6930432) = 8192
3664 0.000186 pwrite(264, "&\242\0\0\240\0@\2\246f\211\0\0\0\2\4O\277\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 8192, 1310720) = 8192
3664 0.000162 pwrite(264, "&\242\0\0\260\0@\2\233f\211\0\0\0\1\4\336\234\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 8192, 1441792) = 8192
3664 0.000106 pwrite(264, "&\242\0\0\300\0@\2\231f\211\0\0\0\1\4;\314\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 8192, 1572864) = 8192
3664 0.000168 pwrite(264, "&\242\0\0\320\0@\2\220f\211\0\0\0\1\4\"\277\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 8192, 1703936) = 8192
3664 0.000129 pwrite(264, "\2\242\0\0\314\3@\2\217f\211\0\0\0\1\4\270\302\0\0\6\0\6\0\217\2\0\0\342\00066"..., 8192, 7962624) = 8192
3664 0.000123 pwrite(264, "\2\242\0\0\202\6@\2\246f\211\0\0\0\1\4_M\0\0\3\0\33\0\205\2\0\0\337\0\27\27"..., 8192, 13647872) = 8192
3664 0.000116 pwrite(264, "\2\242\0\0}\20@\2\230f\211\0\0\0\1\4\204*\0\0\5\0\20\0\237\2\0\0\242\0\33\33"..., 8192, 34578432) = 8192
3664 0.000109 pwrite(264, "\2\242\0\0\334\22@\2\232f\211\0\0\0\1\4\223\355\0\0\4\0\24\0\246\2\0\0\16\1\36\36"..., 8192, 39550976) = 8192
3664 0.000108 pwrite(265, "\6\242\0\0\204\0\0\3\246f\211\0\0\0\2\6\\\20\0\0\1\0\0\0e#\1\0\234d\211\0"..., 8192, 1081344) = 8192
[root@mysqldb1 ~]# ls -ltr /proc/3664/fd
total 0
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 6 -> /opt/oracle/dbs/hc_enmotech.dat
lr-x------ 1 oracle oinstall 64 Apr 5 17:28 5 -> /proc/3664/fd
lr-x------ 1 oracle oinstall 64 Apr 5 17:28 4 -> /opt/soft/rdbms/mesg/oraus.msb
lr-x------ 1 oracle oinstall 64 Apr 5 17:28 3 -> /dev/null
l-wx------ 1 oracle oinstall 64 Apr 5 17:28 2 -> /dev/null
l-wx------ 1 oracle oinstall 64 Apr 5 17:28 1 -> /dev/null
lr-x------ 1 oracle oinstall 64 Apr 5 17:28 0 -> /dev/null
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 9 -> anon_inode:[eventpoll]
lr-x------ 1 oracle oinstall 64 Apr 5 17:28 8 -> /opt/soft/rdbms/mesg/oraus.msb
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 7 -> /opt/oracle/dbs/lkENMOTECH
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 271 -> /opt/oracle/oradata/ENMOTECH/pdbseed/temp012020-02-18_11-54-10-098-AM.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 270 -> /opt/oracle/oradata/ENMOTECH/pdbseed/system01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 269 -> /opt/oracle/oradata/ENMOTECH/pdbseed/sysaux01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 268 -> /opt/oracle/oradata/ENMOTECH/pdbseed/undotbs01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 267 -> /opt/oracle/oradata/ENMOTECH/killdb/temp01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 266 -> /opt/oracle/oradata/ENMOTECH/temp01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 265 -> /data3/users01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 264 -> /opt/oracle/oradata/ENMOTECH/killdb/undotbs01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 263 -> /opt/oracle/oradata/ENMOTECH/killdb/sysaux01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 262 -> /opt/oracle/oradata/ENMOTECH/killdb/system01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 261 -> /opt/oracle/oradata/ENMOTECH/users01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 260 -> /opt/oracle/oradata/ENMOTECH/undotbs01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 259 -> /opt/oracle/oradata/ENMOTECH/sysaux01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 258 -> /opt/oracle/oradata/ENMOTECH/system01.dbf
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 257 -> /opt/oracle/fast_recovery_area/ENMOTECH/control02.ctl
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 256 -> /opt/oracle/oradata/ENMOTECH/control01.ctl
lrwx------ 1 oracle oinstall 64 Apr 5 17:28 10 -> socket:[38121]
可以看到fd 265是我们的users数据文件,dbw0进程写了一个数据块8192.
