HTTP服务器总结
简单HTTP服务器总结
对着简历总结吧:
liunx环境下的简单http服务器
支持http1.1
支持get方法
支持长连接
使用epoll
使用线程池处理用户请求
服务端程序评价标准:
因为刚学网络编程不久,可能理解的不够深,我觉得有三个指标可以反映一个服务端程序的好坏
1 高可用性(能不提就不提吧):
是指系统无中断执行其功能的能力,代表了系统的可用性程度
体现下面几个方面:
1) 对异常情况的处理,仅在正常情况下运行是远远不够的
2) (容错能力)当个别机器出错时,系统还能正常的运行
3) 无需过多的人工干预,7*24都能工作,遇错自动调整,不必投入人力时刻关注程序的状态
2 高并发性:
是指同一时间内可以处理多个用户的请求,使得每个用户得到较快的响应
3 响应时间
指用户发出请求到收到响应的时间,越短越好
线程池:
首先我们说一下为什么要使用线程池,对于我们的服务端程序来说,如果每来一个新的客户请求我们
就pthread_create一个新的进程,那么当这样不仅会因为频繁的创建和销毁线程,而带来额外的系统开销,而且当线程数量过多的时候,还会容易造成调度上的太多花费。
我们使用线程池,就可以直接创建我们想要的线程数量,可以避免创建过多的线程所带来的额外的花销
线程池我用的是半同步/半异步并发模式,也称为生产者消费者模式
为什么使用这种模式呢,这里介绍一下半同步半异步模式:
https://blog.csdn.net/cjfeii/article/details/17267487
首先为什么要使用这种模式呢,我们知道,同步程序虽然效率较低,当时编写简单,易于调试,
异步程序效率较高,但是编写起来比较复杂,难于调试,而对于像服务器程序这种即要求实时性,
又要求处理很多客户请求的程序,很适合,再加上半同步半异步本身就比较容易是实现
具体实现:
主要分为三个层次,同步层,异步层,队列层
同步层:
这一层的任务就是,监听新的请求,往队列层中添加新的请求任务,还可以处理新的tcp连接,关闭tcp连接等等
异步层
通过信号量和互斥锁,信号量代表队列中的任务数,互斥锁代表对队列的操作两个锁操作容易造成死锁,注意获取锁的顺序问题,然后线程竞争的获取任务
队列层
主要接受同步层的任务,然后异步层从队列层中取走任务
HA/HS(优点缺点要回来理解一下)
优点:
1 上层任务被简化,易于编程
2 不同层之间的通信被限定与一点中
3 在多处理器环境提高了任务处理的效率
缺点:
跨边界导致的性能消耗,这是因为同步控制,数据拷贝和上下文切换会过度地消耗资源。
上层任务缺少异步I/O的实现。
其他地方以及代码:
用了两个同步机制,互斥锁和信号量
信号量代表队列中的任务数量,sem_t sem, 典型的pv操作
wait当值大于零时,不阻塞,并且减少一,
post加一
当线程去取队列中的任务时,先wait一下,在lock,取走任务后unlock
几个注意的点,因为pthread_create中传递的函数必须要静态的,所以我们可以把work函数定义为static的,然后参数值为指向线程池的指针
这里我们线程池能处理的请求最大数量时10000,那么我们线程池的内存大概是10000*4byte
线程取出任务后然后启动处理
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include
#include
#include
#include
#include
#include
class sem
{
public:
sem()
{
if(sem_init(&m_sem,0,0)!=0){
throw std::exception();
}
}
~sem()
{
sem_destroy(&m_sem);
}
bool wait()
{
return sem_wait(&m_sem) == 0;
}
bool post()
{
return sem_post(&m_sem) == 0;
}
private:
sem_t m_sem;
};
class locker
{
public:
locker()
{
if(pthread_mutex_init(&m_mutex,NULL)!=0){
throw std::exception();
}
}
~locker()
{
pthread_mutex_destroy(&m_mutex);
}
bool lock()
{
return pthread_mutex_lock(&m_mutex)==0;
}
bool unlock()
{
return pthread_mutex_unlock(&m_mutex)==0;
}
private:
pthread_mutex_t m_mutex;
};
template
class threadpool
{
public:
threadpool(int thread_number = 8,int max_requests = 10000);
~threadpool();
