Linux 页交换
目录
1. 重要数据结构说明 1
2. 交换分区 2
2.1 创建交换分区 2
2.2 激活交换区 2
3. Swap out 4
3.1分配槽位 4
3.2添加一页到交换缓存 7
3.3交换缓存 8
4. Swap in 9
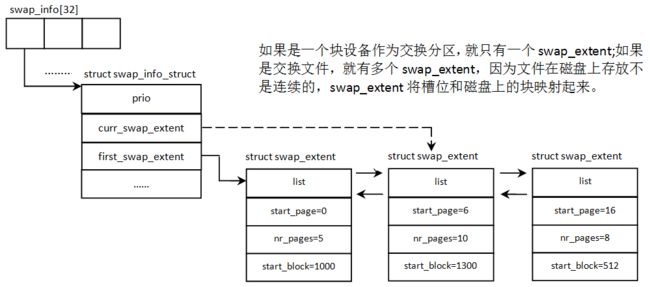
1 重要数据结构说明
| struct swap_info_struct |
|
| unsigned long flags |
用于标识交换分区的状态 |
| signed short prio |
交换分区可能存在多个,他们按优先级挂到全局链表swap_active_head中 |
| struct plist_node list |
用于挂到全局链表swap_active_head中 |
| struct plist_node avail_list |
交换分区活动的时候用于挂到全局链表swap_avail_head中 |
| signed char type |
交换分区在数组swap_info[type]中的位置 |
| unsigned int max |
交换区包含的页数 |
| unsigned char *swap_map |
记录每个槽位引用计数的数组,每个页占用一个位置 |
| unsigned int lowest_bit |
第一个可用的槽位 |
| unsigned int highest_bit |
最后一个可用的槽位,第一个到最后一个可用槽位之间也可能存在被占用的槽位,但是第一个之前和最后一个之后没有空闲的槽位 |
| unsigned int pages |
交换区中可用的槽位数一个槽位4k大小 |
| unsigned int inuse_pages |
被占用的槽位数 |
| unsigned int cluster_next |
当前聚集中下一个可用的槽位 |
| unsigned int cluster_nr |
当前聚集中可用槽位数 |
| struct swap_extent *curr_swap_extent |
槽位和块设备上块号映射表 |
| struct swap_extent first_swap_extent |
第一个映射区 |
| struct block_device *bdev |
交换区对应的块设备 |
| struct file *swap_file |
指向交换分区打开的的file结构 |
2 交换分区
2.1 创建交换分区
命令mkswap可以用于创建一个交换分区,该命令的工作就是向一个分区或者一个文件中写入交换分区信息,如下:
union swap_header {
struct {
char reserved[PAGE_SIZE - 10]; //总共一页大小
char magic[10]; //交换区标识“SWAPSPACE2”
} magic;
struct {
char bootbits[1024]; //如果交换分区位于磁盘起始处,这里是预留给启动装载程序
__u32 version;//交换区版本号
__u32 last_page;//最后一页的编号
__u32 nr_badpages;//不可用页的数目
unsigned char sws_uuid[16];
unsigned char sws_volume[16];
__u32 padding[117];
__u32 badpages[1];//不可用页编号表
} info;
};下面是android系统的一个mkswap命令实现源码:
external/toybox/toys/other/mkswap.c
void mkswap_main(void)
{
int fd = xopen(*toys.optargs, O_RDWR), pagesize = sysconf(_SC_PAGE_SIZE);
off_t len = fdlength(fd);
unsigned int pages = (len/pagesize)-1, *swap = (unsigned int *)toybuf;
swap[0] = 1;//交换分区的版本号
swap[1] = pages; //最后一个页编号
xlseek(fd, 1024, SEEK_SET);
xwrite(fd, swap, 129*sizeof(unsigned int));
xlseek(fd, pagesize-10, SEEK_SET);
xwrite(fd, "SWAPSPACE2", 10); //将交换分区标识"SWAPSPACE2"写入最后10个字节
fsync(fd);
}2.2 激活交换区
命令swapon用于激活交换分区,系统也提供了一个对应的系统调用swapon, 它最要的工作是:1)分配交换分区管理结构swap_info_struct ;2)读出交换分区信息;3)初始化swap_info_struct结构和建立swap_extent;4)初始化交换缓存swapper_spaces;5)更新total_swap_pages以及添加swap_info_struct到全局链表swap_avail_head和swap_active_head上。
SYSCALL_DEFINE2(swapon, const char __user *, specialfile, int, swap_flags)
{
struct swap_info_struct *p;
struct filename *name;
struct file *swap_file = NULL;
struct address_space *mapping;
int prio;
int error;
union swap_header *swap_header;
int nr_extents;
sector_t span;
unsigned long maxpages;
unsigned char *swap_map = NULL;
struct swap_cluster_info *cluster_info = NULL;
unsigned long *frontswap_map = NULL;
struct page *page = NULL;
struct inode *inode = NULL;
......