[root@mysqldb1 ~]#
++++session 3
[root@mysqldb1 ~]# blktrace -d /dev/sdc1
^C=== sdc1 ===
CPU 0: 50 events, 3 KiB data
Total: 50 events (dropped 0), 3 KiB data
[root@mysqldb1 ~]# blkparse -i sdc1.blktrace.0
Input file sdc1.blktrace.0 added
8,32 0 1 0.000000000 4401 A FWFSM 1049672 + 2 <- (8,33) 1047624
8,33 0 2 0.000001830 4401 Q WSM 1049672 + 2 [kworker/0:1H]
8,33 0 3 0.000006576 4401 G WSM 1049672 + 2 [kworker/0:1H]
8,33 0 4 0.000007516 4401 P N [kworker/0:1H]
8,33 0 5 0.000009001 4401 I WSM 1049672 + 2 [kworker/0:1H]
8,33 0 6 0.000009865 4401 U N [kworker/0:1H] 1
8,33 0 7 0.000010825 4401 D WSM 1049672 + 2 [kworker/0:1H]
8,33 0 8 0.000271593 0 C WSM 1049672 + 2 [0]
8,32 0 9 29.999396763 2965 A WM 2112 + 16 <- (8,33) 64
8,33 0 10 29.999399134 2965 Q WM 2112 + 16 [xfsaild/sdc1]
8,33 0 11 29.999404432 2965 G WM 2112 + 16 [xfsaild/sdc1]
8,33 0 12 29.999406166 2965 P N [xfsaild/sdc1]
8,33 0 13 29.999407821 2965 I WM 2112 + 16 [xfsaild/sdc1]
8,33 0 14 29.999409058 2965 U N [xfsaild/sdc1] 1
8,33 0 15 29.999410349 2965 D WM 2112 + 16 [xfsaild/sdc1]
8,33 0 16 29.999778179 0 C WM 2112 + 16 [0]
8,32 0 17 31.374864114 3664 A WS 4256 + 16 <- (8,33) 2208
8,33 0 18 31.374865091 3664 Q WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
8,33 0 19 31.374866243 3664 G WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
8,33 0 20 31.374866536 3664 P N [ora_dbw0_enmote]
8,33 0 21 31.374867424 3664 I WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
8,33 0 22 31.374867676 3664 U N [ora_dbw0_enmote] 1
8,33 0 23 31.374868189 3664 D WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
8,33 0 24 31.374934458 0 C WS 4256 + 16 [0]
8,32 0 25 31.379428011 3674 A WS 2160 + 16 <- (8,33) 112
8,33 0 26 31.379429174 3674 Q WS 2160 + 16 [ora_ckpt_enmote]
8,33 0 27 31.379431163 3674 G WS 2160 + 16 [ora_ckpt_enmote]
8,33 0 28 31.379431820 3674 P N [ora_ckpt_enmote]
8,33 0 29 31.379433132 3674 I WS 2160 + 16 [ora_ckpt_enmote]
8,33 0 30 31.379433653 3674 U N [ora_ckpt_enmote] 1
8,33 0 31 31.379434122 3674 D WS 2160 + 16 [ora_ckpt_enmote]
8,33 0 32 31.379686376 0 C WS 2160 + 16 [0] ---表示写完成(complete)
8,32 0 33 59.999440028 4401 A FWFSM 1049674 + 2 <- (8,33) 1047626
8,33 0 34 59.999442910 4401 Q WSM 1049674 + 2 [kworker/0:1H]
8,33 0 35 59.999448871 4401 G WSM 1049674 + 2 [kworker/0:1H]
8,33 0 36 59.999450211 4401 P N [kworker/0:1H]
8,33 0 37 59.999451575 4401 I WSM 1049674 + 2 [kworker/0:1H]
8,33 0 38 59.999452445 4401 U N [kworker/0:1H] 1
8,33 0 39 59.999453333 4401 D WSM 1049674 + 2 [kworker/0:1H]
8,33 0 40 59.999724225 0 C WSM 1049674 + 2 [0]
CPU0 (sdc1):
Reads Queued: 0, 0KiB Writes Queued: 5, 26KiB