bool append(T *request);
private:
static void* worker(void *args);
void run();
int m_thread_number;
int m_max_requests;
pthread_t* m_threads;
std::listm_workqueue;
locker m_queuelocker;
sem m_queuestat;
bool m_stop;
};
template
threadpool::threadpool(int thread_number,int max_requests)
{
m_thread_number = thread_number;
m_max_requests = max_requests;
m_threads = new pthread_t[thread_number];
assert(m_threads);
for(int i = 0;i
threadpool::~threadpool()
{
delete []m_threads;
m_stop = true;
}
template
bool threadpool::append(T* request)
{
m_queuelocker.lock();
if(m_workqueue.size()>m_max_requests)
{
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back(request);
m_queuelocker.unlock();
m_queuestat.post();
return true;
}
template
void * threadpool::worker(void *args)
{
threadpool* pool = (threadpool*) args;
pool->run();
return pool;
}
template
void threadpool::run()
{
while(!m_stop)
{
m_queuestat.wait();
m_queuelocker.lock();
if(m_workqueue.empty())
{
m_queuelocker.unlock();
continue;
}
T* request = m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlock();
if(!request)
{
continue;
}
request->process();
}
}
#endif
网络编程部分:
对于服务端对说,我们一般先注册信号处理函数,这里我们忽略了SIGPIPE信号,
这里讲一下SIGPIPE信号
当我们往一个已经关闭的socket连接write的时候,第一次会收到一个RST报文,第二次会收到一个SIGPIPE信号,默认行为是终止连接
再说一下RST报文,什么情况下会收到RST报文呢
https://blog.csdn.net/renrenhappy/article/details/5929581
RST报文是复位的意思,但是更准确的说法应该是,此连接不存在需要重新连接
第一种情况:
当我们连接一个端口不存在的或者端口未监听的情况下,TCP会收到RST报文
第二种情况:
异常终止一个连接,发送一个复位报文段而不是FIN来中途释放一个连接,这也称为异常释放。异常终止一个连接对应用程序来说有两个优点:(1)丢弃任何待发数据并立即发送复位报文段;(2)RST的接收方会区分另一端执行的是异常关闭还是正常关闭。
第三种情况:
检测半连接:当连接的一方异常终止时,另一方是不知道的,那么这时候向此连接发送数据,那么
对方会发送一个RST报文,表示连接已关闭
然后创建一个socke地址,这里是IPV4的socket地址SOCKADDR_IN,填写各字段,sin_family 为AF_INET 是IPv4 网络协议的套接字类型
然后填IP,这里ip地址我们要转换一下,将主机序转换为网络虚,字节序分为大端序列和小段序列,大端是指高位在底地址,这里用到inet_pton(AF_INET,ip,&addr.sin_addr)
然后我们创建一个socket连接socket(AF_INET,SOCK_STREAM,0) ,第一个参数代表,选择的通信协议族,这里选择AF_INET代表IPV4通信协议,第二个参数代表套接字的类型,主要有流式和数据包式,第三个代表用于指定某种协议的具体类型,大多数只有一种特定类型,指定为0即可
创建套接字后,我们需要绑定socket地址bind(fd,(sockaddr*)&address,sizeof(address));
然后就是listen函数了
https://blog.csdn.net/u010154760/article/details/45844037
第一个参数是使一个主动连接的socket的变为被动连接的socket