p = alloc_swap_info(); //分配交换分区管理结构swap_info_struct
if (IS_ERR(p))
return PTR_ERR(p);
name = getname(specialfile); //交换分区/文件路劲
swap_file = file_open_name(name, O_RDWR|O_LARGEFILE, 0); //打开交换分区/文件
p->swap_file = swap_file;
mapping = swap_file->f_mapping;
inode = mapping->host;
......
//读取交换分区第一个page的数据,其中包含前面mkswap写入的信息
page = read_mapping_page(mapping, 0, swap_file);
if (IS_ERR(page)) {
error = PTR_ERR(page);
goto bad_swap;
}
swap_header = kmap(page);
//识别交换分区特征标识和解析交换分区信息存放到swap_header中
maxpages = read_swap_header(p, swap_header, inode);
if (unlikely(!maxpages)) {
error = -EINVAL;
goto bad_swap;
}
// maxpages为交换分区包含的大小(单位为页不是块),下面为每个页分配一个槽位,用于记录交换页的状态,引用计数(多进程共享)等等。
swap_map = vzalloc(maxpages);
if (!swap_map) {
error = -ENOMEM;
goto bad_swap;
}
......
//初始化swap_info_struct结构和建立swap_extent链表
nr_extents = setup_swap_map_and_extents(p, swap_header, swap_map,
cluster_info, maxpages, &span);
if (unlikely(nr_extents < 0)) {
error = nr_extents;
goto bad_swap;
}
......
//初始化swapper_spaces,也就是address_space,用于管理交换缓存,一个交换缓存管理64M大小空间,根据maxpages计算需要多少个交换缓存
error = init_swap_address_space(p->type, maxpages);
mutex_lock(&swapon_mutex);
prio = -1;//系统中可以有多个交换分区/文件,每个交换分区/文件有一个优先级
if (swap_flags & SWAP_FLAG_PREFER)
prio =
(swap_flags & SWAP_FLAG_PRIO_MASK) >> SWAP_FLAG_PRIO_SHIFT;
//更新total_swap_pages以及添加swap_info_struct到全局链表swap_avail_head和swap_active_head上。
enable_swap_info(p, prio, swap_map, cluster_info, frontswap_map);
......