Read Dispatches: 0, 0KiB Write Dispatches: 5, 26KiB
Reads Requeued: 0 Writes Requeued: 0
Reads Completed: 0, 0KiB Writes Completed: 5, 26KiB
Read Merges: 0, 0KiB Write Merges: 0, 0KiB
Read depth: 0 Write depth: 1
IO unplugs: 5 Timer unplugs: 0
Throughput (R/W): 0KiB/s / 0KiB/s
Events (sdc1): 40 entries
Skips: 0 forward (0 - 0.0%)
这里我们把上述dbw0进程的几行信息拿出来单独分析说明:
8,33 0 18 31.374865091 3664 Q WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
8,33 0 19 31.374866243 3664 G WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
8,33 0 20 31.374866536 3664 P N [ora_dbw0_enmote]
8,33 0 21 31.374867424 3664 I WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
8,33 0 22 31.374867676 3664 U N [ora_dbw0_enmote] 1
8,33 0 23 31.374868189 3664 D WS 4256 + 16 [ora_dbw0_enmote] ---注意这里
其中第7列表示事件类型:
Q queued I/O进入block layer,将要被request代码处理(即将生成IO请求)
G get request I/O请求(request)生成,为I/O分配一个request 结构体。
M back merge 之前已经存在的I/O request的终止block号,和该I/O的起始block号一致,就会合并。也就是向后合并
F front merge 之前已经存在的I/O request的起始block号,和该I/O的终止block号一致,就会合并。也就是向前合并
I inserted I/O请求被插入到I/O scheduler队列
S sleep 没有可用的request结构体,也就是I/O满了,只能等待有request结构体完成释放
P plug 当一个I/O入队一个空队列时,Linux会锁住这个队列,不处理该I/O,这样做是为了等待一会,看有没有新的I/O进来,可以合并
U unplug 当队列中已经有I/O request时,会放开这个队列,准备向磁盘驱动发送该I/O。
这个动作的触发条件是:超时(plug的时候,会设置超时时间);或者是有一些I/O在队列中(多于1个I/O)
D issued I/O将会被传送给磁盘驱动程序处理
C complete I/O处理被磁盘处理完成。
第8列的W表示write,S表示sync。
第9列表示 磁盘起始块+操作的块的数量
第10列表示 进程名名称
因此我们这里重点看第8列就行了;同时确认第7列的状态为D即可。 那么这一行的具体信息为:4256 + 16
其中4256是起始Block号,后面表示操作的Block数量。甚至我们还能看到具体的block 范围:
[root@mysqldb1 ~]# btt -i sdc1.blktrace.0 -B sdc1.off
.......
[root@mysqldb1 ~]# cat sdc1.off_8,33_w.dat
1614.232741923 1049672 1049674
1644.232141447 2112 2128
1645.607599287 4256 4272 ---这里即是dbw0写的block开始位置和结束位置;分别是4256和4276;两者相减就是16
1645.612165220 2160 2176
1674.232184431 1049674 1049676
这里为16,表上实际上os层完成了16个IO操作。比较怪异了。。。。。。。
我们的dbw0进程实际上只写了一个8k的block,主机底层为什么完成了16次IO操作? 这是因为我这里测试环境磁盘的物理扇区是512.
[root@mysqldb1 ~]# cat /sys/block/sdc/queue/physical_block_size
512
[root@mysqldb1 ~]# cat /sys/block/sdc/queue/logical_block_size
512
[root@mysqldb1 ~]#
那么这里其实还有个小疑问;扇区虽然是512,但是并不代表8k的数据需要写16次;这里的16其实是表示os层写了16个block;其中每个block是512.
但是这里写16个block;可以是一次原子写或者2次或者16次? 实际上查看blktrace的数据是可以进一步验证的:
[root@mysqldb1 ~]# cat 8,33_iops_fp.dat
1614 1
1644 1
1645 2 --- 这里2 表示IO 个数
1674 1
换句话说dbw0进程写8k数据,os层实际上写入了16个block,一共进行了2次IO操作;也就是2次原子写。那么每次写入就是4k。
所以。。。。。。本质上来讲,Oracle这里的8k在Linux 内核层面来看其实是2次原子写操作完成的。如果2次操作只完成了1次,主机就crash了;怎么办?
最后简单的总结一下:
Oracle 中不是没有partial write的问题;而是Oracle 本身居然很多数据块的完整校验机制;写失败就直接回滚掉了,甚至在Oracle 11gR2版本还有写数据文件发现IO异常直接crash 实例的特性(当然是为了更好的保护数据库的完整性)。