第二个参数是指定监听队列的大小,监听队列是用来维护那些已经完成的连接,但是服务器还来不及处理或者连接还未完成的连接
然后用epoll_create创建一时间表,epoll_create(int size) 现在不起作用
然后创建事件数组给后面的epoll_wait准备
将listenfd添加到epollfd中
这里使用了epoll_ctl(epollfd,EPOLL_CTL_ADD,fd,&event);
这里使用EPOLLONESHOT事件(后面详细介绍)
然后用EPOLL_WAIT监听端口,如果是listenfd就accep接受一个新的连接,并且添加到EPOLLFD中
如果是错误事件就关闭,如果可读,就读进来然后丢给队列层
,如果可写,就写
大概思路就是这样
下面介绍使用的API:
一个一个来吧除了上面介绍的
socket,bind,listen,然后就是accept了啊
介绍下accept吧:
函数用法
sockaddr_in address;
socklen_t len = sizeof(address);
int ret = accept(listenfd,(sockaddr*)&address,&len);
accept用于从监听队列中取出一个已完成的连接,如果没有则阻塞,
返回:若成功则为非负描述符,若出错则为-1
如果accept成功,那么其返回值是由内核自动生成的一个全新描述符,代表与客户端的TCP连接。一个服务器通常仅仅创建一个监听套接字,它在该服务器生命周期内一直存在。内核为每个由服务器进程接受的客户端连接创建一个已连接套接字。当服务器完成对某个给定的客户端的服务器时,相应的已连接套接字就被关闭。
接下来详细介绍一下epoll
https://yq.aliyun.com/articles/367908
epoll是为了处理大量句柄而改进的poll
只有三个系统调用
epoll_create, epoll_wait,epoll_ctl
epoll_create就没是什么好说的了,创建一个事件表
但是现在size参数已经没用了,因为以前使用hash表使用的,所以要初始化size,现在改用红黑树了
epoll_ctl是事件注册函数,动态的注册我们感兴趣的事件
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll_CTL_ADD EPOLL_CTL_MOD,EPOLL_CTL_DEL
几个事件宏:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLRDHUP : 表示对端关闭连接
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的(下面回详细讲解)
EPOLLONESHOT:最多触发一个事件,并且最多触发一次,所以相应的,每次触发完之后要重新注册
EPOLLHUP:表示关联的fd挂起了,epoll_wait会一直等待这个事件,所以一般没必要设置这个属性
这里使用EPOLLONESHOT的原因,主要是因为:
如果我们的一个线程正在处理一个连接上的请求,这个时候这个连接又来了一次请求,这个时候就造成了两个线程处理同一个连接
epoll_wait系统调用:
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
events是指内核将发生的事件复制到event数组中,maxevents是数组大小
timeout是最大等待时间,0,是立马返回,-1是一直阻塞下去
epoll优点
1 支持一个进程打开大数目的socket描述符(FD)
epoll支持更多的socket描述符,是文件描述符的上限,而select能监听的连接数量较少,只有2048个
2 效率不随着FD数量的上升而变慢
我们直到select和poll都是线性扫描所有的连接,这样的话如果不是有一部分不是处于活动状态中
那么效率是比较地的,而epoll是只对有事件发生的socket进行操作,这是因为只有有事件发生的连接会调用callback函数,但是如果活动连接较多,那么epoll的效率并不一定比select和poll高
3 使用mmap加速内核与用户空间的消息传递
使用mmap在用户态和内核态共享一块内存完成fd消息的传递,不需要额外的拷贝,效率很高
Epoll 工作模式
LT模式:Level Triggered水平触发
这个是缺省的工作模式。同时支持block socket和non-block socket。内核会告诉程序员一个文件描述符是否就绪了。如果程序员不作任何操作,内核仍会通知。也就是同一事件可能会通知多次
ET模式:Edge Triggered 边缘触发
是一种高速模式。仅当状态发生变化的时候才获得通知。这种模式假定程序员在收到一次通知后能够完整地处理事件,于是内核不再通知这一事件。注意:缓冲区中还有未处理的数据不算状态变化,所以ET模式下程序员只读取了一部分数据就再也得不到通知了,正确的用法是程序员自己确认读完了所有的字节