return error;
}

3 Swap out
页换出的流程如下: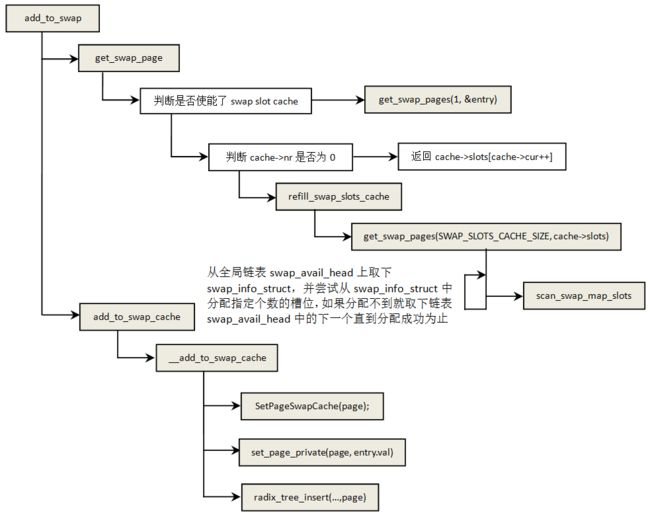
页换出主要做了两件事:1)为即将交换出去的页分配一个槽位;2)将页添加到交换缓存中。
页写入到交换分区是由内存回收流程来做的,后续在讲内存回收的文章中再细讲。
3.1分配槽位
在做进一步讲解逻辑之前先了解两个逻辑概念:聚集、slots cache。
聚集:
一个聚集包含SWAPFILE_CLUSTER(256)个连续的槽位,在分配槽位的时候总是尝试到当前聚集中去分配,如果没有,就尝试重新查找一个新的聚集,然后从新的聚集中分配,如果交换分区中找不到256个连续的槽位就扫描整个在交换分区尝试找到一个空闲的槽位。聚集没有单独的管理结构,与其相关的字段在结构体swap_info_struct中如下:
struct swap_info_struct {
……
unsigned int cluster_next; //聚集中下一个空闲的槽位
unsigned int cluster_nr; //聚集中空闲槽位个数
……
};slots cache:
可能存在多个CPU上的进程同时尝试分配槽位,为避免竞争提高效率定义了一个每CPU变量swp_slots,用于槽位缓存,一个缓存中可以缓存SWAP_SLOTS_CACHE_SIZE(64)个空闲槽位。分配槽位的时候先尝试从所在CPU对应的槽位缓存中去取空闲的槽位,如果缓存中没有空闲槽位就从交换分区中去补充一批SWAP_BATCH空闲槽位到缓存中。
static DEFINE_PER_CPU(struct swap_slots_cache, swp_slots);
分配槽位逻辑:
函数get_swap_page是分配槽位的接口。
swp_entry_t get_swap_page(void)
{
swp_entry_t entry, *pentry;
struct swap_slots_cache *cache;
cache = raw_cpu_ptr(&swp_slots);
entry.val = 0;
if (check_cache_active()) {//如果使能槽位缓存就尝试冲缓存中分配
mutex_lock(&cache->alloc_lock);
if (cache->slots) {
repeat:
if (cache->nr) {//如果缓存中有空闲槽位就直接从缓存中获取一个槽位
pentry = &cache->slots[cache->cur++];
entry = *pentry;
pentry->val = 0;
cache->nr--;//空闲槽位数减一
} else {
if (refill_swap_slots_cache(cache)) //如果缓存中没有空闲槽位就补充一批SWAP_BATCH个
goto repeat;
}
}
mutex_unlock(&cache->alloc_lock);
if (entry.val)
return entry;//返回槽位的entry
}
get_swap_pages(1, &entry); //如果没有使能槽位缓存就直接从交换分区中获取
return entry;
}前面的函数refill_swap_slots_cache也会调用到函数get_swap_pages,前面两处不同的是传入的分配个数一个是SWAP_BATCH(64)个,一个是1 。函数get_swap_pages又进一步调用函数scan_swap_map_slots来实现槽位分配:
static int scan_swap_map_slots(struct swap_info_struct *si,
unsigned char usage, int nr,
swp_entry_t slots[])
{
struct swap_cluster_info *ci;
unsigned long offset;
unsigned long scan_base;
unsigned long last_in_cluster = 0;
int latency_ration = LATENCY_LIMIT;
int n_ret = 0;
if (nr > SWAP_BATCH)//一次不能分配超过SWAP_BATCH个槽位
nr = SWAP_BATCH;
si->flags += SWP_SCANNING;
scan_base = offset = si->cluster_next;
......