select、poll、epoll之间的区别
https://segmentfault.com/a/1190000003063859
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select将监视的文件描述符分为3类,读,写,异常,我们需要用FD_SET()添加,而且需要遍历我们注册的连接,看是否有事件发生,而且还要重新注册,select的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
struct pollfd {
int fd; /* file descriptor /
short events; / requested events to watch /
short revents; / returned events witnessed */
};
poll比select聪明一点,不用每次返回后重新注册,最大监听数量也比select多得多
但是也是用线性扫描的方法去查找哪些文件描述符有事件发生
从上面看,select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降
epoll
前面说了
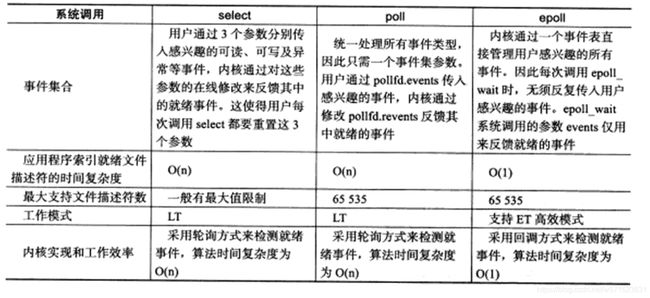
为什么要使用epoll:
1 能够监听的连接非常多,不像select一般只能支持1024个
2 不会因为文件描述符数量的增多而效率下降,select和poll 都是采用线性扫描的方式去检测就绪事件,而epoll是采用回调方式来检测就绪事件
send 函数
int send( SOCKET s, const char FAR *buf, int len, int flags );
不论是客户还是服务器应用程序都用send函数来向TCP连接的另一端发送数据。客户程序一般用send函数向服务器发送请求,而服务器则通常用send函数来向客户程序发送应答。
该函数的第一个参数指定发送端套接字描述符;
第二个参数指明一个存放应用程序要发送数据的缓冲区;
第三个参数指明实际要发送的数据的字节数;
第四个参数一般置0。
这里只描述同步Socket的send函数的执行流程。当调用该函数时,
(1)send先比较待发送数据的长度len和套接字s的发送缓冲的长度, 如果len大于s的发送缓冲区的长度,该函数返回SOCKET_ERROR;
(2)如果len小于或者等于s的发送缓冲区的长度,那么send先检查协议是否正在发送s的发送缓冲中的数据,如果是就等待协议把数据发送完,如果协议还没有开始发送s的发送缓冲中的数据或者s的发送缓冲中没有数据,那么send就比较s的发送缓冲区的剩余空间和len
(3)如果len大于剩余空间大小,send就一直等待协议把s的发送缓冲中的数据发送完
(4)如果len小于剩余 空间大小,send就仅仅把buf中的数据copy到剩余空间里(注意并不是send把s的发送缓冲中的数据传到连接的另一端的,而是协议传的,send仅仅是把buf中的数据copy到s的发送缓冲区的剩余空间里)。
如果send函数copy数据成功,就返回实际copy的字节数,如果send在copy数据时出现错误,那么send就返回SOCKET_ERROR;如果send在等待协议传送数据时网络断开的话,那么send函数也返回SOCKET_ERROR。
要注意send函数把buf中的数据成功copy到s的发送缓冲的剩余空间里后它就返回了,但是此时这些数据并不一定马上被传到连接的另一端。如果协议在后续的传送过程中出现网络错误的话,那么下一个Socket函数就会返回SOCKET_ERROR。(每一个除send外的Socket函数在执 行的最开始总要先等待套接字的发送缓冲中的数据被协议传送完毕才能继续,如果在等待时出现网络错误,那么该Socket函数就返回 SOCKET_ERROR)
注意:在Unix系统下,如果send在等待协议传送数据时网络断开的话,调用send的进程会接收到一个SIGPIPE信号,进程对该信号的默认处理是进程终止。
通过测试发现,异步socket的send函数在网络刚刚断开时还能发送返回相应的字节数,同时使用select检测也是可写的,但是过几秒钟之后,再send就会出错了,返回-1。select也不能检测出可写了。
recv函数:
https://blog.csdn.net/henry115/article/details/7054603
int recv( SOCKET s, char FAR *buf, int len, int flags);
不论是客户还是服务器应用程序都用recv函数从TCP连接的另一端接收数据。该函数的第一个参数指定接收端套接字描述符;
第二个参数指明一个缓冲区,该缓冲区用来存放recv函数接收到的数据;
第三个参数指明buf的长度;
第四个参数一般置0。
这里只描述同步Socket的recv函数的执行流程。当应用程序调用recv函数时,
(1)recv先等待s的发送缓冲中的数据被协议传送完毕,如果协议在传送s的发送缓冲中的数据时出现网络错误,那么recv函数返回SOCKET_ERROR,
(2)如果s的发送缓冲中没有数据或者数据被协议成功发送完毕后,recv先检查套接字s的接收缓冲区,如果s接收缓冲区中没有数据或者协议正在接收数据,那么recv就一直等待,直到协议把数据接收完毕。当协议把数据接收完毕,recv函数就把s的接收缓冲中的数据copy到buf中(注意协议接收到的数据可能大于buf的长度,所以 在这种情况下要调用几次recv函数才能把s的接收缓冲中的数据copy完。recv函数仅仅是copy数据,真正的接收数据是协议来完成的),
recv函数返回其实际copy的字节数。如果recv在copy时出错,那么它返回-1;如果recv函数在等待协议接收数据时网络中断了,那么它返回0。
http1.1
https://juejin.im/entry/596624f75188250d7d12d6a5
http协议真是个复杂的东西,往深了问我也不会啊,好菜啊没有offer了(QAQ)
只能写一些大概了啊
首先http协议,超文本传输协议,是服务器到本地客户端用来传输超文本的协议
先说一哈http过程吧,客户端与服务器建立连接,然后发送http请求,服务器收到请求后,作出响应的处理,然后发送响应报文,然后如果不是长连接的话就断开连接,是的话保持连接
http报文格式:
请求报文:
请求行:方法空格url空格协议号/r/n
请求头
/r/n
报文主体
响应报文:
响应行:协议空格响应码空格描述/r/n
响应头
/r/n
报文主体
首部字段分为
通用字段,请求字段,响应字段,实体字段
这里我只处理了host字段,Content-Length字段,connection字段
host字段就是请求字段http1.1中要求必须有这个字段,connection字段是通用字段,Content-Length是实体字段
状态码:
200 成功
204 No Content
301 永久重定性
302 临时性重定性
404 没找到
403 莫的权限
400 语法错误
500 表明服务器端在执行请求时发生了错误。也可能是 Web 应用存在的 bug 或某些临时的故障
503 服务器很忙,超负债状态
1.0 与1.1的区别
https://blog.csdn.net/hguisu/article/details/8608888
1 1.1中默认使用长连接,而http1.0默认的是短连接
2 Host域
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。此外,服务器应该接受以绝对路径标记的资源请求。
HTTP1.1在Request消息头里头多了一个Host域,比如:
GET /pub/WWW/TheProject.html HTTP/1.1
Host: www.w3.org
HTTP1.0则没有这个域。
可能HTTP1.0的时候认为,建立TCP连接的时候已经指定了IP地址,这个IP地址上只有一个host。
由于HTTP 1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点,这样就无法使用WEB服务器在同一个IP地址和端口号上配置多个虚拟WEB站点。在HTTP 1.1中增加Host请求头字段后,WEB浏览器可以使用主机头名来明确表示要访问服务器上的哪个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
3 100状态码
另外一种浪费带宽的情况是请求消息中如果包含比较大的实体内容,但不确定服务器是否能够接收该请求(如是否有权限),此时若贸然发出带实体的请求,如果被拒绝也会浪费带宽。
HTTP/1.1加入了一个新的状态码100(Continue)。客户端事先发送一个只带头域的请求,如果服务器因为权限拒绝了请求,就回送响应码401(Unauthorized);如果服务器接收此请求就回送响应码100,客户端就可以继续发送带实体的完整请求了。注意,HTTP/1.0的客户端不支持100响应码。但可以让客户端在请求消息中加入Expect头域,并将它的值设置为100-continue。
100 (Continue) 状态代码的使用,允许客户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。
客户端在Request头部中包含
Expect: 100-continue
Server看到之后呢如果回100 (Continue) 这个状态代码,客户端就继续发requestbody。
这个是HTTP1.1才有的
怎么实现GET方法:
当我们获取url后,用stat函数获取文件信息,如果不存在就返回404,然后根据stat的st_mode函数去判断文件读写权限,如果是一个目录文件S_ISDIR判断是否为目录文件,如果是的话就返回400
没有ISROTH权限就返回403 成功的话就open然后返回