if (unlikely(!si->cluster_nr--)) {
if (si->pages - si->inuse_pages < SWAPFILE_CLUSTER) {
si->cluster_nr = SWAPFILE_CLUSTER - 1;
goto checks;//如果交换分区中剩余的槽位不足以分配一个聚集,就跳过直接扫描剩余的槽位
}
spin_unlock(&si->lock);
scan_base = offset = si->lowest_bit; // lowest_bit指向第一个空闲的槽位
last_in_cluster = offset + SWAPFILE_CLUSTER - 1;
// highest_bit保存的是最后一个槽位,下面循环尝试找到SWAPFILE_CLUSTER个连续槽位
for (; last_in_cluster <= si->highest_bit; offset++) {
if (si->swap_map[offset])//不为0表示已经被占用,last_in_cluster后移
last_in_cluster = offset + SWAPFILE_CLUSTER;
else if (offset == last_in_cluster) {//相等表示找到SWAPFILE_CLUSTER个连续槽位
spin_lock(&si->lock);
offset -= SWAPFILE_CLUSTER - 1;
si->cluster_next = offset;//设置聚集中第一个空闲槽位
si->cluster_nr = SWAPFILE_CLUSTER - 1;
goto checks;
}
}
offset = scan_base;//如果没能成功分配一个聚集就重新扫描,希望分配一个单独的槽位
spin_lock(&si->lock);
si->cluster_nr = SWAPFILE_CLUSTER - 1;
}
checks:
……
if (!(si->flags & SWP_WRITEOK))
goto no_page;
if (!si->highest_bit)
goto no_page;
if (offset > si->highest_bit)
scan_base = offset = si->lowest_bit;
//如果可用槽位数不到总槽位数的一半就尝试回收部分槽位
if (vm_swap_full() && si->swap_map[offset] == SWAP_HAS_CACHE) {
int swap_was_freed;
swap_was_freed = __try_to_reclaim_swap(si, offset);
spin_lock(&si->lock);
if (swap_was_freed)
goto checks;
goto scan;
}
if (si->swap_map[offset]) {//判断si->swap_map[offset]这个位置是否是空的槽位
unlock_cluster(ci);
if (!n_ret)//如果还没有分配到空闲槽位就goto scan从新扫描交换分区
goto scan;
else
goto done;
}
si->swap_map[offset] = usage; //设置相关标记,表示这个槽位已经在使用中
inc_cluster_info_page(si, si->cluster_info, offset);
unlock_cluster(ci);
//下面是更新第一个或者最后一个空闲槽位
if (offset == si->lowest_bit)
si->lowest_bit++;
if (offset == si->highest_bit)
si->highest_bit--;
si->inuse_pages++;//增加槽位占用计数
if (si->inuse_pages == si->pages) {
si->lowest_bit = si->max;
si->highest_bit = 0;
spin_lock(&swap_avail_lock);
//如果没有空闲槽位了就将这个交换分区从链表swap_avail_head上删除
plist_del(&si->avail_list, &swap_avail_head);
spin_unlock(&swap_avail_lock);
}
si->cluster_next = offset + 1; //更新聚集中下一个槽位记录
slots[n_ret++] = swp_entry(si->type, offset); //将分配到的槽位的entry放到slots[]中后续返回
if ((n_ret == nr) || (offset >= si->highest_bit))//如果分配到指定个数nr个槽位就返回
goto done;
......
++offset;//增加偏移位置
if (si->cluster_nr && !si->swap_map[offset]) {
--si->cluster_nr;
goto checks; //继续分配空闲槽位直到获取到nr个槽位为止
}
done:
si->flags -= SWP_SCANNING;
return n_ret;
scan://前面没有分配到空闲槽位,下面扩大扫描范围查找
spin_unlock(&si->lock);
while (++offset <= si->highest_bit) {
if (!si->swap_map[offset]) {//如果找到一个空闲槽位就goto checks
spin_lock(&si->lock);
goto checks;
}
……
}
offset = si->lowest_bit;
while (offset < scan_base) {
if (!si->swap_map[offset]) {
spin_lock(&si->lock);
goto checks;
}
……
offset++;
}
spin_lock(&si->lock);
no_page:
si->flags -= SWP_SCANNING;
return n_ret;
}3.2添加一页到交换缓存
函数add_to_swap_cache用于添加一个页到交换缓存中,该函数的实际工作由__add_to_swap_cache完成。
int __add_to_swap_cache(struct page *page, swp_entry_t entry)
{
int error;
struct address_space *address_space;
get_page(page);
SetPageSwapCache(page); //设置flag PG_swapcache标识页处于交换缓存中
set_page_private(page, entry.val); //用page->private保存swap entry
address_space = swap_address_space(entry);
spin_lock_irq(&address_space->tree_lock);
//将页插入交换缓存的基数树中
error = radix_tree_insert(&address_space->page_tree,
swp_offset(entry), page);
if (likely(!error)) {
address_space->nrpages++; //更新缓存中缓存页计数
__inc_node_page_state(page, NR_FILE_PAGES);
INC_CACHE_INFO(add_total);
}
spin_unlock_irq(&address_space->tree_lock);
……
return error;
}3.3交换缓存
交换缓存和普通的页缓存一样都是由结构体address_space来管理,也实现了一个address_space_operations,用于执行页的操作。
static const struct address_space_operations swap_aops = {
.writepage = swap_writepage,
//直接调用__set_page_dirty_no_writeback来标记赃页,交换分区都是按页写入不是块
.set_page_dirty = swap_set_page_dirty,
#ifdef CONFIG_MIGRATION
.migratepage = migrate_page,
#endif
};系统中可能存在多个交换缓存,每个交换缓存管理16K个页(64M)。系统中可能存在多个交换分区或者交换文件,如果需要进行大量的内存交换,有多个交换缓存可以减少互斥带来的性能问题。下面是交换缓存的初始化:
int init_swap_address_space(unsigned int type, unsigned long nr_pages)
{
struct address_space *spaces, *space;
unsigned int i, nr;
//根据当前交换缓存的页数计算需要创建几个交换缓存
nr = DIV_ROUND_UP(nr_pages, SWAP_ADDRESS_SPACE_PAGES);
spaces = kvzalloc(sizeof(struct address_space) * nr, GFP_KERNEL);
if (!spaces)
return -ENOMEM;
for (i = 0; i < nr; i++) {//初始化交换缓存
space = spaces + i;
INIT_RADIX_TREE(&space->page_tree, GFP_ATOMIC|__GFP_NOWARN);
atomic_set(&space->i_mmap_writable, 0);
space->a_ops = &swap_aops;
mapping_set_no_writeback_tags(space);
spin_lock_init(&space->tree_lock);
}
nr_swapper_spaces[type] = nr;
rcu_assign_pointer(swapper_spaces[type], spaces);
return 0;
}4 Swap in
在页交换出去的时候会调用swp_entry_to_pte将swap entry转换为pte,填充到pte中,在进程再次访问到这个页的时候就会触发缺页异常,将页从交换分区中读入内存。swap entry转换为pte的编码如下:
/*
* Encode and decode a swap entry:
* bits 0-1: present (must be zero)
* bits 2-7: swap type
* bits 8-57: swap offset
* bit 58: PTE_PROT_NONE (must be zero)
*/缺页异常可能由很多中场景触发,页交换属于其中一种,do_swap_page实现将页换入的功能:
handle_pte_fault--->do_swap_page
int do_swap_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
int locked;
int exclusive = 0;
int ret = 0;
//根据pte转换为对应的swap entry
entry = pte_to_swp_entry(vmf->orig_pte);
......
page = lookup_swap_cache(entry); //根据entry查找看是否页存在交换缓存中(已经换入或者还没写出)
if (!page) {
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE, vma,
vmf->address);//如果页没有在交换缓存中就尝试从交换分区中读入,后面细讲
……
} else if (PageHWPoison(page)) {
……
}
swapcache = page;//此时页已经存在于交换缓存中了
……
//创建pte
pte = mk_pte(page, vma->vm_page_prot);
if ((vmf->flags & FAULT_FLAG_WRITE) && reuse_swap_page(page, NULL)) {
pte = maybe_mkwrite(pte_mkdirty(pte), vma);//添加PTE_WRITE属性
vmf->flags &= ~FAULT_FLAG_WRITE;
ret |= VM_FAULT_WRITE;
exclusive = RMAP_EXCLUSIVE;
}
//将新建的pte写入vmf->address对应的pte位置
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
vmf->orig_pte = pte;
if (page == swapcache) {
//创建反向映射
do_page_add_anon_rmap(page, vma, vmf->address, exclusive);
activate_page(page); //添加到active lru链表中
} else {
//为一个新页创建反向映射
page_add_new_anon_rmap(page, vma, vmf->address, false);
lru_cache_add_active_or_unevictable(page, vma);//将页添加到active或者unevictable lru链表中
}
swap_free(entry);//释放交换分区槽位
if (vmf->flags & FAULT_FLAG_WRITE) {
ret |= do_wp_page(vmf);//如果尝试些一个共享页,这里将拷贝一份数据并重新填写pte
if (ret & VM_FAULT_ERROR)
ret &= VM_FAULT_ERROR;
goto out;
}
……
}如果交换缓存中没有页就会调用函数swapin_readahead将页读入内存并插入交换缓存中
struct page *swapin_readahead(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr)
{
struct page *page;
unsigned long entry_offset = swp_offset(entry);//获取交换页的槽位offset
unsigned long offset = entry_offset;
unsigned long start_offset, end_offset;
unsigned long mask;
struct blk_plug plug;
//在读入交换分区的页的时候也顺便预读旁边的页,函数swapin_nr_pages是计算预读的页数
mask = swapin_nr_pages(offset) - 1;
if (!mask)
goto skip;
start_offset = offset & ~mask;
end_offset = offset | mask;
if (!start_offset) /* First page is swap header. */
start_offset++;
blk_start_plug(&plug);
for (offset = start_offset; offset <= end_offset ; offset++) {//逐页读取指定的页数
page = read_swap_cache_async(swp_entry(swp_type(entry), offset),
gfp_mask, vma, addr);//从交换区读入一页数据
if (!page)
continue;
if (offset != entry_offset)
SetPageReadahead(page); //设置预读标记
put_page(page);
}
blk_finish_plug(&plug);
lru_add_drain(); //将lru cache中的页刷到lru链表中去
skip:
return read_swap_cache_async(entry, gfp_mask, vma, addr); //从交换缓存中获取一个页
}
struct page *read_swap_cache_async(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr)
{
bool page_was_allocated;
//尝试从交换缓存中查找一个页,如果没找到就分配一个新页,并设置相关标志,然后将其插入交换缓存
struct page *retpage = __read_swap_cache_async(entry, gfp_mask,
vma, addr, &page_was_allocated);
//如果前面的接口中有分配新页,就将对应的数据从交换分区中读到新页中
if (page_was_allocated)
swap_readpage(retpage);
return retpage;
}
struct page *__read_swap_cache_async(swp_entry_t entry, gfp_t gfp_mask,
struct vm_area_struct *vma, unsigned long addr,
bool *new_page_allocated)
{
struct page *found_page, *new_page = NULL;
struct address_space *swapper_space = swap_address_space(entry);
int err;
*new_page_allocated = false;
do {
//尝试冲交换缓存中查找一个页,如果存在就直接返回
found_page = find_get_page(swapper_space, swp_offset(entry));
if (found_page)
break;
//如果该地址对应槽位已经没有进程引用了就直接返回NULL
if (!__swp_swapcount(entry) && swap_slot_cache_enabled)
break;
if (!new_page) {
new_page = alloc_page_vma(gfp_mask, vma, addr);//分配一个新页
if (!new_page)
break;
}
......
err = swapcache_prepare(entry);//增加SWAP_HAS_CACHE标识
......
__SetPageLocked(new_page);
__SetPageSwapBacked(new_page);
err = __add_to_swap_cache(new_page, entry);//将新页添加到交换缓存
if (likely(!err)) {
radix_tree_preload_end();
lru_cache_add_anon(new_page);//添加到对应的page list
*new_page_allocated = true;//标识有发生新页分配
return new_page;
}
......
swapcache_free(entry);
} while (err != -ENOMEM);
if (new_page)
put_page(new_page);
return found_page;
}